[논문리뷰] MultiBind: A Benchmark for Attribute Misbinding in Multi-Subject Generation
링크: 논문 PDF로 바로 열기
저자: Qiang Liu, Lihua Zhang, Hanyi Mao, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Cross-subject Attribute Misbinding : Multi-reference, multi-subject 이미지 생성 과정에서 특정 subject의 attribute가 다른 subject에게 잘못 보존, 편집 또는 전이되는 실패 모드.
- MultiBind : 실존하는 다중 인물 사진을 기반으로 구축된 벤치마크로, 명시적인 subject correspondence supervision을 통해 다중 subject 제어 능력을 평가하도록 설계되었다.
- Dimension-wise Confusion Evaluation Protocol :
face identity,appearance,pose,expression과 같은 각 attribute 차원에 특화된 specialist를 사용하여 생성된 subject와 ground-truth subject 간의 유사도 행렬을 계산하고, ground-truth 유사도를 빼어drift,swap,dominance,blending과 같은 실패 패턴을 진단하는 평가 방법론. - Drift : 생성된 subject가 다른 subject와 혼동되지 않고 자신의 ground-truth target으로부터 이탈하는 실패 패턴.
- Blending : Attribute가 여러 subject에 걸쳐 혼합되는 실패 패턴.
- Swap : 최소한 하나의 off-diagonal confusion link를 포함하는 permutation과 유사한 할당 오류를 나타내는 실패 패턴.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 multi-reference image generation 시스템은 하나의 이미지 내에서 여러 entity를 세밀하게 제어하는 기능에 대한 기대를 높이고 있다. 그러나 이러한 multi-subject 환경에서 발생하는 주요 실패 모드는 cross-subject attribute misbinding으로, attribute가 잘못된 subject에 전이되거나 혼합되는 현상이다. 기존의 benchmark 및 metric은 주로 holistic fidelity 또는 per-subject self-similarity에 중점을 두어 이러한 미묘한 binding failure를 진단하기 어렵다.
특히, 기존 평가 방식은 '누가 누구와 혼동되는지'를 파악하거나, 일반적인 품질 저하(drift)와 cross-subject interference를 구별할 수 있는 quantitative indicator를 제공하지 못했다. 또한, 일부 benchmark는 synthetic target을 사용하거나 paired ground-truth image 없이 judge-based scoring에 의존하여, complex prompt에 대한 internal consistency 보장과 reproducible similarity-based scoring에 한계가 있었다. 이러한 한계점들은 real target에 기반하고 명시적인 subject correspondence supervision을 제공하는 새로운 benchmark의 필요성을 제기한다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
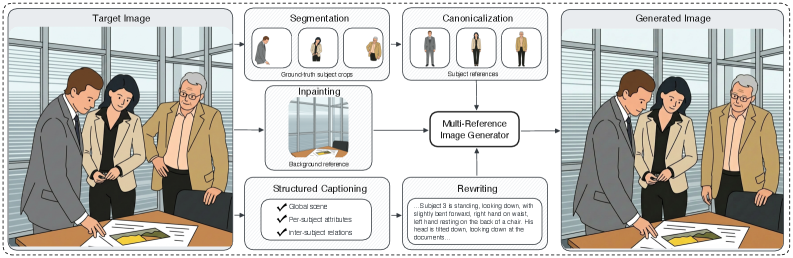
저자들은 long-prompt, multi-subject controllability를 명시적인 subject correspondence supervision으로 평가하기 위한 MultiBind 벤치마크를 제안한다. 각 instance는 고유한 real target image에 기반하며, per-subject ground-truth crops (마스크 및 bounding box 포함), canonicalized subject reference images, inpainted background reference, 그리고 구조화된 주석(structured annotations)으로 구성된 entity-indexed prompt를 제공한다 [cite: 1, Figure 2].
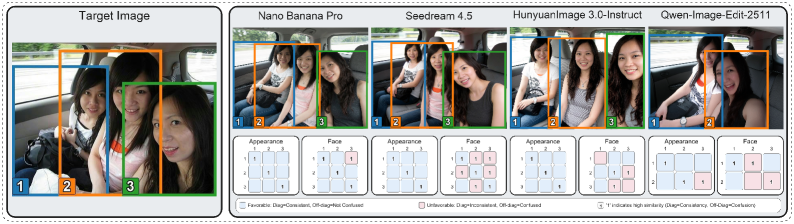
MultiBind 평가 프로토콜은 dimension-wise confusion evaluation을 통해 subject-attribute misbinding을 직접 측정한다. 이 프로토콜은 face identity, appearance, pose, expression 등 네 가지 attribute dimension에 대한 specialist를 사용하여 생성된 subject와 ground-truth subject 간의 subject-to-subject similarity matrices를 계산한다. generation으로 인해 발생하는 변화를 분리하기 위해, ground-truth subject 간의 내재된 유사도를 generation된 유사도에서 빼 baseline-corrected delta matrices (Δ(d))를 산출한다. 이 delta matrices는 self-degradation (대각선 항목)과 cross-subject interference (비대각선 항목)를 구분하여 drift, swap, dominance, blending과 같은 interpretable failure patterns를 진단한다.
