[논문리뷰] One-Eval: An Agentic System for Automated and Traceable LLM Evaluation
링크: 논문 PDF로 바로 열기
1. Key Terms & Definitions (핵심 용어 및 정의)
- One-Eval : Natural language evaluation requests를 executable, traceable, customizable evaluation workflows로 변환하는 agentic system입니다.
- NL2Bench : User의 evaluation intent를 structured representation으로 변환하고, 사용자 목표에 맞는 benchmarks를 검색 및 추천하여 benchmark plan을 생성하는 모듈입니다.
- BenchResolve : Benchmark identifiers를 resolve하고, datasets을 자동적으로 acquisition하며, schema normalization을 통해 실행 가능한 configuration을 구축하는 모듈입니다.
- Metrics & Reporting : Task-aware metric selection을 수행하고, scalar score를 넘어선 decision-oriented evaluation reports를 생성하는 모듈입니다.
- Human-in-the-Loop : Key decision points에서 사용자가 agent의 결정을 검토, 편집 및 rollback할 수 있도록 하여 자동화 효율성을 유지하면서 신뢰성을 확보하는 메커니즘입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Large Language Models (LLMs)의 산업 시스템 도입이 가속화됨에 따라 reliable evaluation 은 model lifecycle 전반에 걸쳐 critical한 구성 요소가 되었습니다. 그러나 현재의 evaluation practices는 상당한 manual effort 를 요구합니다. Practitioners는 적절한 benchmarks를 식별하고, 이질적인 evaluation codebases를 재현하며, dataset schema mappings을 구성하고, aggregate metrics를 해석해야 하는 등의 heavy burden 에 직면합니다. 기존 evaluation workflows는 insufficient flexibility 와 usability 를 제공하며, 주로 execution과 score aggregation에 초점을 맞춰 benchmark와 metrics를 static configurations로 취급합니다. 이는 높은 수준의 evaluation intent interpretation, personalized benchmark selection, configuration validation, 또는 decision-oriented result analysis가 underexplored 상태임을 의미하며, evaluation outputs이 사용자의 특정 목표 및 task 요구사항과 약하게 align되는 문제로 이어집니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
One-Eval 은 high-level natural language evaluation request를 executable하고 verifiable한 model evaluation workflows로 변환하는 agentic evaluation framework 를 제안합니다
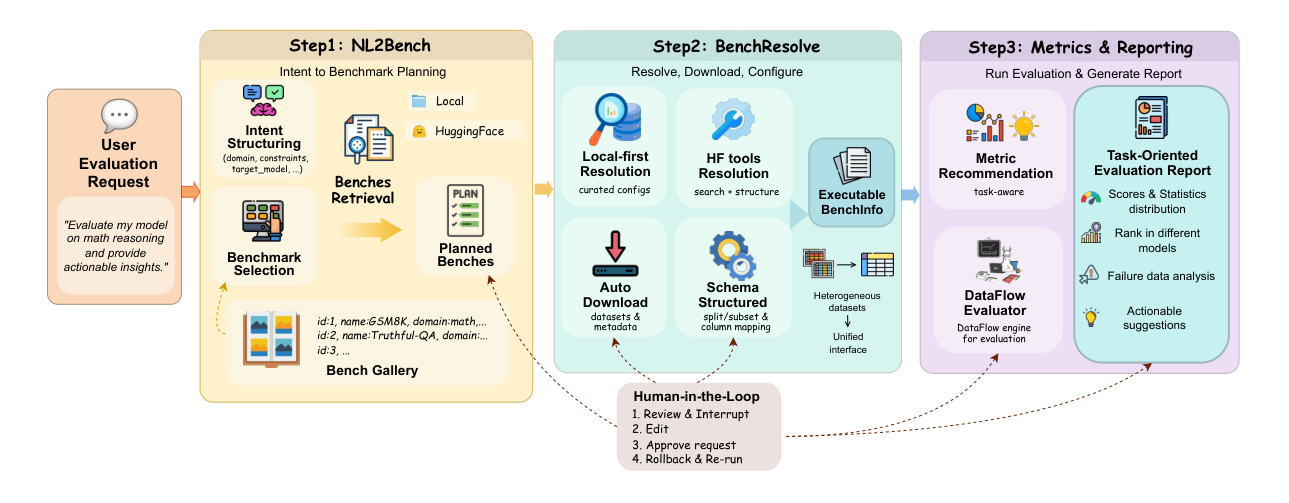 Figure 1: One-Eval overview. One-Eval converts a natural-language evaluation request into an executable EvalPlan (NL2Bench), resolves and configures benchmarks by automatic dataset download and schema normalization (BenchResolve), and produces task-aware metrics and a decision-oriented evaluation report (Metrics & Reporting), with human-in-the-loop refinement at key steps.
