[논문리뷰] MinerU-Diffusion: Rethinking Document OCR as Inverse Rendering via Diffusion Decoding
링크: 논문 PDF로 바로 열기
Do not generate anything else. 저자: Wentao Zhang, Weijun Zeng, Bin Wang, Junbo Niu, Hejun Dong, Conghui He et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- OCR (Optical Character Recognition) : 문서 이미지에서 텍스트를 인식하고 구조화된 정보로 변환하는 기술로, 본 논문에서는 단순한 줄 단위 전사를 넘어 레이아웃, 테이블, 수식 등을 포함하는 복합적인 문서 파싱을 지칭합니다.
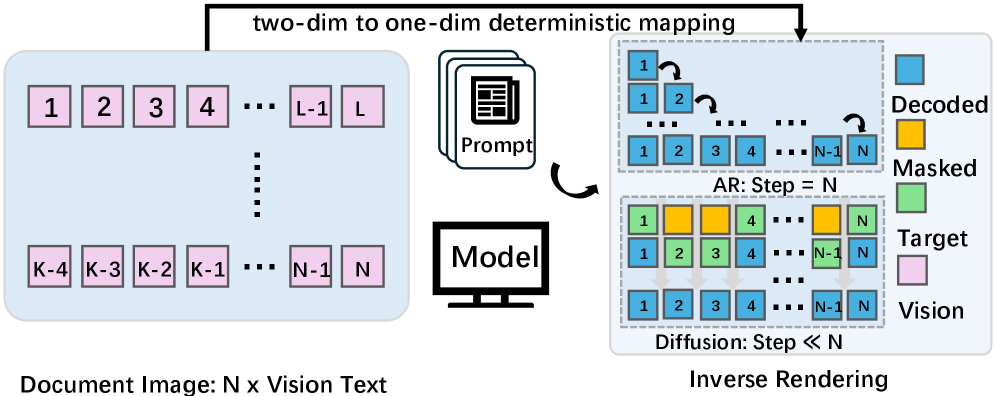
- Inverse Rendering : 기존의 순차적인 텍스트 생성 방식이 아닌, 시각적 증거로부터 구조화된 토큰 시퀀스를 재구성하는 방식으로 문서 OCR을 재개념화하는 관점입니다.
- Autoregressive (AR) Decoding : 대부분의 기존 Vision-Language Models (VLMs)에서 사용되는 방식으로, 토큰을 왼쪽에서 오른쪽으로 순차적으로 생성하는 디코딩 방법론입니다. 이는 긴 시퀀스에서 지연 시간과 오류 전파를 야기합니다.
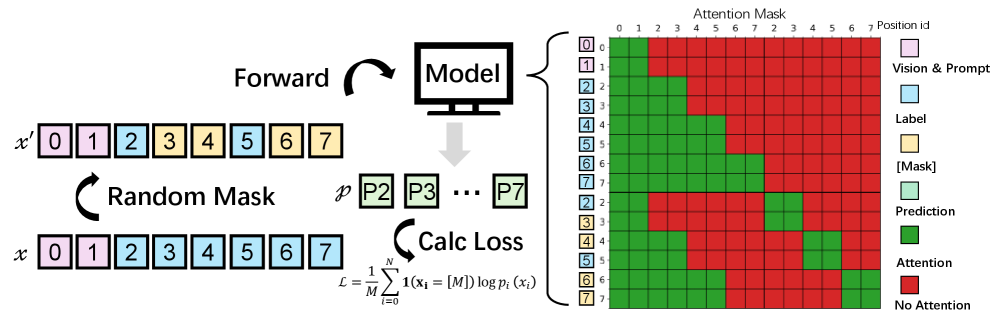
- Diffusion Decoding (Masked Diffusion Models) : 이산 Diffusion Process에 기반한 비-자기회귀적(non-autoregressive) 생성 프레임워크로, 부분적으로 마스킹된 시퀀스를 시각적 조건 하에 병렬적으로 점진적으로 denoising하여 텍스트를 재구성합니다.
- Block-Attention : MinerU-Diffusion에서 도입된 하이브리드 어텐션 메커니즘으로, 출력 시퀀스를 블록으로 나누어 블록 내부에서는 양방향 어텐션을, 선행 블록에 대해서는 인과적(causal) 어텐션을 적용하여 효율성과 구조적 안정성을 동시에 확보합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 Vision-Language Models (VLMs)의 발전에도 불구하고, 대부분의 기존 문서 OCR 시스템들은 autoregressive (AR) decoding 방식에 의존하고 있습니다. 이 방식은 long documents 및 복잡한 레이아웃 (예: 테이블, 수식)을 파싱할 때 sequential latency 를 유발하고 오류 전파(error propagation) 를 증폭시키는 문제가 있습니다. 또한, AR 모델은 텍스트 생성 시 강한 linguistic priors 에 암묵적으로 의존하여, 시각적 신호가 약하거나 의미론적(semantic) 맥락이 교란될 때 semantic hallucinations 및 cumulative errors 를 발생시키기 쉽습니다. 본 연구는 OCR이 본질적으로 시각적 증거에 기반한 결정론적인(deterministic) 작업이라는 점에 주목하며, 기존의 인과적(causal) 생성 순서가 작업의 본질적인 속성이라기보다는 단순한 직렬화(serialization)의 결과물이라고 주장합니다 [cite: 1, Figure 2]. 따라서 저자들은 이러한 기존 AR 방식의 한계를 극복하고, OCR task의 구조적 특성에 더 잘 맞는 새로운 디코딩 패러다임의 필요성을 제기합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 문서 OCR을 inverse rendering 문제 로 재정의하고, autoregressive causal decoding 대신 시각적 조건(visual conditioning) 하의 diffusion-based decoding 방식을 제안합니다. 핵심 제안은 MinerU-Diffusion 으로, 이는 block-wise diffusion decoder 와 uncertainty-driven curriculum learning 전략을 결합한 통합 diffusion 기반 프레임워크입니다.