실험 결과, Nano Banana Pro와 GPT-Image-1.5는 holistic metrics (FID, CLIP-I, DINO, AES)에서 open-source 모델을 능가하며 가장 강력한 전반적인 재구성 성능을 보였다 [cite: 1, Table 3]. 특히, Nano Banana Pro는 FID, CLIP-I, DINO, global JS에서 최고의 성능을 달성했으며, GPT-Image-1.5는 가장 높은 AES와 matched subject slot 수를 기록했다 [cite: 1, Table 3].
failure-pattern diagnosis 결과에 따르면 [cite: 1, Table 4]:
- Nano Banana Pro 와 GPT-Image-1.5 는 거의 모든
dimension에서 가장 높은Success비율과 가장 낮은structured-pattern비율을 유지하며 가장 안정적인binding성능을 보였다. - Seedream 4.5 는
facedimension에서blending53.7%,dominance14.5%를 기록하며mixing-heavy경향을 보였다. 이는facial information이 보존되지만 잘못된subject에binding되는 경향이 있음을 시사한다. - Hunyuan-Image-3.0-Instruct 는
face inconsistency56.3%,drift45.6%로drift-heavy경향을 나타내었으며,face preservation능력이 약함을 보여주었다. - Qwen-Image-Edit-2511 와 OmniGen2 는
appearance및expressiondimension에서 높은swap(22.9%, 18.9%),dominance(18.7%, 19.5%),blending(43.4%, 50.2%) 비율과 낮은Success비율을 기록하며 불안정한binding성능을 보였다.
이러한 binding diagnostics는 holistic metrics만으로는 놓칠 수 있는 severe mixing 또는 drift patterns를 명확히 밝혀내며, binding metrics가 holistic evaluation에 대한 보완적인 관점으로서의 가치를 강조한다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 복잡한 지침 하에 multi-reference, multi-subject image generation을 평가하기 위한 MultiBind 벤치마크를 제안한다. MultiBind는 포괄적인 주석(masks, crops, references)과 구조화된 프롬프트를 통해 deterministic slot correspondence를 확립함으로써 reference preservation과 edit accuracy를 정밀하게 평가할 수 있도록 한다.
또한, 저자들은 specialist-based, dimension-wise confusion evaluation protocol을 도입하여 self-degradation과 cross-subject interference를 명확히 분리한다. 이를 통해 drift, swap, dominance, blending과 같은 interpretable failure modes를 식별하고 정량화할 수 있다. modern generators에 대한 평가 결과는 MultiBind의 metrics가 human judgment와 잘 일치하며, holistic scores에 의해 가려지기 쉬운 중요한 subject-attribute binding failures를 효과적으로 드러낸다는 것을 입증했다. 이 연구는 multi-subject image generation 시스템의 강점과 약점에 대한 깊은 통찰력을 제공하여, 이 분야의 학계 및 산업계 연구자들이 보다 견고하고 제어 가능한 생성 모델을 개발하는 데 중요한 기여를 할 것으로 기대된다.

⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] RoboDojo: A Unified Sim-and-Real Benchmark for Comprehensive Evaluation of Generalist Robot Manipulation Policies
- [논문리뷰] AGVBench: A Reliability-Oriented Benchmark of Data Augmentation for Vein Recognition
- [논문리뷰] QuitoBench: A High-Quality Open Time Series Forecasting Benchmark
- [논문리뷰] ImagenWorld: Stress-Testing Image Generation Models with Explainable Human Evaluation on Open-ended Real-World Tasks
- [논문리뷰] EffectErase: Joint Video Object Removal and Insertion for High-Quality Effect Erasing
Review 의 다른글
- 이전글 [논문리뷰] MinerU-Diffusion: Rethinking Document OCR as Inverse Rendering via Diffusion Decoding
- 현재글 : [논문리뷰] MultiBind: A Benchmark for Attribute Misbinding in Multi-Subject Generation
- 다음글 [논문리뷰] PEARL: Personalized Streaming Video Understanding Model
댓글