[논문리뷰] From Context to Skills: Can Language Models Learn from Context Skillfully?
링크: 논문 PDF로 바로 열기
저자: Shuzheng Si, Haozhe Zhao, Yu Lei, Qingyi Wang, Dingwei Chen, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Context Learning: 모델의 사전 학습(Pre-training) 범위를 벗어난 복잡한 맥락(Context)을 직접 학습하여 관련 지식을 추론하고 과제를 해결하는 능력.
- Inference-time Skill Augmentation: 추론 단계에서 맥락 내의 규칙과 절차를 자연어 형태의 'Skills'로 추출하여 모델의 시스템 프롬프트에 추가함으로써 성능을 향상시키는 방법론.
- Ctx2Skill: 외부 피드백이나 인간의 개입 없이, 다중 에이전트(Multi-agent) 자가 학습(Self-play)을 통해 맥락 특화 스킬을 자율적으로 발견, 정제, 선택하는 프레임워크.
- Adversarial Collapse: 자기 학습 과정에서 Challenger 에이전트가 지나치게 극단적인 과제를 생성하고 Reasoner 에이전트가 이에 과적합(Over-specialized)되어 스킬이 중복 및 퇴보하는 현상.
- Cross-time Replay Mechanism: 자가 학습 중에 수집된 대표적 과제들을 활용하여, 여러 스킬 후보군 중 가장 일반화 성능이 뛰어난 것을 선택하는 기법.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM이 pre-training 과정에서 학습하지 않은 복잡한 맥락을 효과적으로 이해하고 추론하는 능력이 부족하다는 문제를 해결하고자 한다. 특히 실제 업무 환경에서는 긴 문서나 기술적으로 조밀한 맥락을 처리해야 하는데, 기존 연구들은 수동적인 스킬 주석(Manual Annotation)에 의존하거나, 자동화된 스킬 구축을 위한 외부 피드백(Execution Feedback)이 부족하다는 한계를 가진다. 이러한 제약은 context learning 시나리오에서 자동화된 파이프라인 적용을 불가능하게 만든다. 따라서 저자들은 인간의 감독 없이도 복잡한 맥락에서 재사용 가능한 스킬을 스스로 발견하고 진화시키는 자율적 프레임워크의 필요성을 제기한다 [Figure 1].
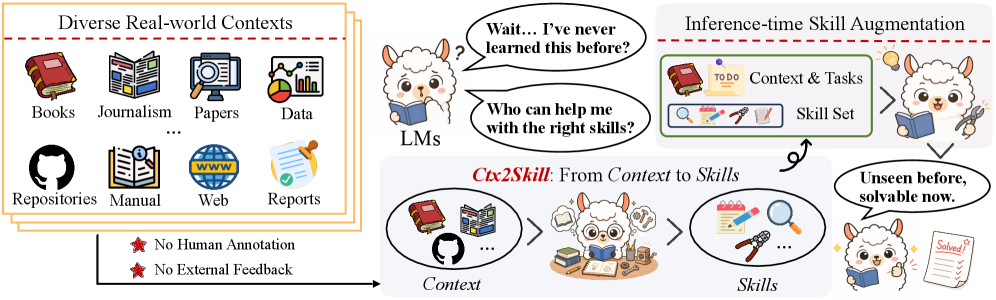
Figure 1 — Ctx2Skill 개념도
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Ctx2Skill 프레임워크를 제안하며, 이는 challenger 에이전트가 과제와 rubrics를 생성하고 reasoner 에이전트가 이를 해결하며, neutral judge 에이전트가 결과를 평가하는 self-play loop를 핵심으로 한다 [Figure 2]. 실패한 과제는 reasoner의 proposer/generator 쌍에 의해 스킬 업데이트로 연결되고, 성공한 과제는 challenger의 전략 강화에 활용되어 adversarial 압력을 유지한다. 학습 중 발생할 수 있는 adversarial collapse를 방지하기 위해 cross-time replay mechanism을 통해 가장 generalizable한 스킬셋을 선택한다. 실험 결과, Ctx2Skill은 CL-bench의 4개 과제 영역에서 모든 backbone 모델의 성능을 향상시켰다. 구체적으로 GPT-4.1의 solving rate를 11.1%에서 16.5%로, GPT-5.1의 경우 21.2%에서 25.8%로 상승시켰으며, 이는 단일 패스 프롬프팅이나 기존의 AutoSkill4Doc 베이스라인보다 우수한 정량적 성과를 보여준다 [Table 1]. 또한, 질적 평가에서도 faithfulness와 clarity 측면에서 최고 점수를 획득하였다 [Table 2].
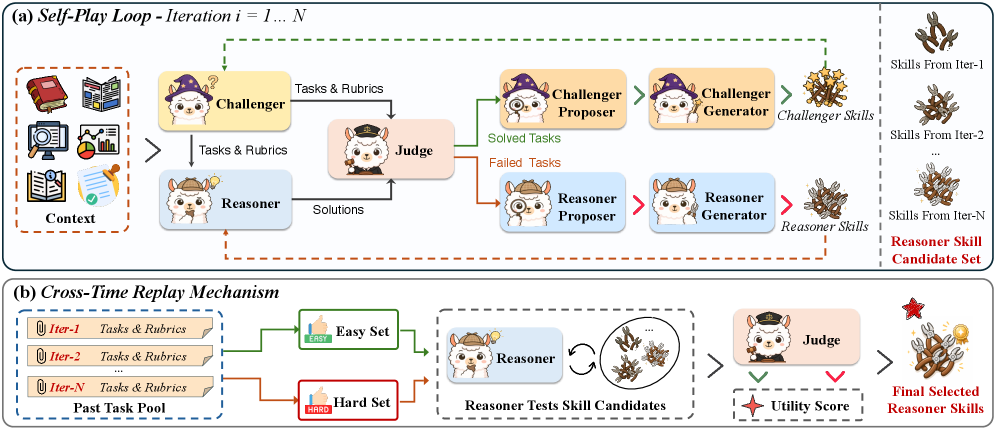
Figure 2 — Ctx2Skill 전체 워크플로우
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Ctx2Skill을 통해 LLM이 인간의 감독 없이도 복잡한 맥락에서 스스로 스킬을 학습하고 진화시킬 수 있음을 입증하였다. 이 프레임워크는 폐쇄형 모델에서도 parameter 업데이트 없이 추론 성능을 향상시킬 수 있다는 점에서 학계와 산업계에 높은 활용성을 가진다. 특히 context-specific한 스킬이 모델 간 전이(Transferability)가 가능하다는 점은, 고성능 모델에서 도출된 스킬셋이 더 작은 모델의 능력을 극대화하는 실용적인 방법론이 될 수 있음을 시사한다. 향후 연구에서는 정형화된 정답 검증이 가능한 도메인으로의 확장을 통해 더 정교한 자가 학습 루프를 구축할 수 있을 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] TREK: Distill to Explore, Reinforce to Refine
- [논문리뷰] Trust Region On-Policy Distillation
- [논문리뷰] Language Models Need Sleep: Learning to Self-Modify and Consolidate Memories
- [논문리뷰] ResearchMath-14K: Scaling Research-Level Mathematics via Agents
- [논문리뷰] Less is More: Early Stopping Rollout for On-Policy Distillation
Review 의 다른글
- 이전글 [논문리뷰] ComboStoc: Combinatorial Stochasticity for Diffusion Generative Models
- 현재글 : [논문리뷰] From Context to Skills: Can Language Models Learn from Context Skillfully?
- 다음글 [논문리뷰] Generative Modeling with Orbit-Space Particle Flow Matching
댓글