[논문리뷰] 3DreamBooth: High-Fidelity 3D Subject-Driven Video Generation Model
링크: 논문 PDF로 바로 열기
저자: Hyun-kyu Ko, Jihyeon Park, Younghyun Kim, Dongheok Park, Eunbyung Park, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- 3DreamBooth : 고충실도(high-fidelity) 3D identity를 Video Diffusion Models에 주입하기 위한 새로운 optimization paradigm입니다. 이는 1-frame optimization strategy를 통해 spatial identity를 temporal dynamics로부터 분리합니다.
- 3Dapter : Multi-view conditioning module로, 타겟 subject의 spatial features를 generation process에 직접 주입하여 fine-grained texture를 강화하고 convergence를 가속화합니다.
- 1-frame optimization paradigm : Video Diffusion Transformer (DiT)에서 input을 단일 프레임(T=1)으로 제한함으로써 temporal attention mechanism을 자연스럽게 우회하고, gradient updates를 spatial representation에만 집중시켜 3D identity를 학습하는 전략입니다. 이는 pre-trained motion priors를 보존합니다.
- Multi-View Joint Attention : 3DreamBooth와 3Dapter의 joint optimization 단계에서 사용되는 메커니즘입니다. 이는 dynamic selective router 역할을 하여 multi-view reference conditions에서 relevant한 view-specific geometric hints를 선택적으로 쿼리하고 추출합니다.
- 3D-CustomBench : 3D-aware customized video generation 태스크를 평가하기 위해 고안된 새로운 benchmark suite입니다. 복잡한 3D 구조와 고해상도 texture를 가진 30개의 object로 구성되어 있습니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Immersive VR/AR, virtual production, next-generation e-commerce 등 다양한 분야에서 customized subject의 dynamic하고 view-consistent한 비디오 생성에 대한 수요가 증가하고 있습니다. 그러나 기존 subject-driven video generation 방법론들은 주로 subject를 2D entity로 취급하며, single-view visual features나 textual prompts를 통해 identity를 전이하는 데 초점을 맞추고 있습니다. 이 2D-centric 접근 방식은 실제 subject가 본질적으로 3D라는 점에서 한계를 드러냅니다. 즉, 3D geometry를 재구성하는 데 필요한 comprehensive spatial priors가 부족하여, novel views를 합성할 때 true 3D identity를 보존하기보다는 그럴듯하지만 임의의(arbitrary) 세부 사항을 생성하게 됩니다.
진정한 3D-aware customization을 달성하는 것은 multi-view video dataset의 부족으로 인해 여전히 어렵습니다. 제한된 비디오 시퀀스로 모델을 fine-tune하려는 시도는 종종 temporal overfitting으로 이어지는 문제가 있습니다. 또한, 기존의 text-driven customization 방법은 text embedding의 inherent information bottleneck으로 인해 fine-grained details를 포착하기 어렵고, optimization process가 비효율적이라는 단점이 있습니다 [cite: 1, Figure 3]. 저자들은 이러한 문제들을 해결하기 위해 3D geometry를 보존하면서 고품질의 3D-aware 비디오를 효율적으로 생성할 수 있는 새로운 프레임워크의 필요성을 제기합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
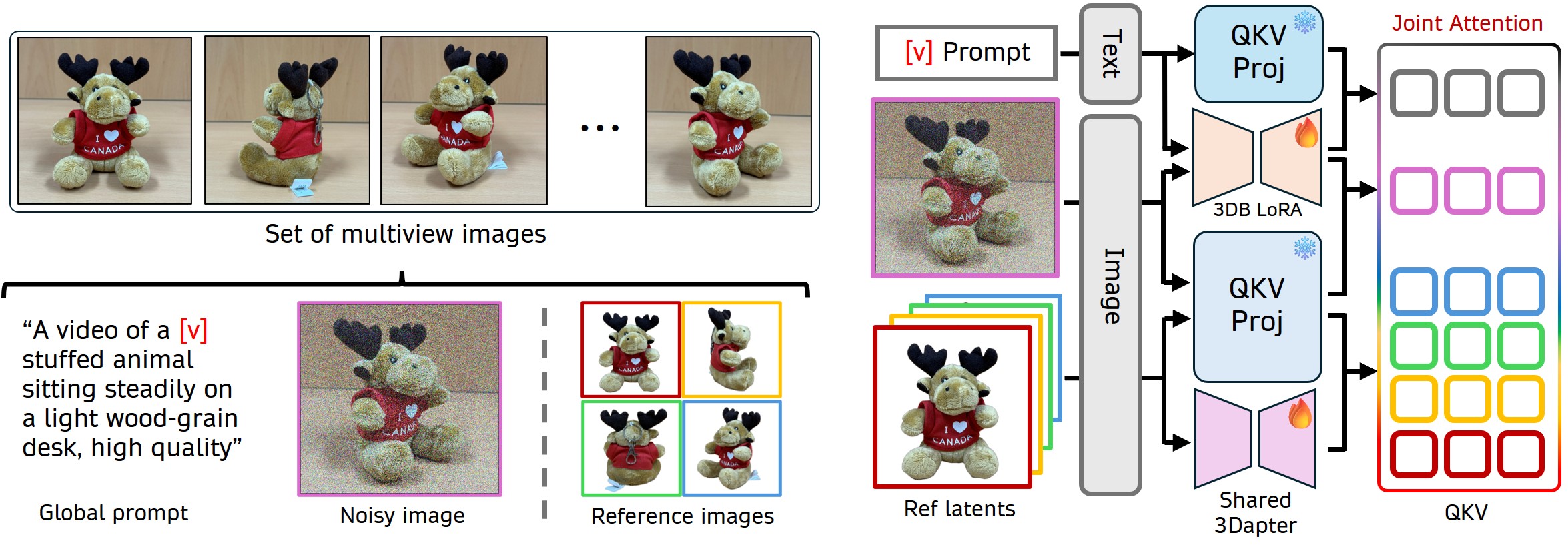
본 논문에서는 3D-aware video customization을 위한 새로운 프레임워크인 3DreamBooth 와 3Dapter 를 제안합니다. 이 프레임워크는 optimization-based personalization과 adapter-based conditioning을 통합합니다 [cite: 1, Figure 1].
