[논문리뷰] Visual Aesthetic Benchmark: Can Frontier Models Judge Beauty?
링크: 논문 PDF로 바로 열기
저자: Yichen Feng, Yuetai Li, Chunjiang Liu, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- VAB (Visual Aesthetic Benchmark): 이미지의 미적 품질을 단일 점수가 아닌 비교 순위(Comparative Ranking)로 평가하도록 설계된 새로운 벤치마크입니다.
- TB-1 (Top/Bottom-1): candidate set 내에서 가장 뛰어난 이미지(Best)와 가장 부족한 이미지(Worst)를 동시에 선택하게 하는 평가 설정입니다.
- ap@1 (Average precision at 1): 여러 번의 무작위 순서 permutation 평가를 거쳐 정답률을 계산하는 모델의 성능 지표입니다.
- Pass^3: 무작위 순서로 시행된 3번의 평가에서 모두 정답을 맞춘 경우에만 성공으로 간주하는 엄격한 평가 척도입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 기존의 이미지 미학 평가 방식인 Scalar Score 예측이 인간의 실제 비교 선호도를 충실히 반영하지 못한다는 문제를 제기합니다. 기존 연구들은 독립적인 점수 매기기를 통해 순위를 도출하는데, 이는 annotator 간의 의견 불일치와 모호한 미적 기준을 야기합니다. 저자들은 [Figure 1]에 나타난 바와 같이, 이미지 미학 평가를 단순 점수화가 아닌 '동일한 주제의 후보군 중 최고/최저 선택'이라는 비교 작업으로 재정의할 필요성을 강조합니다.
