[논문리뷰] SWE-chat: Coding Agent Interactions From Real Users in the Wild
링크: 논문 PDF로 바로 열기
메타데이터
저자: Joachim Baumann, Vishakh Padmakumar, Xiang Li, John Yang, Diyi Yang, Sanmi Koyejo
1. Key Terms & Definitions (핵심 용어 및 정의)
- SWE-chat: 실제 오픈소스 개발자들이 사용하는 코딩 에이전트 세션의 상호작용 로그를 수집한 최초의 대규모 데이터셋.
- Vibe coding: 개발자가 코딩 에이전트에게 고수준의 요청을 내리고, 에이전트가 커밋된 코드의 99% 이상을 단독으로 작성하는 작업 방식.
- Code Attribution: 커밋된 코드의 라인별 기여자를 인간(Human)과 에이전트(Agent)로 구분하여 기록하는 추적 기법.
- User Pushback: 에이전트의 출력물에 대해 사용자가 수행하는 수정(Correction), 거부(Rejection), 오류 보고(Failure report) 등의 개입 활동.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 실제 현장에서 사용되는 AI 코딩 에이전트의 구체적인 활용 양상과 실패 모드를 체계적으로 분석하고자 한다. 기존의 연구들은 주로 고립되고 제한된 환경의 벤치마크(예: SWE-bench)에 의존하고 있어, 실제 소프트웨어 엔지니어링 워크플로우에서의 복합적인 상호작용과 실패 지점을 설명하지 못하는 한계가 있다 [Figure 1]. 저자들은 이러한 '실제 환경(In the wild)'에서의 데이터 부족을 해결하기 위해, 사용자들의 실제 상호작용을 추적하는 SWE-chat 데이터셋을 구축하였다. 이를 통해 에이전트의 실질적인 기여도와 효율성, 그리고 사용자의 개입 패턴을 실증적으로 규명하고자 한다.
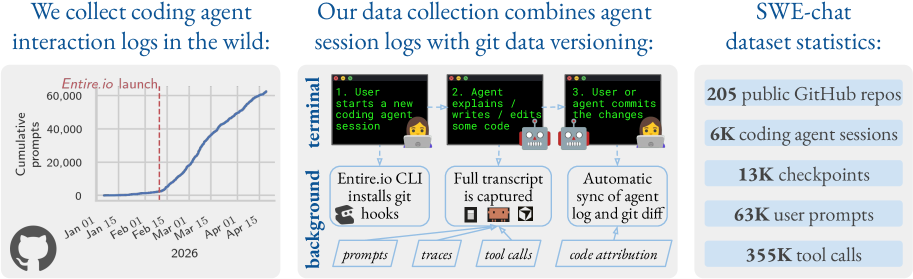
Figure 1 — SWE-chat 데이터셋 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 GitHub 저장소에서 코딩 에이전트 세션을 자동으로 기록하는 오픈소스 도구인 Entire.io를 활용하여 데이터셋을 구축하였다. 수집된 데이터는 인간과 에이전트 간의 상세한 상호작용 추적(Interaction traces)과 라인별 코드 기여도 정보를 포함한다 [Table 1]. 주요 분석 결과, 코딩 작업 방식은 인간이 모든 코드를 작성하는 방식부터 에이전트가 전부 작성하는 Vibe coding까지 양극화되는 경향을 보인다 [Figure 5]. 데이터 분석 결과, Vibe coding 방식은 전체 세션의 40.8%를 차지하며 증가 추세에 있으나, 에이전트가 작성한 코드의 44.3%만이 실제 커밋으로 이어지는 낮은 효율성을 기록하였다 [Table 3]. 또한 Vibe coding은 협업 코딩 방식 대비 약 3배의 토큰과 비용을 소모하며, 보안 취약점 도입 확률은 인간 단독 코딩 대비 약 9배, 협업 코딩 대비 약 5배 높게 나타났다 [Table 4]. 사용자는 전체 턴(Turn)의 39%에서 에이전트의 결과물에 적극적으로 개입(Pushback)하며, 에이전트는 사용자의 질문에 매우 드물게(1.4%) 반응하는 비대칭성을 확인하였다 [Figure 8].
