[논문리뷰] Cognitive Mismatch in Multimodal Large Language Models for Discrete Symbol Understanding
링크: 논문 PDF로 바로 열기
저자: Junnan Dong, Daixian Liu, Peng Xing, et al.
1. Key Terms & Definitions
- MLLMs (Multimodal Large Language Models) : 텍스트 외에 이미지와 같은 다양한 모달리티를 처리하고 추론할 수 있는 인공지능 시스템입니다.
- Discrete Symbols : 수학 공식, 화학 구조, 언어 문자 등 인간 인지의 근본적인 구성 요소로, 연속적인 시각 데이터와 달리 정밀하고 심층적인 해석을 요구합니다.
- Cognitive Mismatch : MLLM에서 관찰되는 현상으로, 모델이 기본적인 심볼 인식(perception)에는 실패하지만 복잡한 추론 태스크에서는 성공하여, 진정한 시각적 인지보다는 linguistic probability에 의존함을 시사합니다.
- Recognition-Reasoning Inversion : Cognitive Mismatch의 특정 형태로, MLLM이 기초적인 인지 인식 태스크(Level 1)보다 고수준의 추론 태스크(Level 2 및 Level 3)에서 더 나은 성능을 보이는 현상입니다.
- Discrete Semantic Spaces : 의미가 심볼의 정확한 식별 및 조합적 관계에서 발생하는, 의미론적으로 독립적인 심볼 단위들로 구성된 공간을 의미하며, 자연 이미지의 연속적인 시맨틱 공간과 대조됩니다.
2. Motivation & Problem Statement
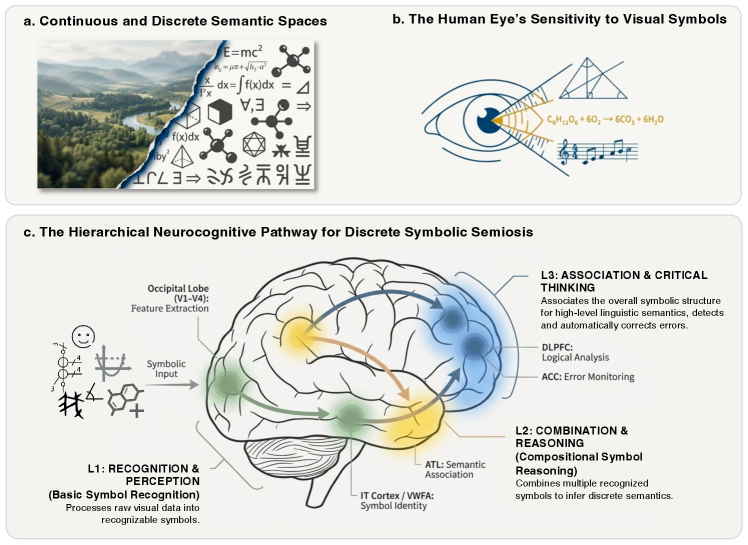
Multimodal Large Language Models (MLLMs)는 자연스러운 장면 해석에서 놀라운 성공을 거두었지만, 인간 인지의 기본 구성 요소인 Discrete Symbols 처리 능력은 여전히 중요한 미해결 과제로 남아 있습니다. 기존 MLLMs는 주로 자연 이미지와 같은 연속적인 시각 신호를 처리하도록 최적화되어 있으며, Image Captioning, Visual Question Answering (VQA) 등의 태스크를 통해 연속적인 시맨틱 서사를 생성하는 데 중점을 둡니다. 그러나 수학 방정식이나 화학 구조 다이어그램과 같은 Discrete Symbols 은 각 심볼을 개별적인 의미론적 개체로 정확하게 인식하고 그 구조화된 구성에 대해 추론해야 하므로, 기존 모델의 연속적인 시각 처리 방식과는 근본적인 Representational Gap이 존재합니다 [cite: 1, Figure 1].
이러한 Representational Gap은 현재 MLLM의 심볼 처리 능력에 심각한 한계를 야기하며, 기존 벤치마크들이 주로 자연 이미지 이해에 초점을 맞춰 구조화되고 추상적인 심볼 시스템을 간과한다는 문제점이 있습니다. 저자들은 MLLM이 진정으로 인간과 유사한 사고방식으로 추론하도록 발전시키기 위해서는 인간의 심볼 처리 메커니즘(인식, 조합, 연상)에 영감을 받아 이산 심볼 시각 정보 처리 방식을 이해하는 것이 필수적이라고 강조합니다.
3. Method & Key Results
저자들은 MLLM의 시각적 심볼 처리 능력을 체계적으로 평가하기 위해 Discrete Semantic Spaces 에서의 성능을 측정하는 포괄적인 벤치마크를 제안합니다. 이 벤치마크는 Language, Culture, Mathematics, Physics, Chemistry의 다섯 가지 상이한 심볼 도메인을 포함하며 [cite: 1, Figure 2], 인간 인지 계층 구조에 영감을 받아 세 가지 인지 수준으로 구성됩니다:
- Recognition and Perception : 기본적인 심볼 primitive를 식별하는 능력.
