[논문리뷰] EffectErase: Joint Video Object Removal and Insertion for High-Quality Effect Erasing
링크: 논문 PDF로 바로 열기
저자: Yang Fu, Yike Zheng, Ziyun Dai, Henghui Ding
1. Key Terms & Definitions (핵심 용어 및 정의)
- Video Object Removal (VOR) : 비디오 내의 동적인 타겟 객체와 그에 수반되는 시각적 효과(예: deformation, shadow, reflection)를 제거하고, 배경을 자연스럽게 복원하는 기술.
- Video Object Insertion : Video Object Removal의 역(inverse) 태스크로, 객체를 비디오에 삽입하고 실제와 같은 객체 유발 효과를 생성하는 작업.
- VOR Dataset : Effect-aware Video Object Removal 연구를 위해 제안된 대규모 하이브리드 데이터셋으로, 카메라로 촬영된 비디오와 3D 합성 비디오를 모두 포함하며, 타겟 객체가 있는 비디오와 없는 비디오 쌍, 그리고 해당 객체 마스크를 제공.
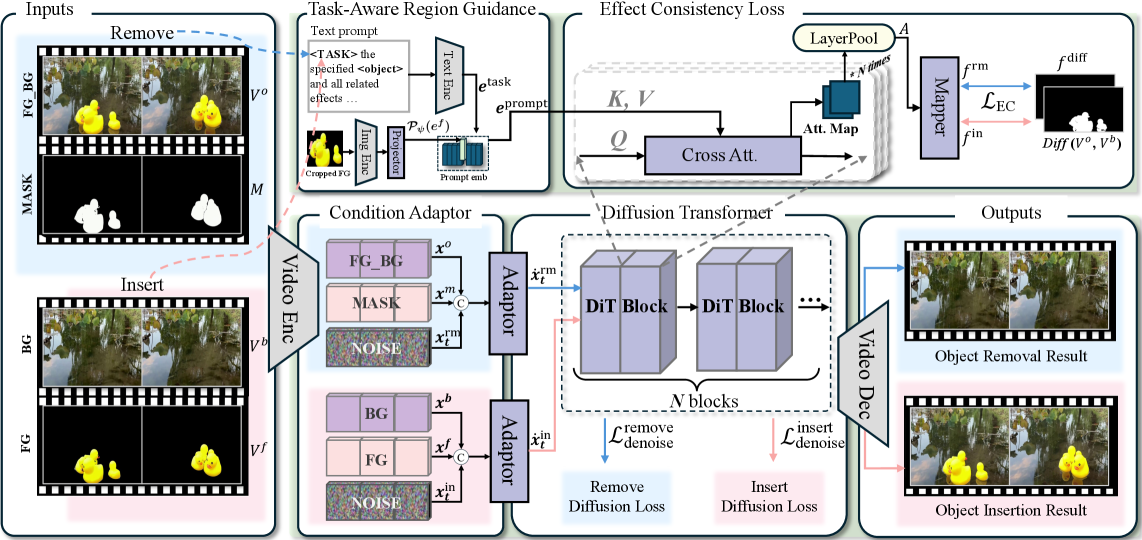
- Task-Aware Region Guidance (TARG) Module : EffectErase 프레임워크의 핵심 모듈 중 하나로, 객체 visual token과 task-specific token을 활용한 cross-attention 메커니즘을 통해 객체와 그 효과 간의 시공간적 상관관계를 모델링하여, 영향을 받은 영역을 정확히 식별하고 제거 및 삽입 태스크 간 유연한 전환을 가능하게 함.