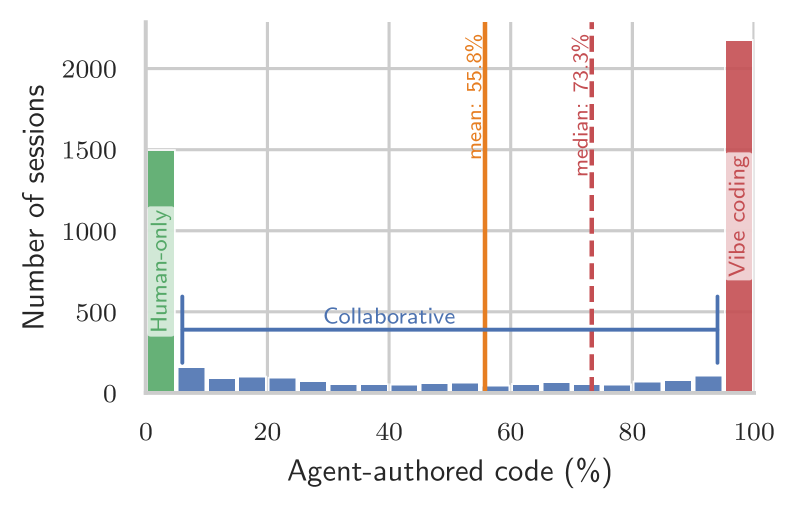
Figure 5 — 코딩 모드별 기여 분포
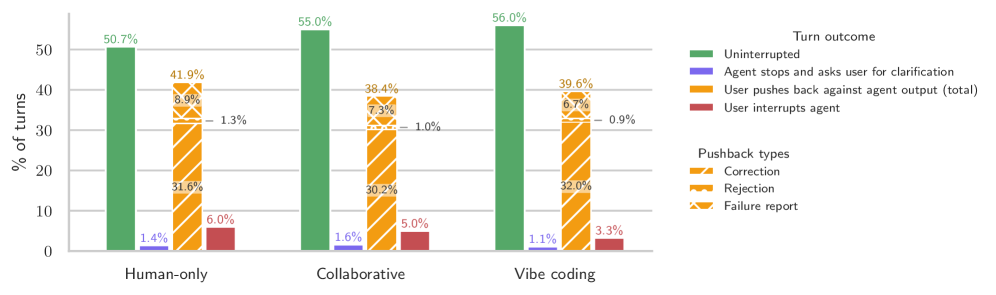
Figure 8 — 세션 내 개입 패턴 분석
4. Conclusion & Impact (결론 및 시사점)
본 논문은 코딩 에이전트가 실무에서 높은 자율성을 확보하고 있음에도 불구하고, 실제 효율성과 코드 안정성 측면에서는 상당한 개선이 필요함을 실증하였다. 연구 결과는 단순히 패치 생성을 넘어선 복잡한 워크플로우 평가의 중요성을 강조하며, 향후 더 나은 인간-에이전트 인터랙션 설계와 실무 데이터를 기반으로 한 신뢰성 있는 에이전트 훈련의 필요성을 제시한다. SWE-chat 데이터셋은 AI 에이전트의 실제 성능을 이해하고 평가할 수 있는 중요한 연구 기반을 마련하며, 학계와 산업계가 보다 안전하고 생산적인 코딩 환경을 구축하는 데 기여할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] SWE-Explore: Benchmarking How Coding Agents Explore Repositories
- [논문리뷰] Qwen3-Coder-Next Technical Report
- [논문리뷰] SWE-EVO: Benchmarking Coding Agents in Long-Horizon Software Evolution Scenarios
- [논문리뷰] NL2Repo-Bench: Towards Long-Horizon Repository Generation Evaluation of Coding Agents
- [논문리뷰] A Survey of Vibe Coding with Large Language Models
Review 의 다른글
- 이전글 [논문리뷰] Reward Hacking in the Era of Large Models: Mechanisms, Emergent Misalignment, Challenges
- 현재글 : [논문리뷰] SWE-chat: Coding Agent Interactions From Real Users in the Wild
- 다음글 [논문리뷰] Scaling Test-Time Compute for Agentic Coding
댓글