[논문리뷰] Convergent Evolution: How Different Language Models Learn Similar Number Representations
링크: 논문 PDF로 바로 열기
본 논문은 다양한 언어 모델에서 나타나는 주기적인 수 표현(number representation) 학습 현상을 분석하고, 이 과정에서 발생하는 'Spectral Convergence'와 'Geometric Convergence'의 계층적 구조를 규명합니다.
메타데이터
저자: Deqing Fu, Tianyi Zhou, Mikhail Belkin, Vatsal Sharan, Robin Jia
1. Key Terms & Definitions (핵심 용어 및 정의)
- Fourier Spikes: 모델 임베딩의 Fourier 스펙트럼에서 특정 주기 $T$(예: 2, 5, 10)에 나타나는 두드러진 피크 현상으로, 주기적 패턴을 의미합니다.
- Spectral Convergence: 모델이 학습 과정에서 Fourier 스펙트럼 내에 주기적인 Fourier Spikes를 독립적으로 형성하는 현상입니다.
- Geometric Convergence: 모델의 임베딩 내에서 특정 모듈로 산술($n \pmod T$) 정보가 선형적으로 분리 가능한(linearly separable) 구조로 형성되는 것을 의미합니다.
- Fisher Discriminant Analysis: 클래스 간 분산($S_B$)과 클래스 내 분산($S_W$)을 사용하여 데이터를 최적으로 분리하는 투영 방향을 찾는 기법으로, 본 논문에서는 선형 프로빙 성능을 설명하는 이론적 도구로 사용됩니다.
- Convergence Evolution: 서로 다른 아키텍처, 데이터, 옵티마이저를 가진 모델들이 공통된 학습 제약 조건 하에서 유사한 내부 표현을 독립적으로 학습하는 현상을 뜻합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 언어 모델이 일반 텍스트 학습만으로도 수(number)에 대한 주기적인 표현을 학습한다는 기존 연구들의 관찰에서 출발합니다. 그러나 저자들은 단순히 Fourier 도메인에서의 주기성(Fourier spikes)이 모델이 수의 모듈로 산술(modular arithmetic)적 성질을 실제로 이해하고 있다는 것을 보장하지 않는다는 점에 주목합니다. 기존 연구들은 Spectral Convergence와 Geometric Convergence를 혼동해왔으며, 무엇이 모델로 하여금 선형적으로 분리 가능한 기능적 수 표현을 학습하게 만드는지에 대한 규명이 부족했습니다. 본 논문은 이러한 표현의 불일치를 해결하고 학습 제약 조건의 역할을 밝히고자 합니다 [Figure 1].
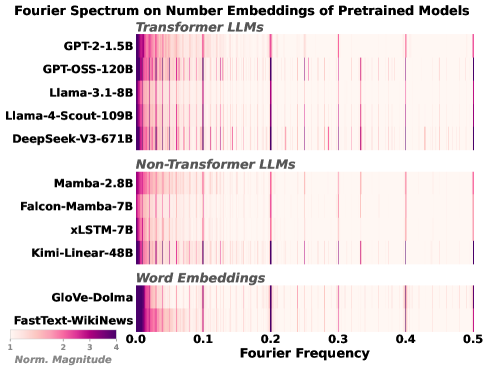
Figure 1 — Fourier Spikes의 보편성과 두 유형의 수렴
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 구조적 귀인(structural attribution) 기법을 도입하여 학습 데이터, 아키텍처, 옵티마이저가 Geometric Convergence에 미치는 영향을 체계적으로 분석했습니다. 핵심적으로 Spectral Convergence는 학습 데이터의 토큰 빈도만으로도 발생하지만, Geometric Convergence는 더 복잡한 조건(텍스트-수 공존 신호, 아키텍처 등)을 요구하는 두 계층의 위계임을 증명했습니다.
주요 실험 결과는 다음과 같습니다:
- 이론적으로 Theorem 1을 통해 Fourier spikes의 존재는 모듈로 프로빙을 위한 필요조건일 뿐 충분조건이 아님을 증명했습니다. Fourier power($\Phi_T$)가 커도 클래스 내 분산($S_W$)의 조건수(condition number)가 높으면 선형 프로빙 성능이 저조할 수 있음을 보여줍니다 [Figure 2].
- 데이터 실험에서 텍스트-수 공존(co-occurrence) 정보와 넓은 문맥(context length), 수 간의 상호작용이 Geometric Convergence에 핵심적인 기여를 함을 확인했습니다 [Figure 4].
- 아키텍처 비교에서 Transformer, Linear RNNs(Gated DeltaNet, Mamba-2)은 강력한 Geometric Convergence를 보인 반면, LSTM은 뚜렷한 Fourier spikes를 보임에도 불구하고 프로빙 성능은 무작위 수준에 머물렀습니다 [Figure 5].
- 덧셈 학습 실험을 통해 다중 토큰(multi-token) 토큰화 방식이 carry propagation을 통해 모듈로 산술 문제를 유도하여 모델이 구조적 표현을 학습하게 함을 입증했습니다 [Figure 6].
