[논문리뷰] PEARL: Personalized Streaming Video Understanding Model
링크: 논문 PDF로 바로 열기
저자: Yuanhong Zheng, Ruichuan An, Xiaopeng Lin, Yuxing Liu, Sihan Yang, Huanyu Zhang, Haodong Li, Qintong Zhang, Renrui Zhang, Guopeng Li, YiFan Zhang, Yuheng Li, Wentao Zhang
1. Key Terms & Definitions (핵심 용어 및 정의)
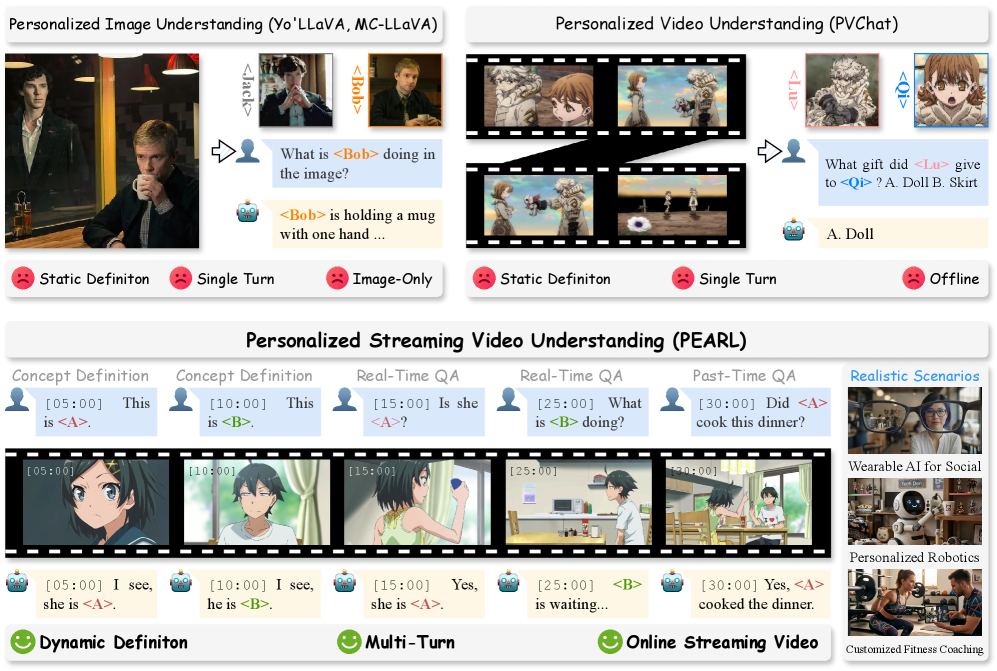
- Personalized Streaming Video Understanding (PSVU) : 지속적인 비디오 스트림을 실시간으로 처리하여 사용자 정의(user-defined)된, 개인화된(personalized) 개념을 인식하고 상호작용하는 새로운 태스크입니다.
- PEARL-Bench : PSVU 태스크 평가를 위해 고안된 최초의 포괄적인 벤치마크로, Frame-level 및 Video-level 개인화, 다중 턴(multi-turn) 상호작용 및 정밀한 타임스탬프 기반 평가를 지원합니다.