- Effect Consistency (EC) Loss : EffectErase 프레임워크에서 사용되는 손실 함수로, Video Object Removal과 Insertion이 동일한 효과 영역을 공유한다는 특성을 활용하여 두 태스크 브랜치에서 학습된 효과 영역을 일관되게 정렬함으로써, 효과 인식 학습을 강화하고 구조적 feature representation의 일관성을 유도함.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존의 Video Object Removal 방법론들은 주로 입력 마스크에 의존하여 객체를 제거하며, 이로 인해 객체가 유발하는 그림자(shadow), 반사(reflection), 변형(deformation)과 같은 복잡한 시각적 부수 효과(side effects)를 제대로 처리하지 못하는 한계가 있습니다 [cite: 1, Figure 2]. 이는 결과물의 시각적 품질 저하와 부자연스러운 배경 복원으로 이어집니다. 일부 방법들은 이러한 효과를 간접적으로 또는 마스크를 통해 명시적으로 예측하려 시도했지만, 객체와 그 효과 간의 시공간적 상관관계(spatiotemporal correlation)를 명확하게 모델링하는 데 어려움을 겪어 복잡한 실제 환경에서 견고성과 정확한 효과 영역 localizing에 제약이 있었습니다.
또한, 이러한 방법론적 한계 외에도, 다양한 환경에서 공통적인 객체 효과를 체계적으로 포착하는 대규모 공개 데이터셋의 부족이 이 분야의 발전을 저해하는 주요 문제였습니다. 기존 이미지 기반 데이터셋은 시간적 일관성(temporal consistency)을 제공하지 못하고, 합성 비디오 데이터셋은 객체 움직임이나 효과의 현실성을 충분히 반영하지 못하는 한계가 있었습니다. 이러한 문제점들을 해결하기 위해, 저자들은 포괄적인 데이터셋 구축과 효과를 인식하는(effect-aware) 새로운 Video Object Removal 접근 방식의 필요성을 제기합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 효과를 인식하는(effect-aware) Video Object Removal 을 위해 VOR (Video Object Removal) Dataset 과 EffectErase 라는 프레임워크를 제안합니다. VOR Dataset 은 실제 촬영 데이터와 3D 합성 데이터를 결합한 대규모 하이브리드 데이터셋으로, occlusion, shadow, lighting, reflection, deformation의 다섯 가지 대표적인 객체 유발 효과를 포함하며, 60K 쌍의 고품질 비디오와 해당 마스크를 제공합니다 [cite: 1, Figure 5].
제안하는 EffectErase 프레임워크는 Video Object Removal과 Insertion이 동일한 영향을 받는 영역에서 작동하는 역(inverse) 태스크라는 상호 보완적인 관계(complementary relationship)에 착안하여, 두 태스크를 상호 학습(reciprocal learning)하는 이중 학습 패러다임(dual-learning paradigm)을 사용합니다 [cite: 1, Figure 3]. 이 모델은 사전 학습된 VAE 와 DiT 백본을 기반으로 하며, 세 가지 주요 구성 요소로 이루어져 있습니다 [cite: 1, Figure 6]:
- Removal–Insertion Joint Learning : 비디오 Object Removal 및 Insertion 태스크는 공동 denoising 백본을 공유하여 함께 학습됩니다. 이 방식은 두 태스크 간의 상호 보완적인 감독(complementary supervision)을 통해 모델이 일관된 영향을 받는 영역(affected regions)과 구조적 단서(structural cues)를 학습하도록 돕습니다.
- Task-Aware Region Guidance (TARG) Module : 객체 visual token과 태스크별 token을 포함하는
e_prompt를 사용하여, cross-attention 메커니즘을 통해 객체와 그 side effects 간의 시공간적 상관관계(spatiotemporal correlations)를 모델링합니다. 이는 모델이 영향을 받는 영역을 정확하게 localizing하고, Removal과 Insertion 태스크 간 유연한 전환을 가능하게 합니다. - Effect Consistency (EC) Loss : Removal과 Insertion 태스크가 동일한 효과 영역을 공유한다는 점에 기반하여, 두 태스크 브랜치에서 생성된 cross-attention map을 정렬하는 손실입니다. 이는 $V^o$와 $V^b$ 간의 차이에서 얻은 soft difference map prior(
f_diff)를 사용하여, 각 태스크에서 예측된 soft affected region estimations(f_rm및f_in)을 감독함으로써, attention 레이어들이 영향을 받는 영역에 더욱 집중하도록 유도합니다.