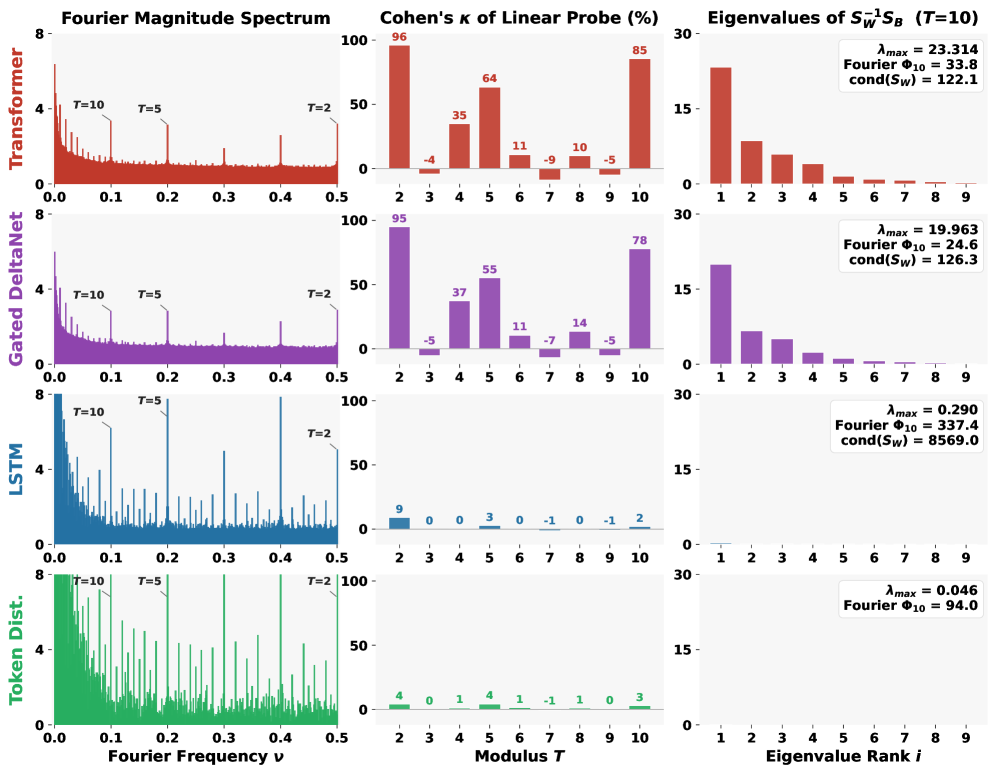
Figure 2 — Fourier Spikes와 기능적 학습 간의 불일치
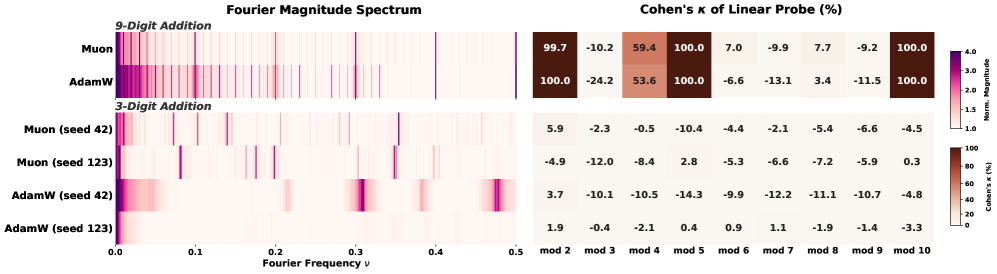
Figure 6 — 덧셈 학습에서 토큰화가 수렴에 미치는 영향
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Fourier Spikes가 모델의 기능적 이해를 보장하지 않는다는 '표현 수준의 진단'에 대한 경각심을 일깨워줍니다. 모델이 보여주는 겉보기 주기성이 통계적 아티팩트일 수 있음을 밝히고, 기능적 학습(Geometric)과 표면적 학습(Spectral)을 구분하는 명확한 분석 프레임워크를 제공했습니다. 이는 차후 LLM의 Mechanistic Interpretability 연구에서 수치뿐만 아니라 요일, 월 등 주기적 개념을 다루는 모델의 진정한 이해도를 평가하는 데 중요한 잣대가 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Emergence of Linear Truth Encodings in Language Models
- [논문리뷰] Language Models are Injective and Hence Invertible
- [논문리뷰] Mixing Mechanisms: How Language Models Retrieve Bound Entities In-Context
- [논문리뷰] Eliciting Secret Knowledge from Language Models
- [논문리뷰] HYDRA-X: Native Unified Multimodal Models with Holistic Visual Tokenizers
Review 의 다른글
- 이전글 [논문리뷰] A Self-Evolving Framework for Efficient Terminal Agents via Observational Context Compression
- 현재글 : [논문리뷰] Convergent Evolution: How Different Language Models Learn Similar Number Representations
- 다음글 [논문리뷰] Cortex 2.0: Grounding World Models in Real-World Industrial Deployment
댓글