[논문리뷰] RealICU: Do LLM Agents Understand Long-Context ICU Data? A Benchmark Beyond Behavior Imitation
링크: 논문 PDF로 바로 열기
Part 1: 요약 본문
메타데이터
저자: Chengzhi Shen, Weixiang Shen, Tobias Susetzky, Chen, Chen, Jun Li, Yuyuan Liu, Xuepeng Zhang, Zhenyu Gong, Daniel Rueckert, Jiazhen Pan
1. Key Terms & Definitions (핵심 용어 및 정의)
- RealICU: 의료진의 사후 검토(hindsight)에 기반한 레이블을 사용하여, 임상적 정확성 측면에서 LLM 에이전트의 ICU 의사결정 능력을 평가하는 새로운 벤치마크.
- Oracle: Physician-validated LLM 기반 hindsight annotator로, 수동 주석이 어려운 대규모 ICU 데이터를 효율적으로 레이블링하기 위해 사용됨.
- ICU-Evo: 구조화된 메모리(structured memory) 시스템을 통해 긴 ICU 데이터 스트림에 걸쳐 환자 상태를 추적하고 임상적 추론을 수행하는 에이전트 프레임워크.
- Red Flag Actions: 환자의 생리적 상태나 임상 경과에 비추어 볼 때 잠재적으로 해를 끼칠 수 있어 회피해야 하는 고위험 임상 행위.
- Recall-Safety Tradeoff: 임상 권장 사항의 Recall을 높이려 할 때, 의도치 않게 잠재적으로 위험한 처방(Red Flag Actions)의 비율이 증가하는 현상.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 ICU 벤치마크들이 임상 의사결정을 단순한 정적 문제로 치부하거나, 과거 임상 기록을 그대로 정답으로 간주하는 'Behavior Imitation' 오류에 빠져 있다는 점을 지적한다. 이러한 방식은 환자의 정보가 제한적인 상황에서 내려진 임상적 판단을 정답으로 강제함으로써, AI의 실제 추론 능력을 평가하기 어렵게 만든다 [Figure 1]. 또한, ICU 환경은 밀도 높은 시계열 데이터가 연속적으로 발생하는 환경으로, 기존의 단일 시점 예측 모델이나 정적 QA 모델로는 지속적인 Bedside 재평가 및 장기적인 환자 상태 추론을 평가하는 데 한계가 있다. 따라서 저자들은 hindsight-annotated 데이터셋을 구축하여 AI의 임상적 정확성을 객관적으로 측정하고자 한다 [Figure 2].

Figure 1 — ICU AI 코파일럿의 역할 및 작업 내용
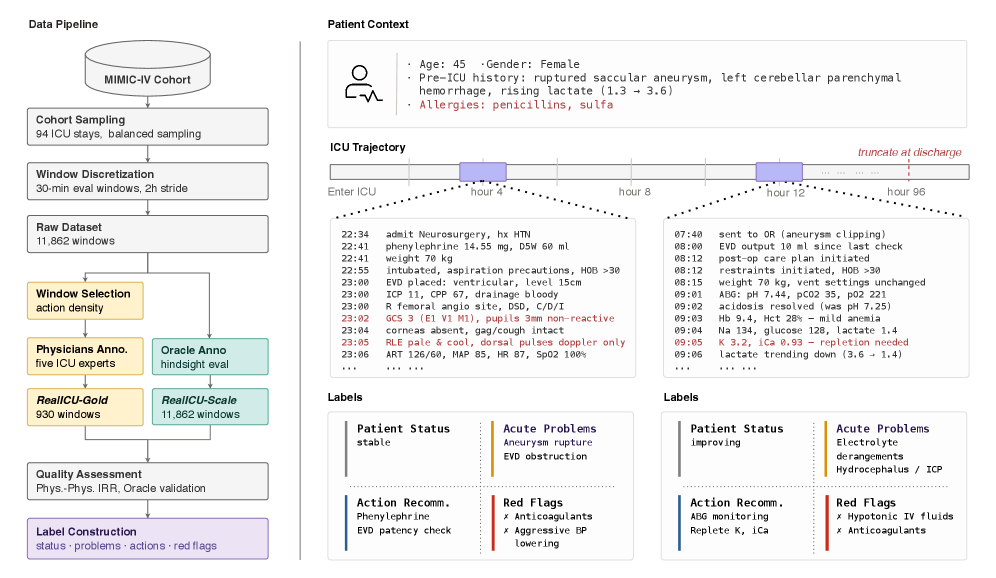
Figure 2 — RealICU 데이터 파이프라인 및 샘플
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 RealICU-Gold(전문가 주석 930개 윈도우)와 RealICU-Scale(Oracle을 통해 확장된 11,862개 윈도우)을 도입하여 ICU 의사결정 능력을 네 가지 핵심 과제(Patient Status, Acute Problems, Recommended Actions, Red Flags)로 평가한다. 이 문제들을 해결하기 위해 제안된 ICU-Evo 에이전트 시스템은 Working memory, Trend memory, Critical-event memory, Trajectory memory, Insight memory라는 5가지 구성 요소로 나뉜 구조화된 메모리를 활용한다 [Table 12]. 주요 실험 결과, ICU-Evo는 기존의 RAG 기반 모델 대비 Acute Problems Hit@5에서 최대 26.8점 이상의 유의미한 성능 향상을 보였다 [Table 2]. 그럼에도 불구하고, 전체적인 Red Flag HRR(Harmful Recommendation Rate)은 여전히 높게 유지되어 현재의 LLM 에이전트들이 임상 안전성을 완벽히 보장하지 못함을 시사한다 [Table 2]. 특히 ICU-Evo의 시간 경과에 따른 추론 성능은 장기 ICU 추적(최대 1,800시간)에서도 안정적인 성능을 유지하며 기존 Baselines을 상회하는 모습을 보였다 [Figure 3].
