[논문리뷰] Scaling Test-Time Compute for Agentic Coding
링크: 논문 PDF로 바로 열기
저자: Joongwon (Daniel) Kim, Winnie Yang, Kelvin Niu, Hongming Zhang, Yun Zhu, Eryk Helenowski, Ruan Silva, Zhengxing Chen, Srini Iyer, Manzil Zaheer, Daniel Fried, Hannaneh Hajishirzi, Sanjeev Arora, Gabriel Synnaeve, Ruslan Salakhutdinov, Anirudh Goyal
1. Key Terms & Definitions (핵심 용어 및 정의)
- Agentic Coding: 외부 Bash 환경과 상호작용하며 파일을 읽고, 코드를 편집하며, 중간 오류에 대응하는 다단계 긴 호흡의 코딩 작업 방식입니다.
- Rollout Trajectory: 에이전트가 문제를 해결하는 과정에서 생성한 일련의 Thought, Action, Observation의 전체 기록입니다.
- Recursive Tournament Voting (RTV): 병렬로 생성된 여러 Rollout 후보들의 요약을 토너먼트 방식으로 재귀적으로 비교하여 최상의 결과를 선택하는 기법입니다.
- Parallel-Distill-Refine (PDR): 이전 반복(iteration)에서 생성된 Rollout의 요약을 증류(distill)하여 다음 Rollout 생성을 위한 컨텍스트(refinement context)로 활용하는 순차적 정제 프레임워크입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Long-horizon 코딩 에이전트의 Inference-time scaling을 위해 데이터의 표현(Representation)과 선택(Selection) 방식이 핵심 Bottleneck임을 규명합니다. 