[논문리뷰] Bridging Semantic and Kinematic Conditions with Diffusion-based Discrete Motion Tokenizer
링크: 논문 PDF로 바로 열기
저자: Chenyang Gu, Mingyuan Zhang, Haozhe Xie, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- MoTok : 저자들이 제안하는 Diffusion-based Discrete Motion Tokenizer로, Motion Recovery를 Diffusion Decoder에 위임하여 Semantic Abstraction과 Fine-grained Reconstruction을 분리함으로써, 적은 수의 Token으로 Motion Fidelity를 유지하면서 Compact한 Single-layer Token을 가능하게 한다.
- Perception–Planning–Control (PPC) Paradigm : 조건부 Motion Generation을 위한 3단계 Framework를 지칭한다. Perception은 Condition Feature Extraction을, Planning은 Discrete Token Generation을, Control은 Diffusion-based Motion Synthesis를 담당한다.
- Global Conditions (
c^g) : Text Description이나 Style Label과 같이 Frame-wise Alignment가 필요 없는 Sequence-level Guidance를 제공하는 Condition이다. - Local Conditions (
c^s_{1:T}) : Target Root Trajectory나 Keyframe과 같이 Motion Timeline에 정렬되어 Kinematic Control Signal을 지정하는 Condition이다. - Classifier-free Guidance (CFG) : Token-space Planning 과정에서 Semantic Guidance와 Control Fidelity 간의 균형을 맞추기 위해 사용되는 기법으로, 여러 Condition에 대해 Alternating Guidance Pairs를 통해 확장 적용된다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존의 Motion Generation 연구는 주로 Kinematic Control에 강점을 보이는 Continuous Diffusion Models 또는 Semantic Conditioning에 효과적인 Discrete Token-based Generators의 두 가지 패러다임을 따랐습니다. 그러나 실제 시나리오에서는 High-level Semantic Intent를 유지하면서 Fine-grained하고 Time-varying Kinematic Control Signals을 효과적으로 통합하는 것이 핵심 과제였습니다. 기존 Motion Tokenizers는 High-level Semantics와 Low-level Motion Details를 엮는 경향이 있어, Faithful Reconstruction을 위해 높은 Token Rate 또는 계층적 Code를 요구했습니다. 이는 Downstream Generators에 부담을 가중시키고, Fine-grained Kinematic Condition Signals이 Semantic Conditioning과 충돌하거나 Override할 수 있어 Controllable Generation을 복잡하게 만들었습니다. 결과적으로, Token Efficiency와 Generation Quality 사이의 근본적인 Trade-off가 존재하며, Fine-grained Low-level Control 지원에 한계가 있었습니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 이러한 문제를 해결하기 위해 Perception–Planning–Control 이라는 3단계 Paradigm을 제안합니다
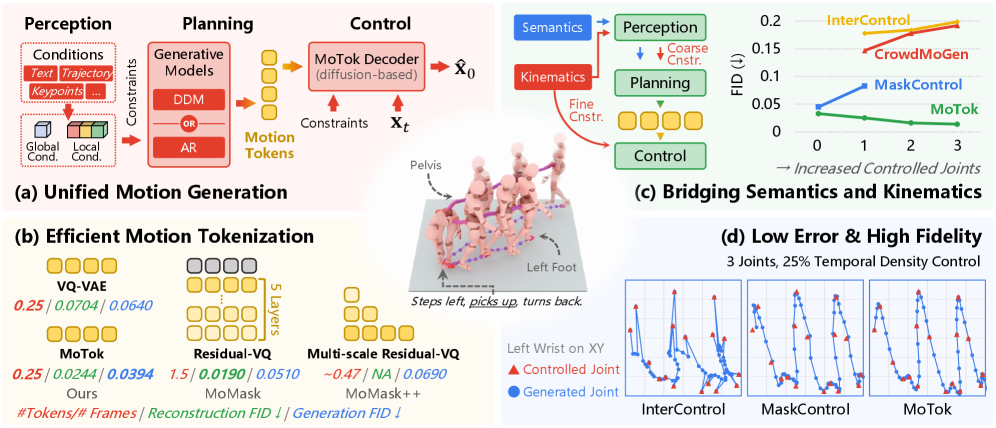
이 Paradigm에서 Perception 단계는 이질적인 Condition들을 Global 또는 Local Condition으로 인코딩하며, Planning 단계에서는 Unified Interface를 통해 Autoregressive (AR) 또는 Discrete Diffusion (DDM) Generator를 사용하여 Discrete Motion Token Sequence를 예측합니다. Control 단계에서는 Diffusion-based Decoding을 통해 최종 Motion을 합성하며, 이 과정에서 Fine-grained Kinematic Constraints를 적용합니다.