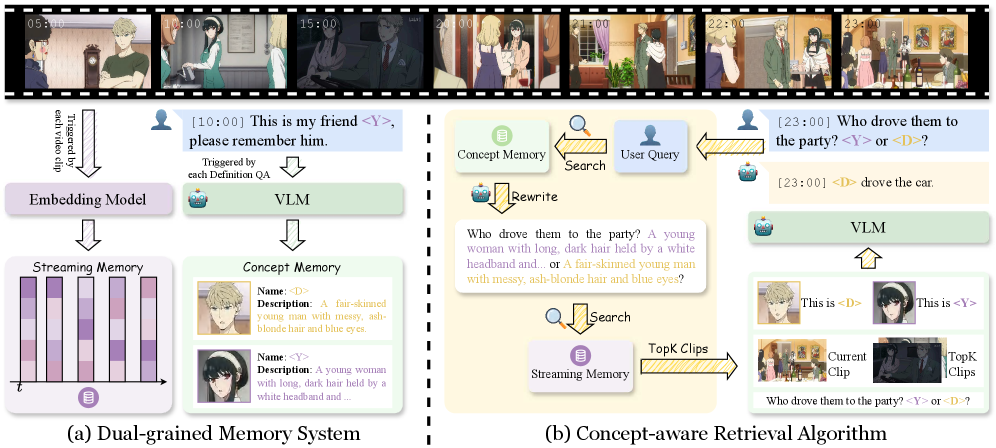
- Dual-grained Memory System : PEARL 프레임워크의 핵심 메모리 아키텍처로,
Concept Memory(사용자 정의 개념 저장)와Streaming Memory(분할된 비디오 클립 및 멀티모달 임베딩 아카이빙)를 명시적으로 분리합니다. - Concept-aware Retrieval Algorithm : PEARL 내의 효율적인 알고리즘으로, 개념 설명을 활용하여 쿼리(query)를 재작성하고
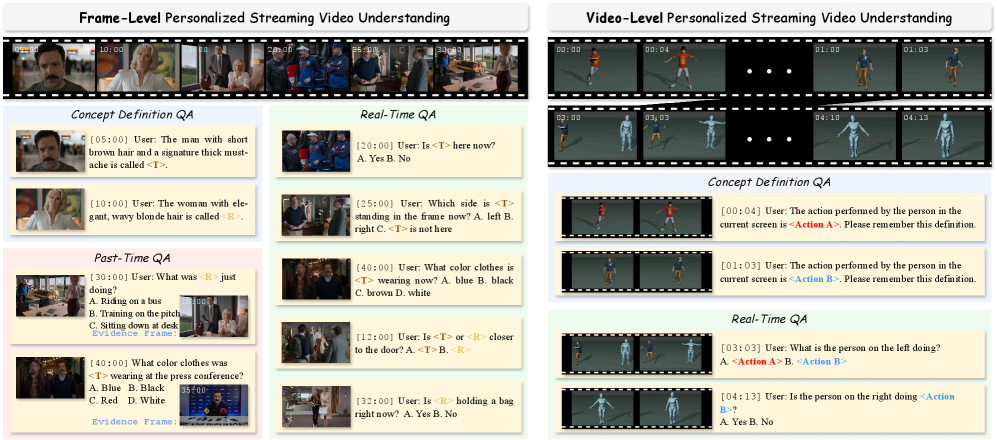
Streaming Memory에서 관련 과거 시각적 증거(historical visual evidence)를 검색하여 정확한 응답을 생성합니다. - Frame-level Concepts : 단일 프레임에서 등록되는 정적인 엔티티(예: 특정 인물 또는 객체)를 지칭하며, 이산적인(discrete) 프레임에 걸쳐 지속적인 인식을 요구합니다.
- Video-level Concepts : 연속적인 비디오 클립에 걸쳐 전개되는 동적인 행동(예: 개인화된 제스처 또는 액션 시퀀스)을 지칭하며, 연속적인 프레임에 걸친 추론을 요구합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
인간의 새로운 개념 인지 과정은 본질적으로 스트리밍(streaming) 프로세스입니다. 우리는 끊임없이 새로운 객체나 신원을 인식하고 시간이 지남에 따라 기억을 업데이트합니다. 그러나 현재의 멀티모달(multimodal) 개인화 방법론들은 주로 정적인 이미지나 오프라인(offline) 비디오에 국한되어 있습니다. 이러한 한계는 연속적인 시각 입력(continuous visual input)과 즉각적인 실세계 피드백(instant real-world feedback) 간의 단절을 야기하며, 미래 AI 비서에게 필수적인 실시간(real-time), 상호작용적(interactive), 개인화된 응답을 제공하는 능력을 제한합니다. 기존 연구(Baseline)들은 짧은 오프라인 비디오에만 적용되거나 다중 턴 상호작용을 지원하지 못하며, 특히 Video-level Personalization 과 같은 연속적인 행동 개념 인식에 대한 기능이 부재합니다. 저자들은 이러한 격차를 해소하고 실세계 시나리오에 더 부합하는 AI 비서의 발전을 위해, Personalized Streaming Video Understanding (PSVU) 이라는 새로운 태스크를 공식적으로 정의하고, 이를 평가할 수 있는 최초의 포괄적인 벤치마크인 PEARL-Bench 를 제안합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 PSVU 태스크의 도전 과제를 해결하기 위해 PEARL 이라는 플러그 앤 플레이(plug-and-play), 학습 불필요(training-free) 프레임워크를 제안합니다. PEARL 은 사용자 지시를 통해 스트리밍 비디오의 특정 타임스탬프에서 개념을 동적으로 정의하고, 후속 쿼리에 실시간 응답을 제공합니다. 이 프레임워크는 두 가지 핵심 구성 요소로 이루어져 있습니다. 첫째, Dual-grained Memory System 은 개념 중심 지식(concept-centric knowledge)과 스트림 중심 관찰(stream-centric observations)을 명시적으로 분리합니다. Streaming Memory는 연속적인 비디오 스트림을 장면 경계(scene boundaries)에 따라 클립으로 분할하고, 각 클립에 대한 멀티모달 임베딩(multimodal embeddings) 을 계산하여 효율적인 검색을 위해 저장합니다. Concept Memory는 사용자 정의 개념에 대한 개념명, 시각적 증거(visual evidence), 그리고 텍스트 설명을 구조화된 형태로 저장합니다. 둘째, Concept-aware Retrieval Algorithm 은 사용자 쿼리 발생 시 Concept Memory에서 관련 개념을 식별하고, 개념 설명을 사용하여 쿼리를 재작성(query rewrite) 하여 Qwen3-VL-Embedding-2B 와 같은 멀티모달 임베딩 모델 로 인코딩합니다. 이 임베딩을 통해 Streaming Memory에서 가장 관련성 높은 상위 K 개의 과거 클립을 검색하고, 이들을 인접 N 개 클립으로 확장하여 시각적 맥락(visual context) 을 구성합니다. 최종적으로, 검색된 개념 정보, 과거 클립, 현재 클립 및 원본 쿼리를 VLM (Vision-Language Model) 에 입력하여 실시간 개인화된 응답을 생성합니다.