기존의 Test-time scaling 방법론들은 주로 단일 회차로 종료되는 수학적 추론이나 간단한 코드 생성 작업에 최적화되어 있어, 에이전트가 생성하는 길고 소음이 섞인 Raw trajectory를 직접 다루는 데 한계가 있습니다. 저자들은 이러한 Raw 데이터를 직접 사용하는 대신, 핵심 가설, 진행 상황, 오류 모드를 구조화하여 압축한 Structured Summary를 중간 매개체로 활용하는 접근 방식을 제안합니다. [Figure 1]은 이 프레임워크를 통해 frontier 모델들이 주요 벤치마크에서 성능 향상을 이룬 결과를 보여줍니다.
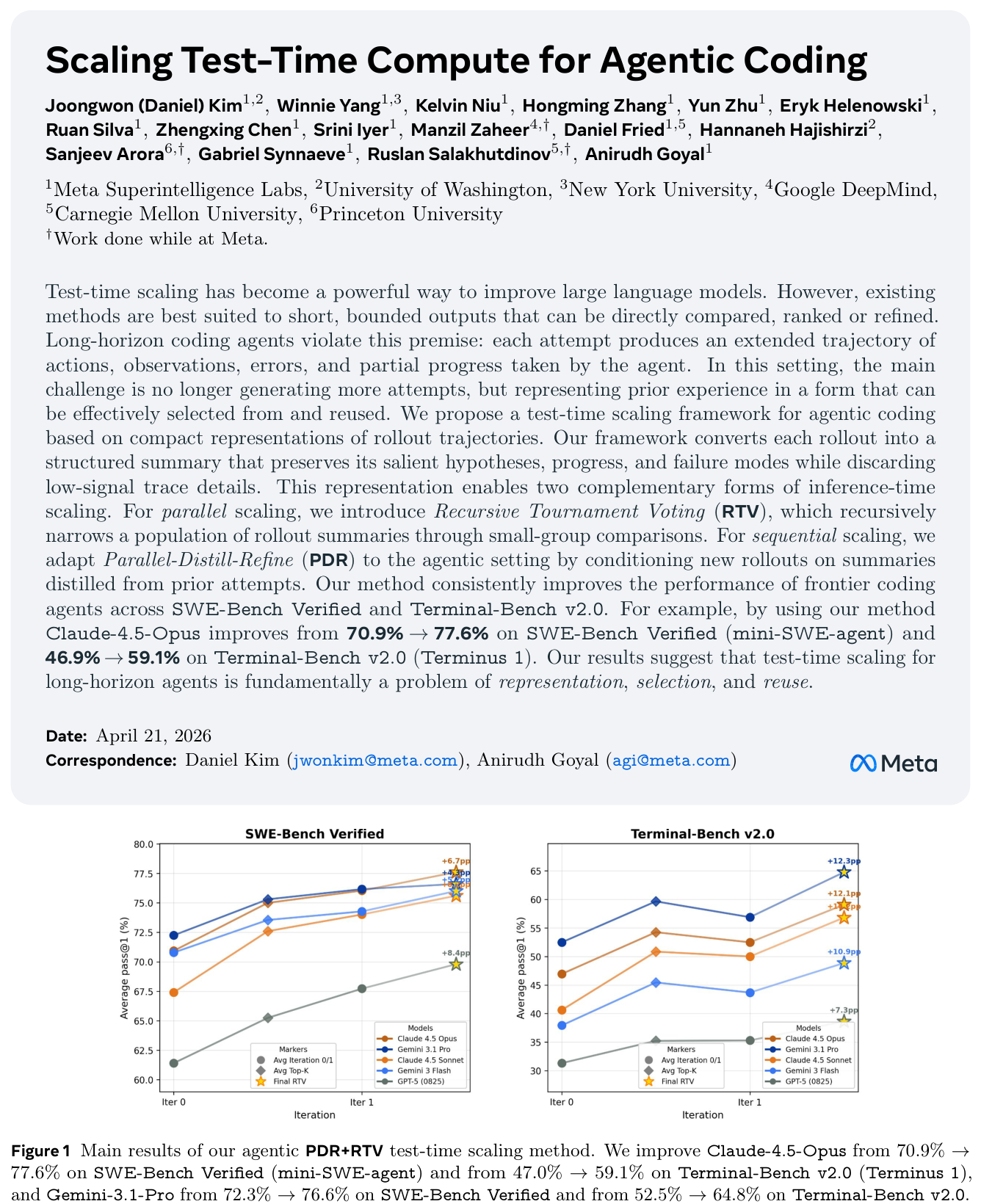
Figure 1 — 방법론 도입 후 SWE-Bench Verified와 Terminal-Bench v2.0에서의 성능 향상을 보여주는 핵심 결과 그래프
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 Rollout을 구조화된 요약으로 변환한 뒤, 이를 활용하여 병렬적 선택(Parallel aggregation)과 순차적 정제(Sequential refinement)를 동시에 수행하는 통합 프레임워크를 제안합니다. 병렬적 차원에서는 RTV를 도입하여 16개의 후보를 $G=2$ 그룹으로 나누어 재귀적으로 비교함으로써 선택의 효율성을 극대화했고, 순차적 차원에서는 PDR을 adapt하여 이전의 성공적인 경험을 새로운 Rollout의 컨텍스트로 주입합니다. [Figure 3]은 PDR+RTV의 통합 파이프라인 구조를 잘 보여줍니다. 실험 결과, Claude-4.5-Opus는 SWE-Bench Verified에서 70.9%에서 77.6%로, Terminal-Bench v2.0에서 47.0%에서 59.1%로 성능이 대폭 향상되었습니다. 또한, 순차적 정제를 통해 후속 에이전트가 해결 과정에서 소모하는 평균 step 수를 약 50% 절감하는 효율성 개선을 달성했습니다. [Table 3]은 여러 frontier 모델들에서 이 방법론이 일관된 성능 향상을 입증함을 보여줍니다.