- Compositional Reasoning : 도메인 지식에 따라 심볼을 통합하고 해석하는 능력.
- Associative and Critical Cognition : 불일치를 감지하고, 잘못 형성된 심볼을 수정하며, 비문자적 또는 문맥 의존적인 의미를 해석하는 능력. 이 프레임워크는 대규모 공개 데이터셋과 인간 전문가의 주석을 통해 구축된 38개의 서브 태스크 와 13,148개의 질문-이미지-답변 쌍 으로 구성된 데이터셋을 활용합니다.
핵심 실험 결과는 다음과 같습니다:
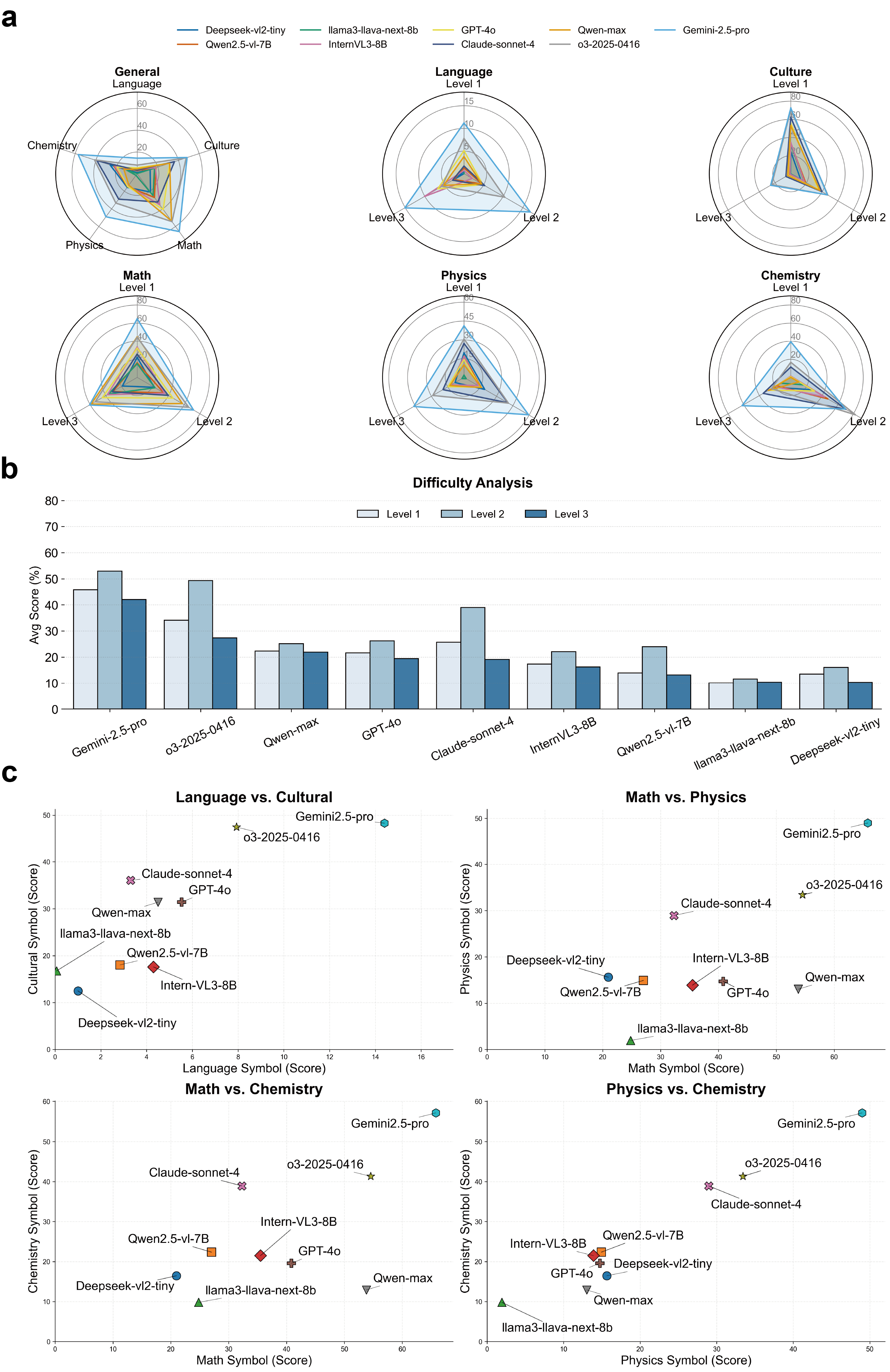
- Cognitive Mismatch와 Recognition-Reasoning Inversion : MLLM은 Recognition-Reasoning Inversion 현상을 보이며, 기본적인 시각적 심볼 인식(Level 1)보다 더 복잡한 추론 태스크(Level 2 및 Level 3)에서 더 나은 성능을 자주 보여줍니다 [cite: 1, Figure 3]. 이는 모델이 견고한 시각적 심볼 Grounding보다는 linguistic prior나 Memorized patterns에 의존하고 있음을 시사합니다. 예를 들어, 수학 도메인의 Level 2 태스크인 Geometric Definition Consistency Check에서 Llama3가 66.7의 Accuracy를 달성했지만, Level 1 태스크인 Function Type Classification에서 Qwen2.5는 37.3점에 불과했습니다.
