[논문리뷰] TrackCraft3R: Repurposing Video Diffusion Transformers for Dense 3D Tracking
링크: 논문 PDF로 바로 열기
저자: Jisu Nam, Jahyeok Koo, Soowon Son, Jaewoo Jung, Honggyu An, Junhwa Hur, Seungryong Kim
1. Key Terms & Definitions (핵심 용어 및 정의)
- Video DiTs (Video Diffusion Transformers): 사전 학습된 대규모 비디오 생성 모델로서, 강력한 시공간적 사전 정보(spatio-temporal priors)를 내재하고 있어 영상 인식 작업에 효과적으로 활용 가능합니다.
- Dual-Latent Representation: 각 프레임의 기하학적 정보를 담은 geometry latents와 첫 번째 프레임을 기준으로 픽셀 단위 궤적을 쿼리하는 track latents를 결합한 입력 표현 방식입니다.
- Temporal RoPE Alignment: 3D RoPE(Rotary Positional Embedding)를 활용하여 track latent가 geometry latent 내의 정확한 타겟 타임스탬프를 참조하도록 정렬하는 설계입니다.
- Reference-Anchored Tracking: 영상의 첫 번째 프레임을 기준으로 동일한 물리적 지점(points)을 시간의 흐름에 따라 추적하는 방식입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 영상 기반 3D 추적 방식이 가진 한계를 극복하고, 사전 학습된 비디오 생성 모델의 풍부한 시공간적 지식을 활용하여 효율적인 dense 3D tracking 프레임워크를 구축하는 것을 목표로 합니다. 기존 3D 추적기들은 주로 합성 데이터셋에 의존하거나, 고정된 다중 뷰 이미지에서 학습된 모델을 정교하게 미세 조정하는 방식을 사용해 실제 영상에서의 동적 모션 사전 학습이 부족한 상태였습니다. 또한, 대부분의 비디오 기반 인식 모델이 프레임 단위로 독립적으로 출력하는 frame-anchored 방식을 취하고 있어, 시간적 연속성을 보장하는 dense 3D 추적과는 구조적 불일치가 존재합니다. [Figure 2]
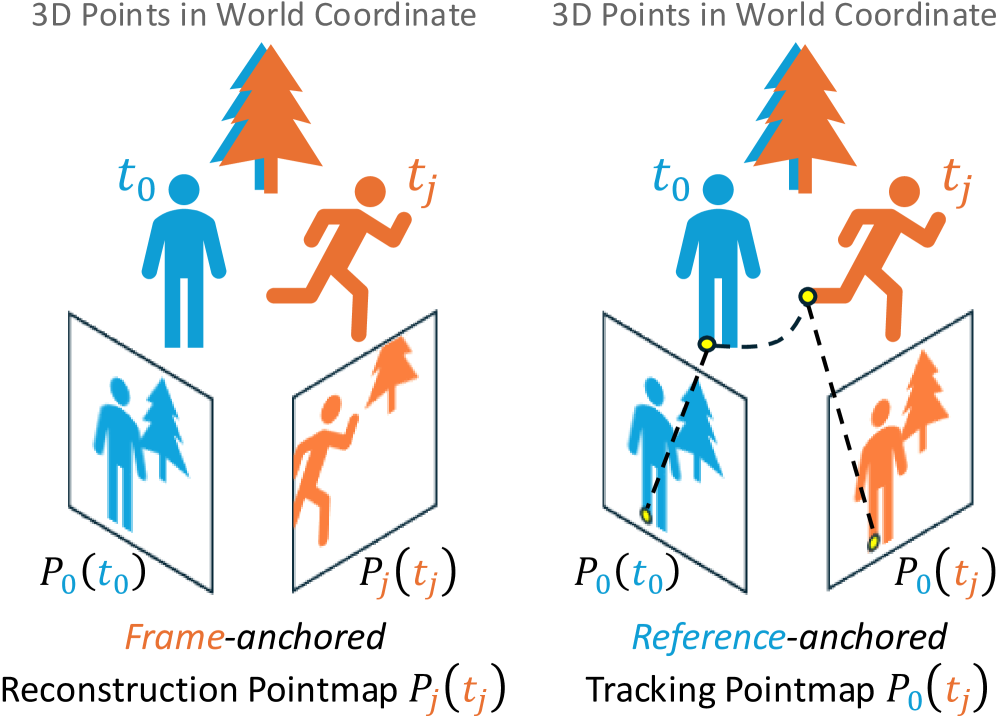
Figure 2 — 포인트맵 표현 방식 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 비디오 DiT를 feed-forward dense 3D 추적기로 변환하는 TrackCraft3R을 제안하며, 이는 단일 forward pass를 통해 픽셀별 추적 결과와 가시성(visibility)을 예측합니다 [Figure 1]. 