이 Framework의 핵심은 MoTok 이라는 Diffusion-based Discrete Motion Tokenizer입니다
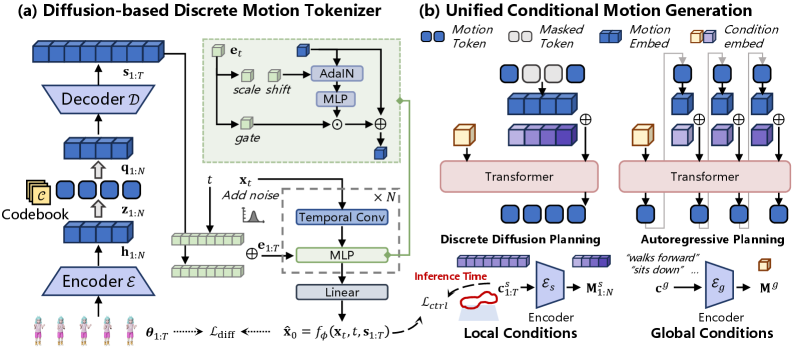
MoTok은 Convolutional Encoder, Vector Quantizer, 그리고 Diffusion-based Reconstruction을 포함하는 Decoder로 구성되어, Semantic Abstraction과 Low-level Reconstruction을 분리합니다. 즉, Motion Recovery를 Diffusion Decoder에 위임함으로써 Discrete Token이 Semantic Structure에 집중할 수 있게 하여 Token Budget을 대폭 줄입니다. 또한, Kinematic Conditions는 Planning 단계에서는 Coarse Constraints로 Token Generation을 유도하고, Control 단계에서는 Diffusion Denoising 시 Optimization-based Guidance를 통해 Fine-grained Constraints로 강화되는 Coarse-to-fine Conditioning Scheme을 제안합니다. 이 설계는 Low-level Kinematic Details가 Token-space Planning에 간섭하는 것을 방지하여 Controllability와 Realism 사이의 Trade-off를 해소합니다.
실험 결과, MoTok은 HumanML3D Dataset에서 MaskControl 대비 Token 사용량을 6분의 1 로 줄이면서도 Controllability와 Fidelity를 크게 향상시켰습니다. Text and Trajectory Control Task에서 Trajectory Error를 0.72 cm에서 0.08 cm 로, FID를 0.083에서 0.029 로 감소시켰습니다.