3DreamBooth 는 LoRA를 통해 generative backbone (HunyuanVideo-1.5 기반)을 fine-tune하여 subject의 3D identity를 내재화합니다. 기존 비디오 시퀀스 전체를 사용하여 훈련하는 것은 spatial identity와 temporal dynamics를 얽히게 하여 특정 motion patterns에 overfitting될 위험이 있습니다. 이를 방지하기 위해 3DreamBooth는 1-frame training paradigm을 채택합니다 [cite: 1, Figure 2]. Input을 단일 프레임(T=1)으로 제한함으로써 temporal attention pathway가 자연스럽게 우회되어, 학습이 spatial attributes에만 집중되고 모델의 pre-trained motion priors는 보존됩니다. 각 multi-view 이미지 s(i)는 unique identifier VV와 class noun CC를 포함하는 universal text prompt p와 쌍을 이룹니다. 이 consistent prompt는 모델이 multi-view spatial variations를 identifier token VV에 직접 내재화하도록 합니다.
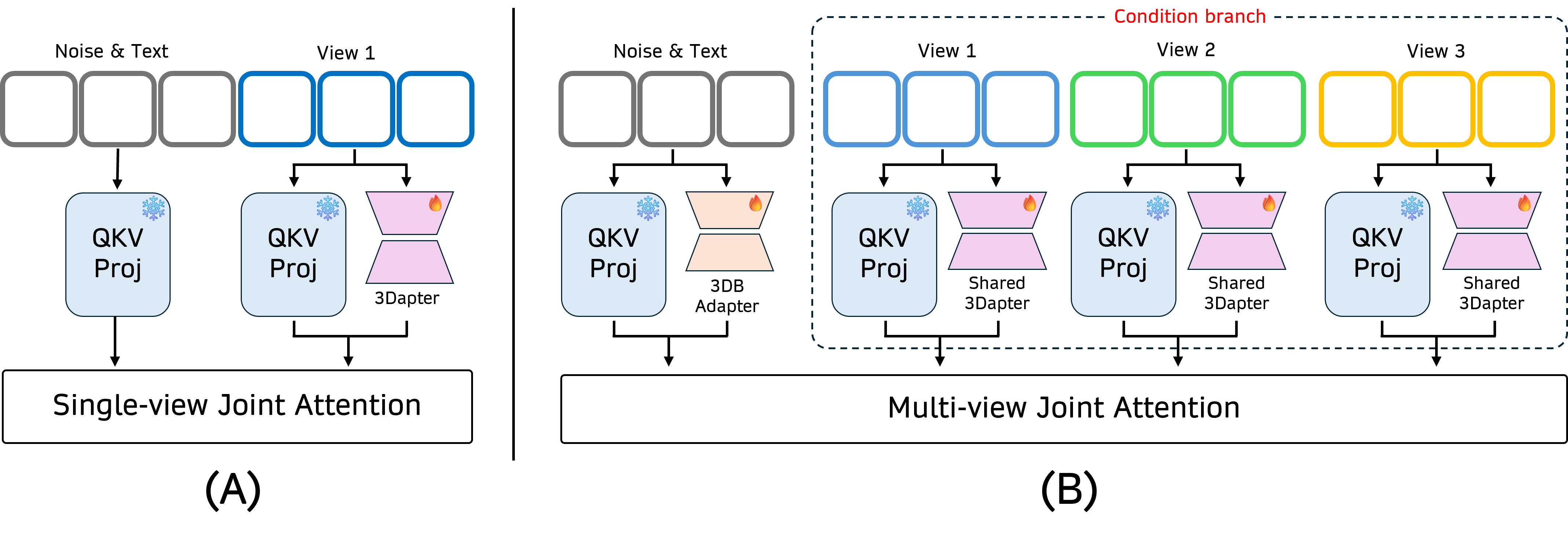
3Dapter 는 3DreamBooth의 한계점, 즉 text-driven customization의 느린 optimization과 fine-grained details 손실을 극복하기 위해 제안된 multi-view conditioning module입니다. 3Dapter는 두 단계의 훈련 pipeline을 거칩니다 [cite: 1, Figure 4]:
- Single-view Pre-training : OminiControl과 같은 controllable DiT의 visual adapter 패러다임에서 영감을 받아 Subjects200K 데이터셋으로 pre-train됩니다. 이는 3Dapter가 단일 reference image로부터 subject-specific spatial features를 robust하게 추출하고 주입하는 능력을 학습하도록 합니다 [cite: 1, Figure 4].