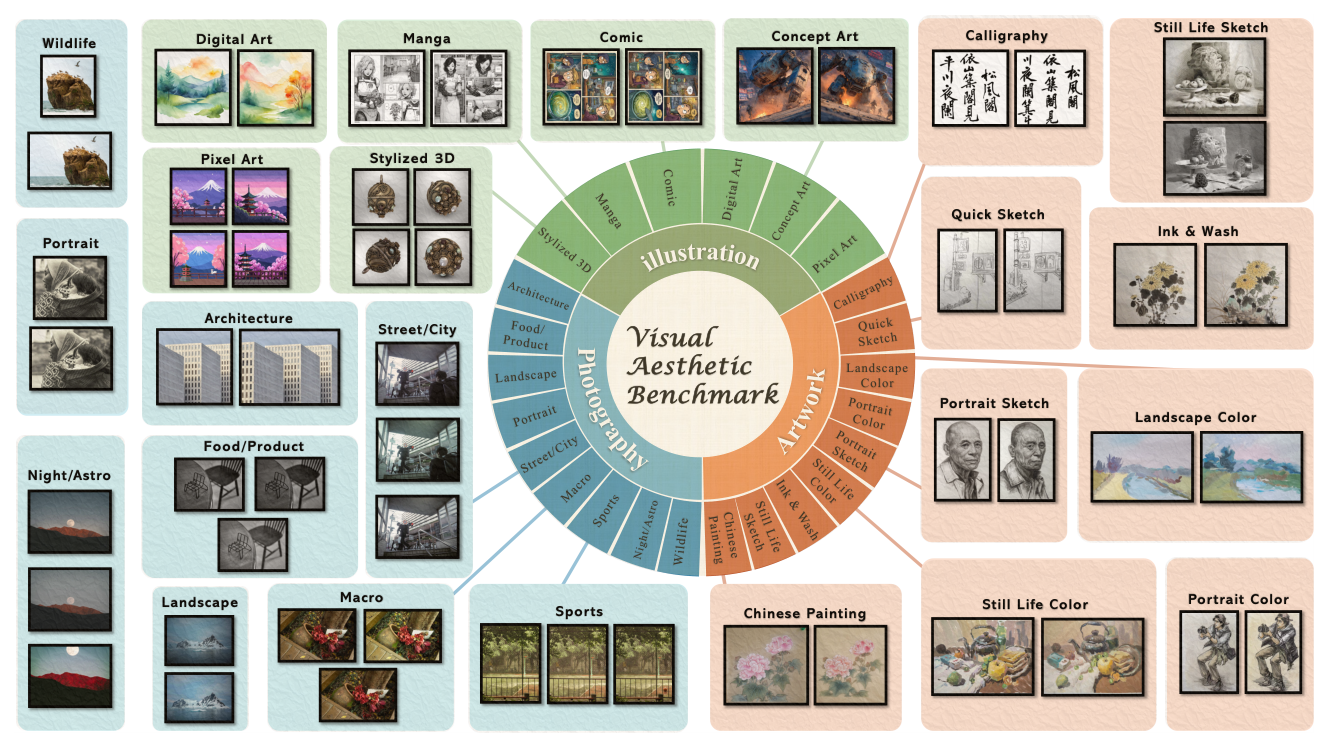
Figure 1 — VAB 벤치마크의 구성과 도메인 및 주제 분포를 한눈에 보여주는 핵심 다이어그램
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 10명의 독립적인 전문가 합의를 통해 400개의 과제와 1,195개의 이미지로 구성된 VAB를 구축하였으며, 20개의 MLLM과 6개의 전용 Visual-Quality Reward Models를 벤치마킹했습니다. 실험 결과, 인간 전문가의 TB-1 Pass^3 기준 정답률은 68.9%인 반면, 가장 우수한 모델인 Claude Sonnet 4.6은 26.5%의 정답률을 기록하여 큰 성능 격차를 보였습니다. [Table 4]와 [Table 5]에 따르면, 후보 이미지의 개수가 늘어날수록 모델의 성능은 전문가 대비 급격하게 저하되며, 이는 모델이 후보 순서(Candidate Order) 변화에 매우 민감하게 반응하고 있음을 시사합니다. 또한, LoRA 기반의 파인튜닝 기법을 적용하여 Qwen3.5-35B-A3B를 학습시킨 결과, 397B 파라미터 모델인 Qwen3.5-397B-A17B와 유사한 성능 수준에 도달하여, 비교 학습 신호의 전이 가능성을 입증하였습니다.
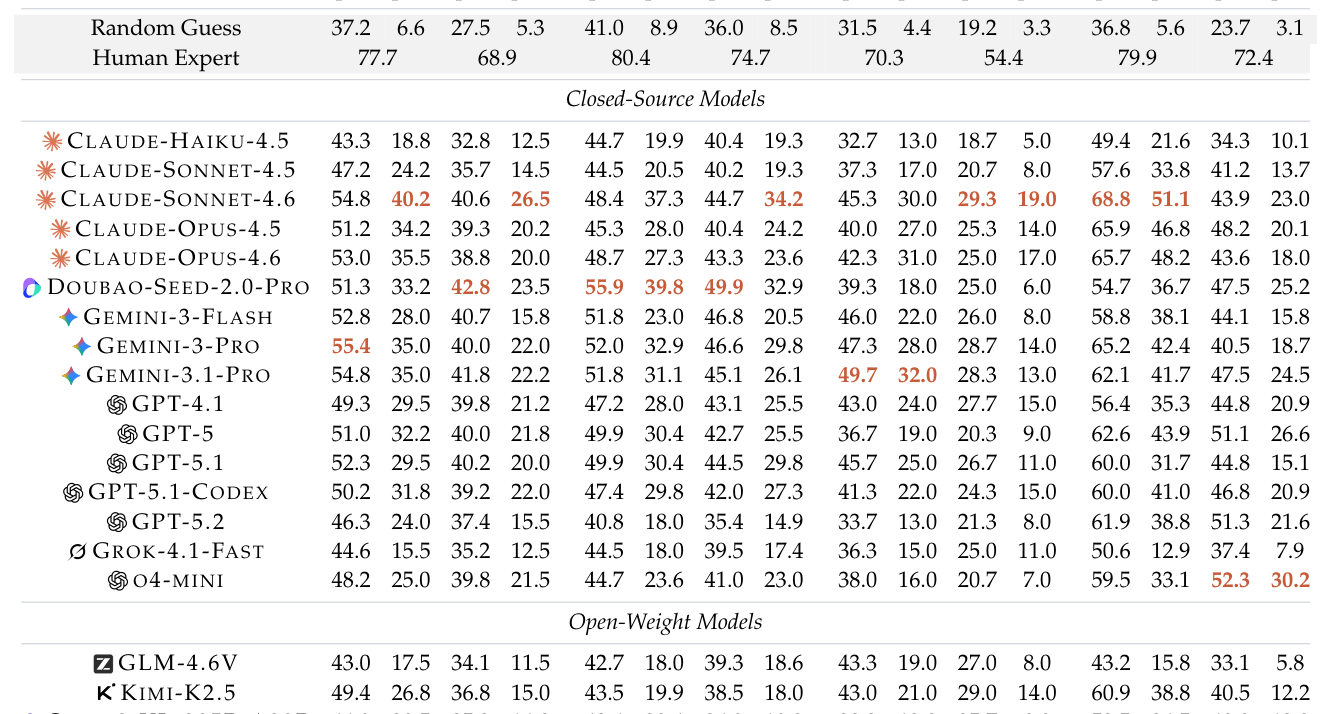
Table 4 — 주요 MLLM 모델들의 성능을 비교한 핵심 결과 테이블
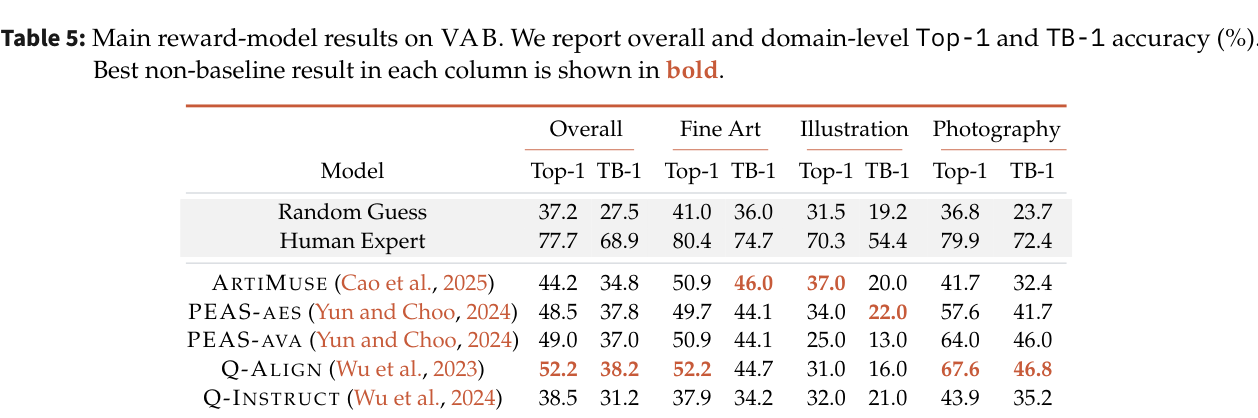
Table 5 — Reward model의 성능을 종합적으로 보여주는 결과 테이블
4. Conclusion & Impact (결론 및 시사점)
