[논문리뷰] Cubic Discrete Diffusion: Discrete Visual Generation on High-Dimensional Representation Tokens
링크: 논문 PDF로 바로 열기
I have browsed the paper. Now I will extract the required information.
Part 1: Markdown Summary
- Authors: Yuqing Wang, Chuofan Ma, Zhijie Lin, Yao Teng, Lijun Yu, Shuai Wang, Jiaming Han, Jiashi Feng, Yi Jiang, Xihui Liu
- Keywords:
Discrete Visual Generation,High-Dimensional Tokens,Cubic Discrete Diffusion,Dimension-wise Quantization,Multimodal Architectures,ImageNet
1. Key Terms & Definitions (핵심 용어 및 정의)
- High-Dimensional Representation Tokens : DINOv2 또는 SigLIP2와 같은 pretrained vision encoder에서 추출되는 768-1024 차원의 features를 dimension-wise quantization을 통해 이산화한 tokens. Understanding 및 Generation task 모두에 사용 가능한 semantic richness를 보유한다.
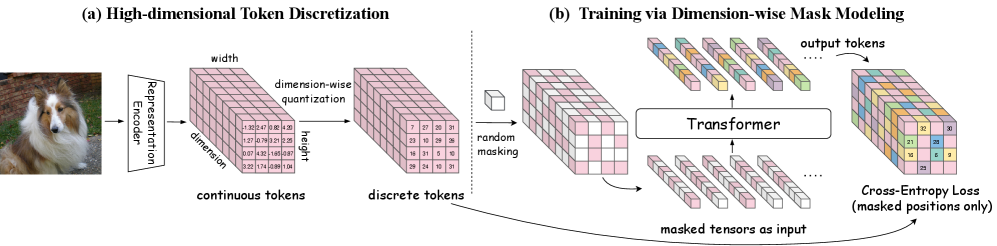
- Dimension-wise Quantization (DQ) : High-dimensional features를 이산화하는 방법론으로, 각 dimension을 독립적으로 양자화하여 high-dimensional space에서의 Vector Quantization(VQ) 문제점을 회피한다. Training-free하며 original continuous features의 semantic quality를 유지한다.
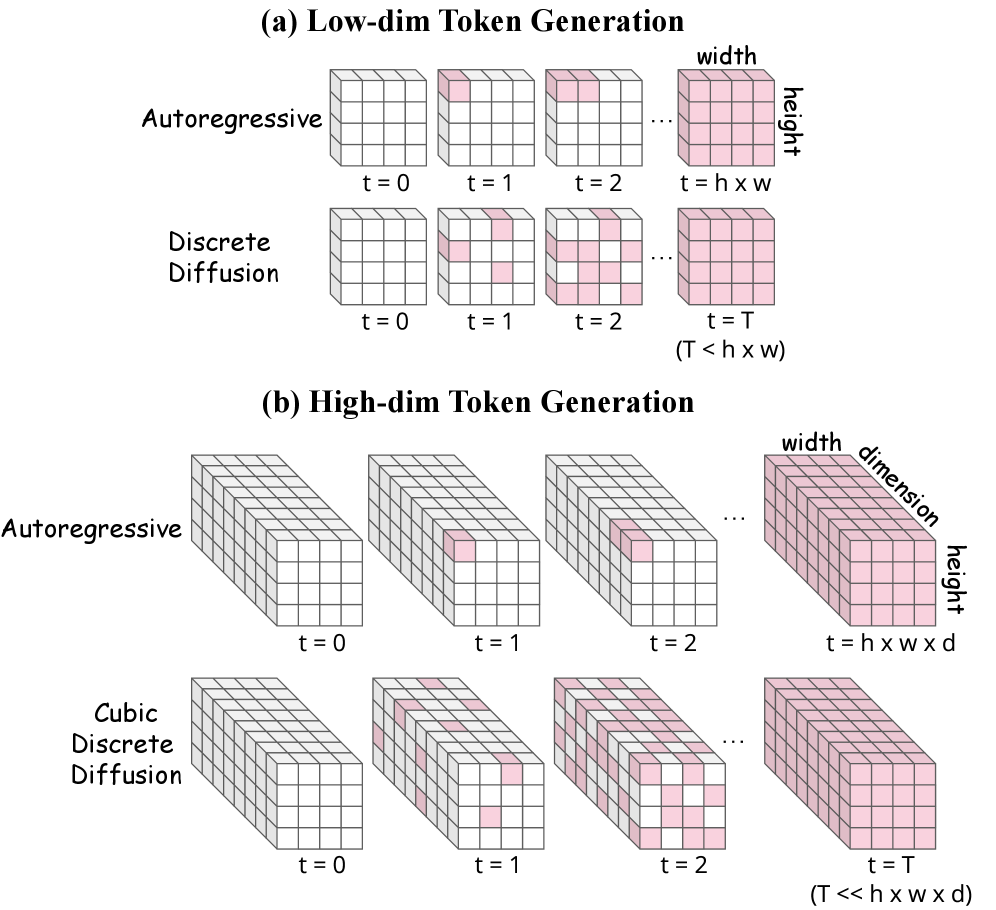
- Cubic Discrete Diffusion (CubiD) : High-dimensional discrete representations의 생성을 위한 masked diffusion model. h×w×d tensor 전체에 걸쳐 fine-grained masking을 수행하여 spatial 및 dimensional dependencies를 효과적으로 모델링한다.