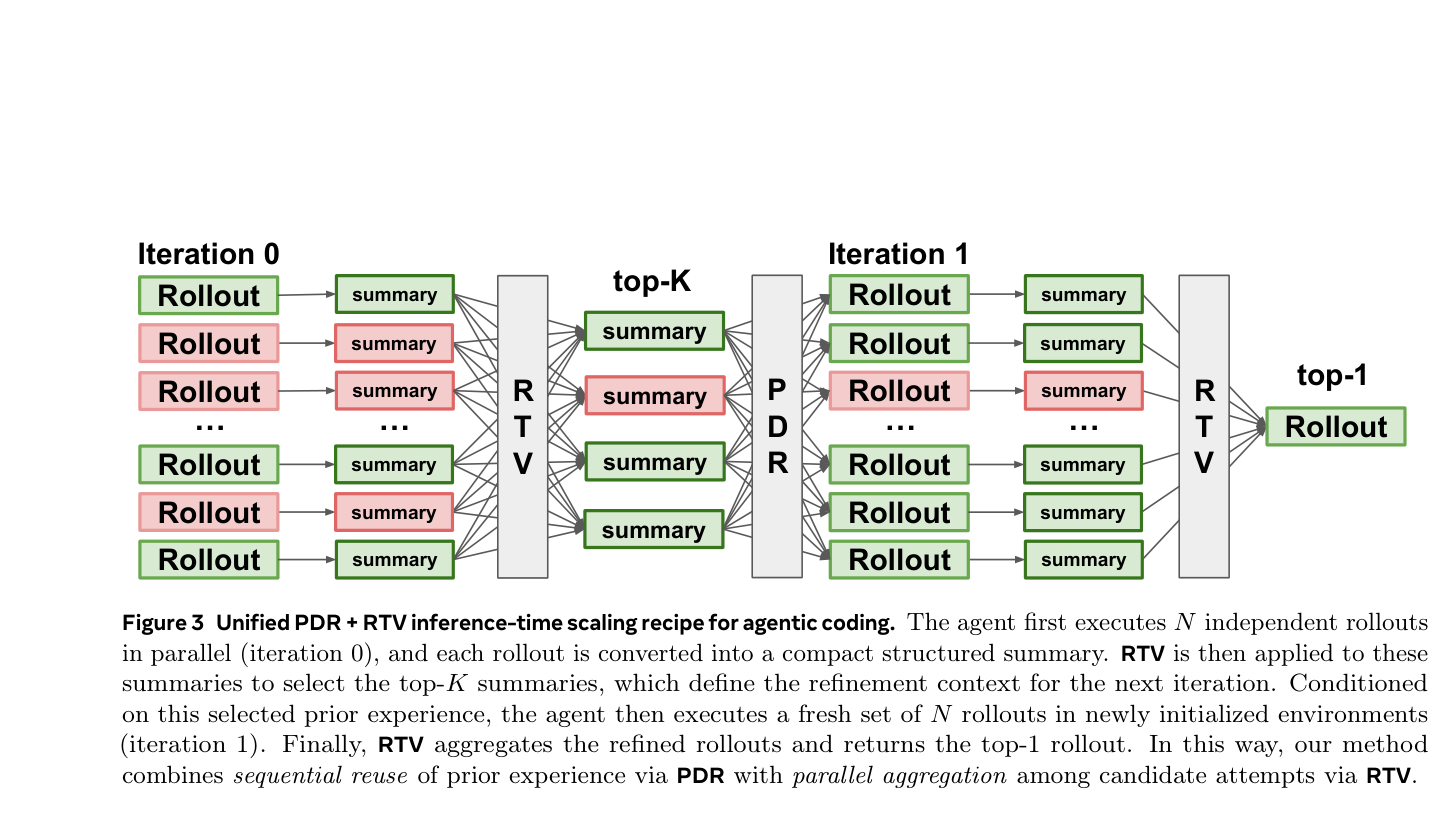
Figure 3 — 병렬 선택(RTV)과 순차적 정제(PDR)가 결합된 통합 프레임워크의 파이프라인 구조

Table 3 — 제안 기법을 사용한 주요 frontier LLM들의 단계별 Pass@1 성능 향상 수치 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 긴 호흡의 에이전트 시스템에서 Inference-time scaling의 성공이 고품질의 궤적 표현과 효과적인 선택/재사용 기법에 달려 있음을 입증했습니다. 제안된 Structured summary 기반의 RTV 및 PDR 파이프라인은 모델의 크기를 키우지 않고도 복잡한 에이전트 태스크 해결 능력을 대폭 끌어올릴 수 있는 유효한 대안을 제시합니다. 이는 향후 에이전트가 단순히 경험을 나열하는 것을 넘어, 자신의 과거 시행착오를 스스로 요약하고 구조화하여 지속 가능한 학습 자산으로 축적하는 방향으로 나아가는 중요한 밑거름이 될 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] HYDRA-X: Native Unified Multimodal Models with Holistic Visual Tokenizers
- [논문리뷰] FORT-Searcher: Synthesizing Shortcut-Resistant Search Tasks for Training Deep Search Agents
- [논문리뷰] A Stationary (and Therefore Compatible) Representation is All You Need
- [논문리뷰] SEAOTTER: Sensor Embedded Autoencoding with One-Time Transcode for Efficient Reconstruction
- [논문리뷰] Semi-Supervised Noise Adaptation: Transferring Knowledge from Noise Domain
Review 의 다른글
- 이전글 [논문리뷰] SWE-chat: Coding Agent Interactions From Real Users in the Wild
- 현재글 : [논문리뷰] Scaling Test-Time Compute for Agentic Coding
- 다음글 [논문리뷰] Tadabur: A Large-Scale Quran Audio Dataset
댓글