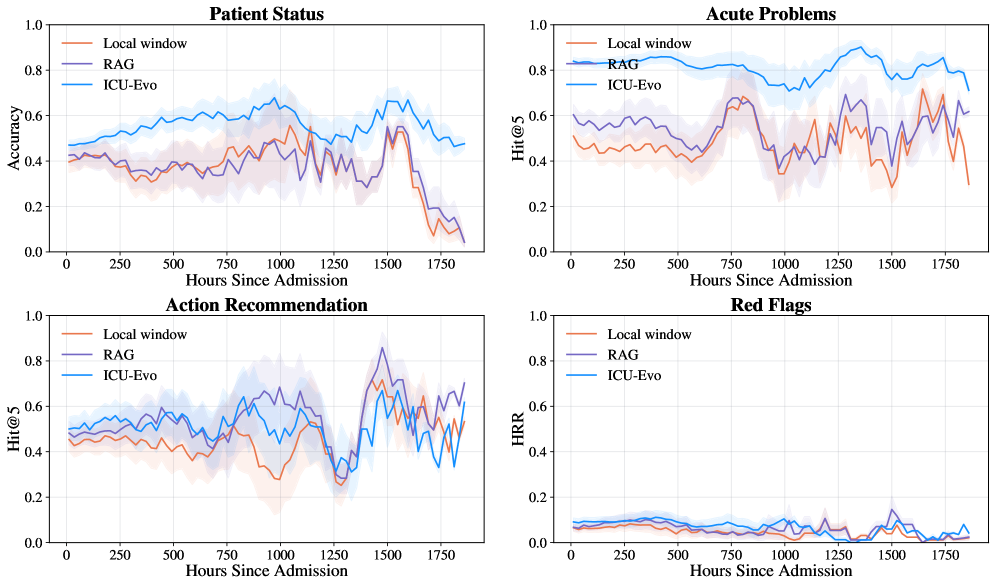
Figure 3 — RealICU-Scale상의 시간 성능 결과
4. Conclusion & Impact (결론 및 시사점)
본 연구는 RealICU를 통해 LLM 기반 ICU 에이전트가 직면한 두 가지 치명적인 실패 모드인 Recall-Safety Tradeoff와 Anchoring Bias를 명확히 규명하였다. 결론적으로 구조화된 메모리 아키텍처인 ICU-Evo는 긴 ICU 추적 상황에서 임상 추론 능력을 개선하는 데 효과적이지만, 메모리 증강만으로는 고위험군 임상 의사결정의 안전성을 확보하기에 부족함을 보여주었다. 이 연구는 사후 평가(hindsight evaluation) 프레임워크를 정립함으로써, 향후 고위험 순차적 의사결정 환경에서 AI가 단순한 행동 모방을 넘어 임상적 타당성을 갖추도록 발전하는 데 중요한 기틀을 마련하였다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Automating the Design of Embodied Agent Architectures
- [논문리뷰] When Classic Cache Policies Fail: Learning-Augmented Replacement for Semantic Retrieval Buffers
- [논문리뷰] Safety Testing LLM Agents at Scale: From Risk Discovery to Evidence-Grounded Verification
- [논문리뷰] Mastermind: Strategy-grounded Learning for Repository-Scale Vulnerability Reproduction
- [논문리뷰] SkillCoach: Self-Evolving Rubrics for Evaluating and Enhancing Agentic Skill-Use
Review 의 다른글
- 이전글 [논문리뷰] PresentAgent-2: Towards Generalist Multimodal Presentation Agents
- 현재글 : [논문리뷰] RealICU: Do LLM Agents Understand Long-Context ICU Data? A Benchmark Beyond Behavior Imitation
- 다음글 [논문리뷰] Results and Retrospective Analysis of the CODS 2025 AssetOpsBench Challenge
댓글