저자들은 두 가지 핵심 설계를 통해 이를 구현합니다: (i) RGB 정보와 3D geometry 정보를 통합한 geometry latents와 첫 프레임 기반의 track latents를 결합한 dual-latent 구조를 도입하고, (ii) temporal RoPE를 통해 track latent가 특정 타임스탬프의 geometry latent를 정확하게 참조하도록 설계했습니다. [Figure 3]. 실험 결과, TrackCraft3R은 기존 SOTA 방식인 DELTAv2 대비 1.3배 빠른 추론 속도를 보였으며, peak memory 사용량은 4.6배 감소시켰습니다 [Table 6]. 특히, 주요 3D 추적 벤치마크(TAPVid-3D 등)에서 우수한 AJ(Average Jaccard), APD3D(Average Percentage of points within threshold), OA(Occlusion Accuracy) 성능을 달성하며 정량적 우위를 입증했습니다 [Table 1].
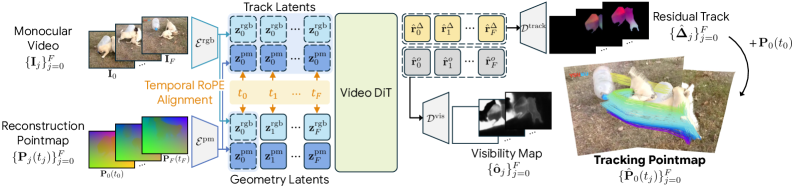
Figure 1 — 전체 모델 아키텍처

Figure 3 — 쿼리-키 어텐션 시각화
4. Conclusion & Impact (결론 및 시사점)
본 연구는 생성 모델로 알려진 비디오 DiT의 프레임 생성 패러다임을 효율적인 dense 3D 추적 패러다임으로 성공적으로 전환하는 독창적인 프레임워크를 제시합니다. TrackCraft3R은 복잡한 반복 추적(iterative tracking) 과정 없이 단일 pass로 정확한 3D 궤적을 추출함으로써 학계와 산업계의 동적 장면 이해 분야에 새로운 효율성 기준을 마련했습니다. 이 연구는 대규모 사전 학습된 모델이 3D 컴퓨터 비전 과제에 어떻게 통합될 수 있는지에 대한 중요한 실증적 사례를 제공하며, 향후 로봇 조작이나 영상 분석 분야의 기초 기술로 확장될 잠재력이 큽니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] RynnWorld-Teleop: An Action-Conditioned World Model for Digital Teleoperation
- [논문리뷰] YingVideo-MV: Music-Driven Multi-Stage Video Generation
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
Review 의 다른글
- 이전글 [논문리뷰] The Extrapolation Cliff in On-Policy Distillation of Near-Deterministic Structured Outputs
- 현재글 : [논문리뷰] TrackCraft3R: Repurposing Video Diffusion Transformers for Dense 3D Tracking
- 다음글 [논문리뷰] Visual Aesthetic Benchmark: Can Frontier Models Judge Beauty?
댓글