- Multi-view Joint Optimization : Pre-training 이후, 3DreamBooth와 3Dapter는 특정 subject adaptation을 위해 함께 fine-tune됩니다. 이 단계에서는 최소한의 conditioning views (N_c=4)가 3Dapter에 입력되어 Multi-view Joint Attention을 통해 conditioning을 제공합니다. 3Dapter는 dynamic selective router 역할을 하여 current target view를 재구성하는 데 필요한 relevant, view-specific geometric hints만을 쿼리하고 추출합니다 [cite: 1, Figure 4, Figure 5].
이러한 synergy 덕분에 3Dapter는 strong textural 및 high-frequency priors를 제공하여 전반적인 optimization 부담을 크게 줄입니다. 그 결과, 제안된 프레임워크는 빠른 convergence와 high-fidelity detail preservation을 달성합니다.
핵심 결과 : 정량적 평가에서, 제안된 full model ( 3Dapter+3DB )은 Multi-View Subject Fidelity 측면에서 기존 SOTA(state-of-the-art) 모델들을 능가합니다. 특히 GPT-4o 기반의 human-centric metrics에서 Shape (4.80) , Color (4.53) , Detail (4.04) , Overall (4.57) 에서 가장 높은 점수를 기록했습니다 [cite: 1, Table 1]. 3D Geometric Fidelity 평가에서는 Chamfer Distance (CD)가 0.0177 로, 가장 경쟁력 있는 single-view 방법인 Phantom ( 0.0338 ) 대비 거의 절반 수준의 오류를 보여주며 월등한 성능을 입증했습니다 [cite: 1, Table 2]. Completeness 지표에서도 0.0172 로 크게 앞서, multi-view conditioning이 360° geometry를 효과적으로 복구함을 나타냅니다 [cite: 1, Table 2]. 또한, 3Dapter를 통합함으로써 3DreamBooth 단독 모델 대비 convergence 속도가 현저히 가속화되는 것이 확인되었습니다 [cite: 1, Figure 3]. Video Quality 및 Text Alignment 측면에서도 기존 방법들과 동등하거나 우수한 성능을 유지하며, 특히 Imaging Quality에서 outperform하고 ViCLIP scores도 경쟁력을 보였습니다 [cite: 1, Table 3].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 3D-aware video customization을 위한 효율적인 프레임워크인 3DreamBooth 와 3Dapter 를 성공적으로 도입했습니다. 3DreamBooth의 1-frame optimization을 통해 spatial identity를 temporal motion으로부터 효과적으로 분리하여 subject-specific 3D priors를 temporal overfitting 없이 모델에 주입합니다. 추가적으로, multi-view conditioning module인 3Dapter는 dynamic selective router 역할을 수행하여 relevant geometric features를 명시적으로 추출하고 intricate textures를 보존합니다 [cite: 1, Figure 5].
저자들은 자체 구축한 벤치마크인 3D-CustomBench 를 통해 광범위한 평가를 수행했으며, 본 synergistic 접근 방식이 state-of-the-art 수준의 3D geometric fidelity와 빠른 convergence를 달성함을 입증했습니다 [cite: 1, Table 1, Table 2, Figure 3]. 이 연구는 immersive VR/AR, virtual production, 광고, next-generation e-commerce 등 다양한 응용 분야에서 customized 3D subject를 dynamic한 환경에 고충실도로 통합할 수 있는 길을 열어줄 것으로 기대됩니다. 특히, 기존 2D-centric 방법론들의 한계를 극복하고 진정한 3D-aware customization을 가능하게 했다는 점에서 학계 및 산업계에 큰 시사점을 제공합니다.

⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Program-as-Weights: A Programming Paradigm for Fuzzy Functions
- [논문리뷰] Discrete Diffusion Language Models for Interactive Radiology Report Drafting
- [논문리뷰] DreamForge-World 0.1 Preview: A Low-Compute Real-Time Controllable World Model
- [논문리뷰] The Tatoxa System for Text Detoxification in Low-Resource Languages: The Case of Tatar
- [논문리뷰] The Hidden Power of Scaling Factor in LoRA Optimization
Review 의 다른글
- 이전글 [논문리뷰] When AI Navigates the Fog of War
- 현재글 : [논문리뷰] 3DreamBooth: High-Fidelity 3D Subject-Driven Video Generation Model
- 다음글 [논문리뷰] Bridging Semantic and Kinematic Conditions with Diffusion-based Discrete Motion Tokenizer
댓글