- 도메인별 성능 불균형 : 대부분의 모델이 심볼 이해에서 불균형한 발전을 보였으며, Language 심볼이 가장 도전적인 도메인인 반면, Mathematics 및 Chemistry와 같은 자연 과학 심볼에서는 상대적으로 더 나은 성능을 보였습니다 [cite: 1, Figure 3]. Gemini-2.5-pro는 Electrical Symbol Recognition (Physics Level 1)에서 60.2%의 Accuracy를 달성하며 뛰어난 시각적 파싱 정밀도를 보여주었으나, LLaMA3-llava-next-8b는 1.8%에 그쳤습니다. Chemistry 도메인에서는 Gemini-2.5-pro가 Element Identification (Level 1)에서 46.1%, Reaction Product Prediction (Level 3)에서 86.7%의 높은 점수를 기록했습니다.
- Procedural Imitation 및 보상 메커니즘 : 모델은 일부 도메인(예: Chemistry, Mathematics)에서 Underlying symbols에 대한 진정한 이해 없이 솔루션 패턴을 성공적으로 재현하는 Procedural Imitation 을 보였습니다. 또한, 강력한 Language Reasoning Capabilities가 시각적 인식 결함을 부분적으로 보상하여 Contextual Inference를 통해 인식 실패를 Masking하는 경향을 나타냈습니다.
- 전 도메인에서의 일관된 우수성 부재 : 어떤 단일 모델도 모든 심볼 도메인에서 일관된 성능을 보이지 않았으며, 이는 현재 모델의 강점이 체계적인 이해보다는 도메인 의존적이고 Data-driven임을 나타냅니다 [cite: 1, Figure 11].
4. Conclusion & Impact
본 연구는 Multimodal Large Language Models (MLLMs)가 Discrete Semantic Spaces 에서 시각적 심볼을 인지하고, 추론하며, 비판적으로 연상하는 능력에 대한 체계적인 조사를 수행했습니다. 연구 결과는 MLLM이 인상적인 추론 능력을 갖추고 있음에도 불구하고, 기본적인 시각적 심볼 Grounding에서 자주 실패하며, 대신 Linguistic Priors, Procedural Imitation 또는 Memorized Patterns에 의존하는 뚜렷한 Cognitive Mismatch 현상을 보인다는 것을 밝혀냈습니다. 이는 시각적 인식이 추론보다 본질적으로 간단하다는 일반적인 가설에 도전하며, 고수준의 추론 성능이 저수준 심볼 인식의 결함을 은폐할 수 있음을 의미하는 Recognition-Reasoning Inversion 현상을 일관되게 관찰했습니다.
이러한 한계는 현재 시각 인코더(예: CLIP-based ViTs)의 연속적인 Representational Bias와 Discrete Semiotics 에 필요한 구성적 엄격성 사이의 근본적인 차이에서 비롯됩니다. 이 연구는 인식, 추론, 비판적 심볼 이해를 명확하게 분리하는 벤치마크의 필요성을 강조하며, 현재의 "language-dominant, vision-passive" 패러다임을 깨고 MLLM을 더 높은 수준의 인지 능력으로 발전시킬 수 있는 방향을 제시합니다. 궁극적으로, 이 연구는 인간과 더 잘 정렬된(Human-aligned) 지능형 시스템 개발을 위한 로드맵을 제공하고, 심볼 이해가 Multimodal Intelligence의 중요한 미개척 분야임을 부각합니다.

⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] ESARBench: A Benchmark for Agentic UAV Embodied Search and Rescue
- [논문리뷰] CodePercept: Code-Grounded Visual STEM Perception for MLLMs
- [논문리뷰] ExpVid: A Benchmark for Experiment Video Understanding & Reasoning
- [논문리뷰] EgoNight: Towards Egocentric Vision Understanding at Night with a Challenging Benchmark
- [논문리뷰] RoboDojo: A Unified Sim-and-Real Benchmark for Comprehensive Evaluation of Generalist Robot Manipulation Policies
Review 의 다른글
- 이전글 [논문리뷰] Bridging Semantic and Kinematic Conditions with Diffusion-based Discrete Motion Tokenizer
- 현재글 : [논문리뷰] Cognitive Mismatch in Multimodal Large Language Models for Discrete Symbol Understanding
- 다음글 [논문리뷰] Cubic Discrete Diffusion: Discrete Visual Generation on High-Dimensional Representation Tokens
댓글