MinerU-Diffusion 아키텍처는 출력 시퀀스를 B 개의 연속적인 블록으로 분할합니다. 이 Block-Attention 메커니즘은 블록 내에서는 병렬적인 Diffusion refinement를 수행하고, 블록 간에는 거친 수준의 autoregressive 구조 를 도입합니다 [cite: 1, Figure 3]. 이는 기존 Full-Attention 방식의 이차 복잡도 O(L^2)를 O(BL'^2)로 줄여 계산 효율성을 높이고, 블록 경계를 구조적 앵커로 활용하여 장거리 정렬 드리프트(long-range alignment drift)를 방지하며 안정성을 확보합니다.
또한, MinerU-Diffusion은 Two-Stage Curriculum Learning 을 통해 대규모 이질적 데이터와 노이즈가 많은 레이블로부터 안정적인 학습을 가능하게 합니다.
- Stage I: Diversity-Driven Foundational Learning 에서는 대규모의 다양하고 균형 잡힌 데이터셋 ( D_base )을 활용하여 견고한 기초 표현과 일반적인 파싱 능력을 학습합니다.
- Stage II: Uncertainty-Driven Boundary Refinement 에서는 Inference Consistency 지표(PageIoU, CDM, TEDS)를 통해 예측 불확실성이 높은 hard samples ( D_hard )를 선별하고, AI 보조 인간 주석(human annotation)을 통해 정제된 데이터셋으로 fine-tuning하여 모델의 견고성과 경계 정밀도를 향상시킵니다. 이 단계에서는 샘플 가중치 ( w(x) = 1 + β(1 - C(x)) )를 사용하여 hard samples에 더 집중하도록 유도합니다.
실험 결과, MinerU-Diffusion은 autoregressive (AR) baselines 대비 최대 3.2배 빠른 디코딩 속도 를 달성합니다 [cite: 1, Figure 1]. OmniDocBench v1.5 평가에서, GT Layout 없이 완전히 자동화된 설정에서 88.94의 Overall score 를 기록하여 대부분의 AR 기반 모델을 능가합니다 [cite: 1, Table 1]. GT Layout 이 주어질 경우 93.37 Overall score 를 달성하며 최고 수준의 AR 시스템과 유사한 경쟁력을 보여줍니다 [cite: 1, Table 1]. 또한, Semantic Shuffle benchmark 에서 AR decoders 가 distortion level 증가에 따라 성능이 급격히 저하되는 반면, MinerU-Diffusion은 거의 일정한 성능을 유지하며 강력한 robustness 를 입증했습니다 [cite: 1, Figure 7]. Table recognition (CC-OCR, OCRBench v2) 및 Formula recognition (UniMER-Test)과 같은 요소별 파싱 태스크에서도 경쟁력 있는 성능을 보였습니다. 특히 OCRBench v2 에서 TEDS 81.18 , TEDS-S 88.66 을, UniMER-Test 에서 CPE 91.6, HWE 91.6, SCE 92.0, SPE 96.8 의 높은 점수를 기록했습니다 [cite: 1, Table 3].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 문서 OCR을 위한 2.5B-parameter diffusion-based framework 인 MinerU-Diffusion 을 제안합니다. 이 모델은 기존의 autoregressive decoding 을 block-level parallel diffusion decoding 과 confidence-guided scheduling 으로 대체하여 효율성과 확장성을 크게 향상시켰습니다. 또한, Two-Stage Curriculum Learning 전략은 학습의 안정성을 높이고 경계 정밀도 및 견고성을 강화합니다. 문서, 테이블, 수식 및 Semantic Shuffle benchmark 전반에 걸친 광범위한 실험은 MinerU-Diffusion이 AR baseline과 비교하여 경쟁력 있는 성능을 보였을 뿐만 아니라, 의미론이 교란된 입력에 대한 강력한 회복력(resilience) 을 입증했습니다. 이러한 결과는 diffusion-based parallel decoding 이 문서 OCR 분야에서 효율적이고 신뢰할 수 있는 유망한 대안임을 시사하며, 향후 문서 OCR을 위한 Diffusion 기반 디코딩 연구에 영감을 줄 것으로 기대됩니다.

⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Scaling Instruction-Based Video Editing with a High-Quality Synthetic Dataset
- [논문리뷰] StressDream: Steering Video World Models for Robust Policy Evaluation and Improvement
- [논문리뷰] LLaTiSA: Towards Difficulty-Stratified Time Series Reasoning from Visual Perception to Semantics
- [논문리뷰] Kiwi-Edit: Versatile Video Editing via Instruction and Reference Guidance
- [논문리뷰] Beyond Language Modeling: An Exploration of Multimodal Pretraining
Review 의 다른글
- 이전글 [논문리뷰] From Static Templates to Dynamic Runtime Graphs: A Survey of Workflow Optimization for LLM Agents
- 현재글 : [논문리뷰] MinerU-Diffusion: Rethinking Document OCR as Inverse Rendering via Diffusion Decoding
- 다음글 [논문리뷰] MultiBind: A Benchmark for Attribute Misbinding in Multi-Subject Generation
댓글