실험 결과, PEARL 은 8개의 오프라인 및 온라인 모델 대비 최첨단 성능을 달성합니다. 특히, Qwen3-VL-8B+PEARL 은 Frame-level 평균 정확도에서 23.47% (28.77% → 52.24%), Video-level Real-Time 정확도에서 22.88% (25.51% → 48.39%)의 상당한 성능 향상을 보이며, 자체 기반 모델을 크게 능가했습니다. 강력한 독점 모델인 Gemini3-pro-preview 보다도 Frame-level 평균 정확도에서 4% 이상, Video-level Real-Time 정확도에서 거의 24% 높은 성능을 보여, 오프라인 모델의 근본적인 한계를 드러냈습니다. PEARL 의 핵심 모듈(검색 및 재작성)은 매우 낮은 지연 시간(latency)을 도입하며, LLM (Large Language Model) 추론이 주요 지연 병목 현상임을 입증했습니다. 또한, Concept Memory 가 실시간 및 과거 시간 QA 정확도에 35% 이상의 극적인 향상을 가져오고, Streaming Memory 가 과거 시간 QA 정확도를 20% 이상 높이며, Query Rewriting 이 평균 정확도를 추가로 4.28% 개선하는 등, PEARL 설계의 각 구성 요소가 필수적임이 입증되었습니다. [Table 3], [Table 4], [Table 5]
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Personalized Streaming Video Understanding (PSVU) 이라는 새로운 태스크를 도입하고, 이를 평가하기 위한 최초의 포괄적인 벤치마크인 PEARL-Bench 를 제안했습니다. 또한, 스트리밍 비디오에서 개인화된 이해를 위한 플러그 앤 플레이 방식의 학습 불필요 프레임워크인 PEARL 을 개발했습니다. PEARL 은 Dual-grained Memory System 과 Concept-aware Retrieval Algorithm 을 특징으로 하며, 다양한 아키텍처에서 일관되게 최첨단 성능을 달성하면서도 제어 가능한 지연 시간(latency)을 유지합니다. 이 연구는 기존 VLM 개인화 방법론의 한계를 극복하고, 실세계 환경에서 실시간으로 상호작용하는 개인화된 AI 비서 개발의 새로운 길을 열었다는 점에서 학계 및 산업계에 중요한 시사점을 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Rank-Then-Act: Reward-Free Control from Frame-Order Progress
- [논문리뷰] Transition-Aware best-of-N sampling for Longitudinal Chest X-ray Reports
- [논문리뷰] DataComp-VLM: Improved Open Datasets for Vision-Language Models
- [논문리뷰] InstanceControl: Controllable Complex Image Generation without Instance Labeling
- [논문리뷰] Discrete Diffusion Language Models for Interactive Radiology Report Drafting
Review 의 다른글
- 이전글 [논문리뷰] MultiBind: A Benchmark for Attribute Misbinding in Multi-Subject Generation
- 현재글 : [논문리뷰] PEARL: Personalized Streaming Video Understanding Model
- 다음글 [논문리뷰] RealMaster: Lifting Rendered Scenes into Photorealistic Video
댓글