- Fine-grained Masking : CubiD에서 사용되는 마스킹 전략으로, h×w×d tensor의 어떤 spatial position의 어떤 dimension이든 개별적으로 마스킹하고 예측할 수 있다. 이는 intra-position 및 inter-position correlations 학습을 가능하게 한다.
- Fréchet Inception Distance (FID) : 생성된 이미지의 품질과 다양성을 평가하는 Metric으로, 실제 이미지 분포와 생성된 이미지 분포 간의 거리를 측정한다. 낮은 FID 값이 더 좋은 성능을 나타낸다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Unified multimodal modeling을 위한 시도는 language models과 마찬가지로 visual models도 semantically meaningful tokens으로 동작해야 한다는 요구사항을 제기한다. 기존 discrete visual generation methods는 semantic richness를 희생하면서 low-dimensional latent tokens (일반적으로 8-32 dims)에 국한되어 있었다. 반면 high-dimensional pretrained representations (768-1024 dims)는 understanding task에 필수적인 semantic richness를 제공하지만, 이들의 discrete generation은 근본적인 Challenges를 초래한다. 구체적으로, high-dimensional features를 discretize할 때 Vector Quantization(VQ)은 curse of dimensionality 로 인해 효과적이지 않아 representation quality를 저하시키며. 또한, dimension-wise quantization을 통해 생성된 대량의 discrete tokens (예: 16×16×768 configuration에서 196,608개)를 direct sequential generation 방식으로 모델링하면 O(hwd) steps가 필요하여 intractable하다 [cite: 1, Figure 1]. 기존 discrete diffusion methods는 intra-position dimensional dependencies를 capture하지 못하는 한계가 있었다 [cite: 1, Figure 1].
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 high-dimensional representation tokens의 discrete visual generation을 가능하게 하는 Cubic Discrete Diffusion (CubiD) 을 제안한다. CubiD는 frozen pretrained encoder로부터 얻은 continuous high-dimensional features를 dimension-wise quantization (DQ) 을 통해 h×w×d discrete tokens으로 변환하는 것으로 시작한다 [cite: 1, Figure 3]. 이 DQ 방식은 high-dimensional space에서도 original continuous features의 semantic quality를 거의 동일하게 유지함을 LLaVA benchmarks를 통한 multimodal understanding tasks에서 입증했다. SigLIP2 features를 사용한 실험에서 SigLIP2-DQ는 GQA에서 63.1 , TextVQA에서 59.8 의 성능을 기록하여 Continuous features (GQA 63.2 , TextVQA 59.6 )와 거의 동일한 수준을 보였으나, VQ는 모든 Metric에서 심각한 Degradation을 보였다 [cite: 1, Table 3].