EffectErase 는 광범위한 실험에서 최첨단 성능을 달성했습니다. ROSE-Benchmark 에서 PSNR 32.161 , SSIM 0.948 , LPIPS 0.039 , FVD 55.578 을 기록하며 기존 방법들을 능가했습니다 [cite: 1, Table 2]. 특히, 비디오 품질 지표인 FVD 에서 가장 우수한 점수를 달성하여 생성된 비디오의 우수한 시간적 부드러움과 일관성을 입증했습니다 [cite: 1, Table 2]. 새로운 VOR-Eval 데이터셋에서는 PSNR 23.750 , SSIM 0.806 , LPIPS 0.170 , FVD 342.871 로 모든 비교 방법 대비 최고 성능을 보였습니다 [cite: 1, Table 2]. 또한, VOR-Wild 데이터셋에 대한 사용자 연구에서 QScore 9.280 및 7.20 의 사용자 피드백 점수를 얻어 시각적으로 설득력 있는 제거 결과의 효과를 증명했습니다 [cite: 1, Table 2]. Ablation Study를 통해 EC loss , TARG 모듈 , 그리고 합성 데이터(Synthesized Data) 의 포함이 각각의 성능 향상에 기여함을 확인했습니다. 예를 들어, EC loss 추가 시 FVD 가 368.664 에서 354.545 로 감소했으며, TARG 추가 시 SSIM 이 0.737 에서 0.780 으로 크게 향상되었습니다 [cite: 1, Table 3]. EffectErase 는 객체 삽입(object insertion) 태스크에도 유연하게 적용되어, 삽입된 객체에 대한 현실적인 그림자(shadow) 및 반사(reflection)와 같은 시각적 효과를 자연스럽게 생성하는 능력을 보여주었습니다 [cite: 1, Figure 9].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 대규모 하이브리드 VOR Dataset 과 EffectErase 프레임워크를 도입하여, 도전적인 effect-aware Video Object Removal 문제를 성공적으로 해결했습니다. VOR Dataset 은 실제 촬영 및 합성 비디오를 통해 다양한 객체 유발 효과를 포괄적으로 다루며, VOR-Eval 및 VOR-Wild 라는 두 가지 새로운 평가 벤치마크를 제공하여 이 분야의 연구를 위한 견고한 기반을 마련했습니다. EffectErase 는 Task-Aware Region Guidance (TARG) 를 통해 시공간적 객체-효과 상관관계를 모델링하고, Effect Consistency (EC) Loss 를 통해 Removal 및 Insertion 태스크 간 효과 영역을 일관되게 정렬하는 상호 학습(reciprocal learning) 방식을 효과적으로 활용합니다. 광범위한 실험을 통해 각 구성 요소의 기여를 검증했으며, EffectErase 는 복잡한 장면에서 객체와 그 효과를 고품질로 제거하는 최첨단 성능을 달성하고, 나아가 현실적인 객체 삽입(object insertion)으로 자연스럽게 확장 가능함을 입증했습니다 [cite: 1, Figure 9]. 이 연구는 비디오 편집 및 생성형 AI 분야에서 시각적 효과를 명시적으로 모델링하는 것의 중요성을 강조하며, 향후 연구에 중요한 시사점을 제공합니다.


⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Text-Vision Co-Instructed Image Editing
- [논문리뷰] Avatar V: Scaling Video-Reference Avatar Video Generation
- [논문리뷰] MultiBind: A Benchmark for Attribute Misbinding in Multi-Subject Generation
- [논문리뷰] Track4World: Feedforward World-centric Dense 3D Tracking of All Pixels
- [논문리뷰] YOLO Meets Mixture-of-Experts: Adaptive Expert Routing for Robust Object Detection
Review 의 다른글
- 이전글 [논문리뷰] Cubic Discrete Diffusion: Discrete Visual Generation on High-Dimensional Representation Tokens
- 현재글 : [논문리뷰] EffectErase: Joint Video Object Removal and Insertion for High-Quality Effect Erasing
- 다음글 [논문리뷰] F2LLM-v2: Inclusive, Performant, and Efficient Embeddings for a Multilingual World
댓글