Figure 1: One-Eval overview. One-Eval converts a natural-language evaluation request into an executable EvalPlan (NL2Bench), resolves and configures benchmarks by automatic dataset download and schema normalization (BenchResolve), and produces task-aware metrics and a decision-oriented evaluation report (Metrics & Reporting), with human-in-the-loop refinement at key steps.
. 이 시스템은 세 가지 주요 stage를 따릅니다: (1) NL2Bench 는 user request를 structured intent로 해석하고, user goals에 맞는 benchmarks를 검색 또는 추천하며, interactive refinement를 지원합니다. (2) BenchResolve 는 dataset acquisition, dependency management, configuration validation을 통해 automated benchmark resolution 및 settings completion을 처리하여 manual effort와 configuration errors를 줄입니다. (3) Metrics & Reporting 은 task-aware metric recommendation 및 decision-oriented report generation을 수행하여 scalar score를 넘어선 structured, decision-support evaluation reports를 생성합니다. 또한, 시스템은 key decision points에 Human-in-the-Loop check-points를 통합하여 사용자가 agent의 결정을 review, edit, rollback할 수 있도록 하며, debugging 및 auditability를 위한 sample evidence trails을 보존합니다.
실험 결과, One-Eval 은 100개 의 diverse natural-language requests에 대해 end-to-end evaluation을 실행할 수 있음을 보여주었습니다. 시스템은 Plan Executable Rate 99% , Auto-Complete Rate 85% , Full Plan Rate 84% 를 달성하여 최소한의 user effort로 높은 자동화 신뢰성을 입증했습니다
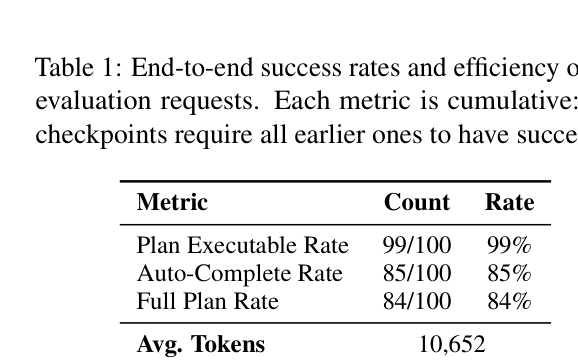 Table 1: End-to-end success rates and efficiency on 100 evaluation requests. Each metric is cumulative: later checkpoints require all earlier ones to have succeeded.
Table 1: End-to-end success rates and efficiency on 100 evaluation requests. Each metric is cumulative: later checkpoints require all earlier ones to have succeeded.
. 전체 8-단계 파이프라인은 request당 평균 13분 의 wall-clock time 내에 완료되었습니다. Feature-level comparison에서는 One-Eval 이 기존의 Im-eval-harness , OpenCompass , HELM 과 같은 대표적인 evaluation frameworks 대비 Customization , Automation , Benchmark Recommendation , Metric Recommendation 측면에서 모두 지원하는 유일한 시스템임을 강조합니다
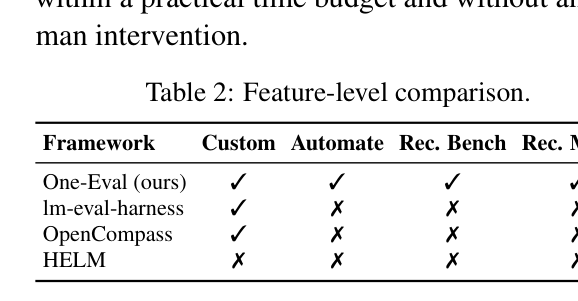 Table 2: Feature-level comparison.
Table 2: Feature-level comparison.
.
4. Conclusion & Impact (결론 및 시사점)
One-Eval 은 natural-language evaluation request를 NL2Bench , BenchResolve , 그리고 task-aware Metrics & Reporting 을 통해 traceable한 end-to-end workflows로 변환하는 agentic system을 성공적으로 제안합니다. 이 시스템은 기존 LLM evaluation의 manual effort 및 fragmented automation 문제를 해결하며, 사용자 intent 기반의 personalized evaluation plan 생성, 자동화된 benchmark resolution, 그리고 decision-oriented reporting 기능을 제공합니다. 실험은 One-Eval 이 최소한의 사용자 노력으로 높은 신뢰성과 효율성을 바탕으로 end-to-end evaluation을 실행할 수 있음을 입증했습니다. 본 연구는 산업 환경에서 LLM evaluation의 efficiency 와 reproducibility 를 크게 향상시키고, 더욱 actionable한 insights를 제공함으로써 LLM model lifecycle 전반에 걸쳐 중요한 기여를 할 것으로 기대됩니다. 향후 연구는 더 많은 tasks 및 modalities로의 coverage 확장을 통해 long-tail benchmarks에 대한 지원을 강화할 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] Mixture of Style Experts for Diverse Image Stylization
- 현재글 : [논문리뷰] One-Eval: An Agentic System for Automated and Traceable LLM Evaluation
- 다음글 [논문리뷰] Online Experiential Learning for Language Models
댓글