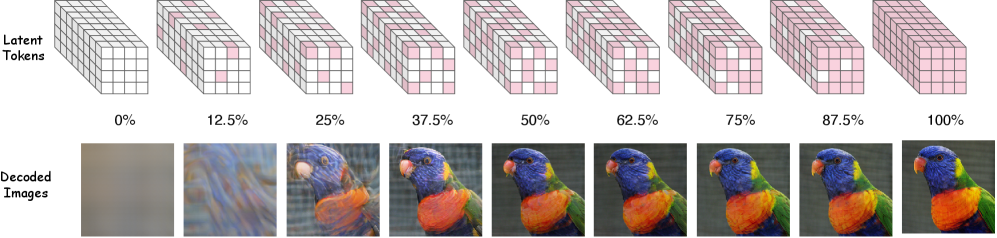
CubiD의 핵심은 h×w×d tensor 전체에 걸쳐 fine-grained masking 을 수행하는 것이다. 이는 기존 MaskGIT과 같이 entire spatial positions를 masking하는 것과 달리, 어떤 spatial position의 어떤 dimension이든 독립적으로 masking하고 부분 관측으로부터 예측하도록 모델을 학습시킨다 [cite: 1, Figure 3]. 이를 통해 model은 intra-position correlation(spatial location 내 dimensions 간의 관계)과 inter-position patterns(features가 공간적으로 전파되는 방식) 모두를 학습할 수 있다. Inference 과정에서 CubiD는 fully masked tensor에서 시작하여 iterative refinement를 통해 progressive unmasking을 수행한다 [cite: 1, Figure 4]. 이 병렬적인 접근 방식은 feature dimensionality d에 관계없이 고정된 수의 Steps T (일반적으로 수백 Steps)만으로 generation이 가능하게 하여, O(hwd) Steps가 필요한 autoregressive methods에 비해 Computational efficiency를 크게 향상시킨다.
Ablation study를 통해 masking strategy의 중요성을 확인했다. Per-element masking (CubiD의 접근 방식)은 gFID 5.33 으로 가장 우수한 성능을 보였다. 반면 Per-spatial masking은 gFID 22.22 로, Per-dim masking은 gFID 120.03 으로 성능이 크게 저하되어, fine-grained masking의 필요성을 검증했다 [cite: 1, Table 4(b), Figure 5]. CubiD는 ImageNet 256×256 class-conditional generation에서 3.7B Parameters 모델인 CubiD-XXL이 state-of-the-art discrete generation 성능인 gFID 1.88 을 달성했다 [cite: 1, Table 5]. 이는 768d high-dimensional tokens를 직접 사용하여 얻은 결과이며, 대부분 32d 이하의 low-dimensional tokens를 사용하는 기존 discrete diffusion 및 autoregressive methods를 능가한다 [cite: 1, Table 5]. CubiD는 900M 에서 3.7B Parameters로 Model size가 증가함에 따라 gFID가 5.25 에서 4.68 로 지속적으로 감소하는 강력한 scaling behavior를 보였다 [cite: 1, Table 4(e)]. 또한 DINOv2 및 SigLIP2 encoders 모두에서 일관된 성능을 보이며 Approach의 Robustness를 입증했다 [cite: 1, Table 4(f)].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 native high-dimensional representation tokens를 직접 모델링하는 최초의 discrete generative model인 CubiD 를 제안한다. CubiD는 h×w×d spatial-dimensional tensor 전체에 걸친 fine-grained masking 을 통해 수십만 개의 sequential tokens 생성이라는 intractable 문제를 parallel iterations로 변환함으로써 해결했다. 이 연구는 compression이나 reorganization 없이 original representation space에서 standard cross-entropy loss를 사용하여 high-dimensional tokens라는 challenging regime에서도 state-of-the-art discrete generation 결과를 달성했음을 보여준다. Native representation ability의 보존은 동일한 discrete tokens가 understanding 및 generation tasks 모두에 활용될 수 있게 하여, tasks별로 분리된 tokenization schemes의 필요성을 없앤다. 이는 future research가 unified multimodal architectures를 향해 나아가는 데 중요한 영감을 제공할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] Cognitive Mismatch in Multimodal Large Language Models for Discrete Symbol Understanding
- 현재글 : [논문리뷰] Cubic Discrete Diffusion: Discrete Visual Generation on High-Dimensional Representation Tokens
- 다음글 [논문리뷰] EffectErase: Joint Video Object Removal and Insertion for High-Quality Effect Erasing
댓글