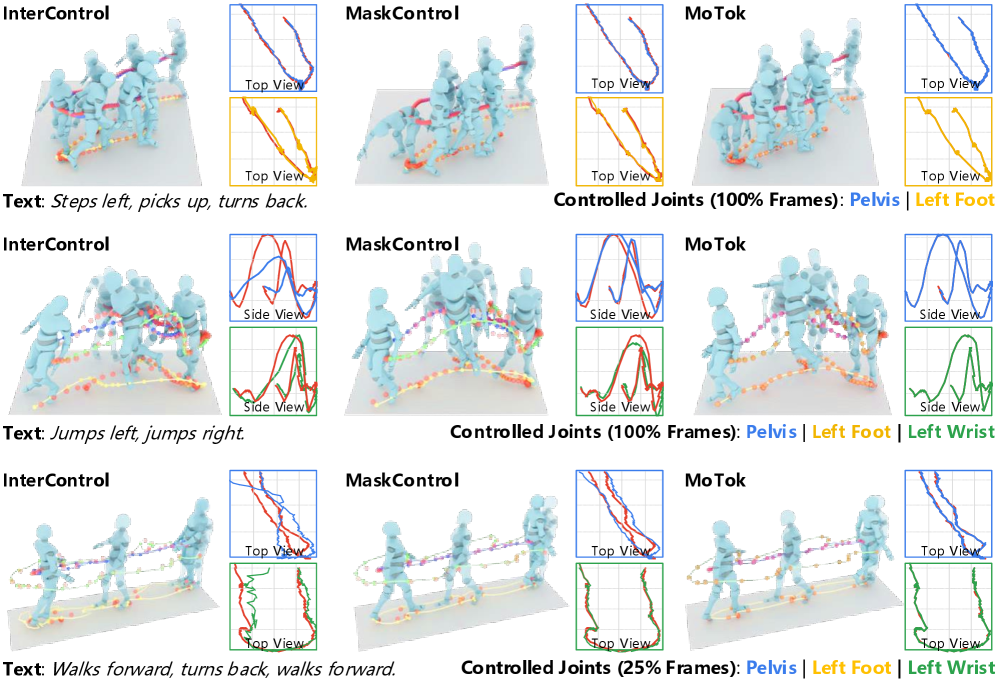
특히, 기존 방법론들이 Kinematic Constraint가 강해질수록 성능이 저하되는 반면, MoTok은 더 강한 Constraint 하에서도 Motion Fidelity를 개선하여 FID를 0.033에서 0.014 로 낮추는 결과를 보였습니다 [cite: 1, Table 1]. Text-to-Motion Task에서도 MoTok-DDM-4는 MoMask 대비 적은 Token Budget으로도 더 낮은 FID ( 0.039 vs. 0.045 )를 달성했으며, MoTok-DDM-2는 0.033 으로 모든 비교 방법론 중 가장 우수한 FID를 기록했습니다 [cite: 1, Table 2]. KIT-ML Dataset에서도 MoTok은 가장 낮은 FID인 0.144 를 달성하며 경쟁력 있는 성능을 입증했습니다 [cite: 1, Table 2].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Kinematic Control에 강한 Continuous Diffusion Models와 Semantic Conditioning에 효과적인 Discrete Token-based Generators의 장점을 성공적으로 결합하는 Framework를 제안했습니다. 핵심적으로 제안된 MoTok 은 Diffusion-based Decoding에 Low-level Reconstruction을 위임함으로써, Compact하면서도 Semantically Informative한 Token을 가능하게 하는 Diffusion-based Discrete Motion Tokenizer입니다. 이 3단계 Perception–Planning–Control Paradigm은 적극적인 Token Compression 하에서도 강력한 성능을 보여주며, Text and Trajectory Controllable Generation에서 Trajectory Error를 0.72 cm에서 0.08 cm 로 대폭 줄였습니다. 이 연구는 애니메이션, 로봇 공학 및 Embodied Agent와 같은 분야에서 Motion Generation의 효율성과 정확성을 크게 향상시킬 수 있는 새로운 방향을 제시하며, Semantics와 Kinematics를 통합하는 데 중요한 진전을 이루었습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] DrawMotion: Generating 3D Human Motions by Freehand Drawing
- [논문리뷰] Causal Motion Diffusion Models for Autoregressive Motion Generation
- [논문리뷰] The Quest for Generalizable Motion Generation: Data, Model, and Evaluation
- [논문리뷰] SynCity 3000: Bootstrapping Scene-Scale 3D Diffusion
- [논문리뷰] MV-Forcing: Long Multi-View Video Generation via 4D-Grounded Spatio-Temporal Self-Forcing
Review 의 다른글
- 이전글 [논문리뷰] 3DreamBooth: High-Fidelity 3D Subject-Driven Video Generation Model
- 현재글 : [논문리뷰] Bridging Semantic and Kinematic Conditions with Diffusion-based Discrete Motion Tokenizer
- 다음글 [논문리뷰] Cognitive Mismatch in Multimodal Large Language Models for Discrete Symbol Understanding
댓글