본 논문은 현대의 MLLM이 전문가 수준의 미학적 판단을 내리는 데 있어 여전히 명확한 한계가 있음을 입증하고, 이를 추적할 수 있는 최초의 set-based 벤치마크를 제공합니다. 이 연구는 미학적 평가가 단순 점수화가 아닌 비교 판단의 영역임을 명시함으로써 향후 데이터셋 설계 및 모델 학습 프레임워크에 중요한 방향성을 제시합니다. 특히 전문가 기반의 비교 평가 데이터가 모델의 지적 능력을 제고하는 데 효율적인 신호가 됨을 보임으로써, 더욱 정교한 시각적 이해력을 갖춘 모델 개발의 기반을 마련했습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] MuseBench: Benchmarking Intent-Level Audiovisual Arts Understanding in MLLMs
- [논문리뷰] Breaking Failure Cascades: Step-Aware Reinforcement Learning for Medical Multimodal Reasoning
- [논문리뷰] PixelEyes: Decoupling Perception and Reasoning for Pinpoint Visual Evidence Seeking
Review 의 다른글
- 이전글 [논문리뷰] TrackCraft3R: Repurposing Video Diffusion Transformers for Dense 3D Tracking
- 현재글 : [논문리뷰] Visual Aesthetic Benchmark: Can Frontier Models Judge Beauty?
- 다음글 [논문리뷰] Vividh-ASR: A Complexity-Tiered Benchmark and Optimization Dynamics for Robust Indic Speech Recognition
댓글