[논문리뷰] The Extrapolation Cliff in On-Policy Distillation of Near-Deterministic Structured Outputs
링크: 논문 PDF로 바로 열기
저자: Xin Li, Hao Jiang, Annan Wang, Yichi Zhang, Chau Yuen
1. Key Terms & Definitions (핵심 용어 및 정의)
- OPD (On-policy Distillation): 학생 모델을 교사 모델의 per-token log-probabilities에 대해 학습시키는 기법으로, 학생이 생성한 rollout을 활용함.
- Reward Extrapolation ($\lambda$): 교사 모델의 확률 분포를 $\lambda > 1$ 계수로 sharpen하여, 학습 성능을 높이는 방식.
- IS (Importance Sampling) Clipping: 학습 안정성을 위해 업데이트 시 교사 모델과 학생 모델 간의 확률비(ratio)를 특정 값 $c$로 제한하는 기법.
- Extrapolation Cliff ($\lambda^{\star}$): reward extrapolation 계수 $\lambda$가 특정 임계값을 넘어서면, 모델이 구조적 출력 계약(structured-output contract)을 더 이상 준수하지 못하고 파괴되는 현상.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM의 On-policy Distillation 과정에서 발생하는 reward extrapolation의 한계점을 해결하고자 한다. 일반적으로 $\lambda > 1$을 사용하면 모델의 도메인 내 성능을 향상시킬 수 있으나, 임계값 $\lambda^{\star}$을 초과하면 구조화된 출력(JSON 등)의 형식이 붕괴되는 문제가 발생한다. 기존 연구들은 이러한 실패를 경험적으로 관찰하거나 사후적인 튜닝에 의존했으나, 본 연구는 이 cliff 현상이 발생하는 임계값을 Closed-form으로 유도하여 예측 가능한 훈련 환경을 구축하고자 한다. 이를 통해 포맷 준수 여부를 학습 중에 제어하지 못하는 기존 방법론의 불확실성을 해소한다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Bernoulli reduction을 통해 임계값 $\lambda^{\star}(p, b, c)$를 유도하고, 이를 ListOPD 기법으로 구조적 리스트 생성 작업에 적용한다. 제안된 방법은 교사 모델의 modal 확률 $p$, warm-start 모델의 확률 $b$, 그리고 IS clipping 강도 $c$를 변수로 사용하여 안전한 작동 범위를 정량화한다 [Figure 1]. 실험 결과, Amazon Fashion 데이터셋에서 1.7B 크기의 학생 모델이 ListOPD를 통해 8B SFT baseline과 동등한 수준의 성능(in-domain parity)을 달성하였다. 특히 NDCG@1과 같은 랭킹 품질은 유지하면서, parse_rate가 극적으로 개선되어 94.8%의 성공률을 기록했다 [Figure 2]. 임계값을 기준으로 한 훈련 전 예측값과 실제 발생한 cliff 구간은 실험적으로 일치하며, $\lambda^{\star}$ 미만에서 학습할 경우 모델의 파라미터 효율성과 형식 준수력이 최적화됨을 증명한다 [Table 2].
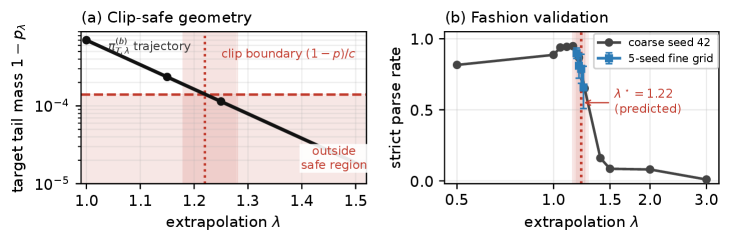
Figure 1 — Extrapolation Cliff와 안전 영역 경계
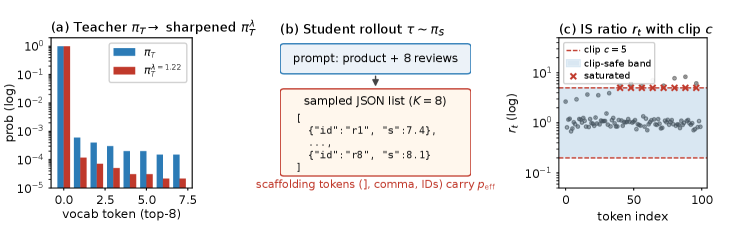
Figure 2 — ListOPD 학습 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 연구는 reward extrapolation이 모델 성능 향상과 포맷 붕괴라는 양면성을 지님을 규명하고, 이를 방지하기 위한 정량적인 예측 공식을 제시하였다. 이 공식은 LLM post-training에서 고비용의 사후 튜닝(trial-and-error)을 줄이고, 보다 안정적인 모델 배포를 가능하게 한다. 특히 구조적 출력을 요구하는 산업계 애플리케이션에서 constrained decoding에만 의존하지 않고 학습 자체를 최적화할 수 있는 이론적 기반을 제공함으로써, 효율적인 경량화 모델 생태계 발전에 기여한다.
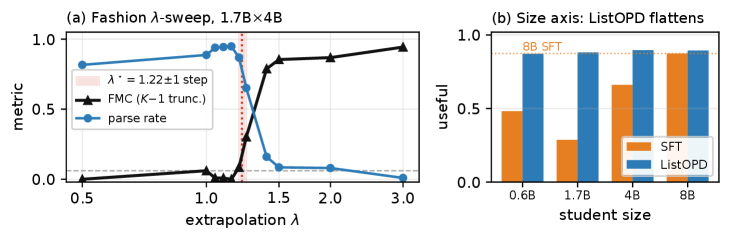
Figure 3 — lambda 스윕에 따른 parse 붕괴 현상
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] WideSearch: Benchmarking Agentic Broad Info-Seeking
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] AgenticDataBench: A Comprehensive Benchmark for Data Agents
- [논문리뷰] Seed2.0 Model Card: Towards Intelligence Frontier for Real-World Complexity
- [논문리뷰] Unlocking the Visual Record of Materials Science: A Large-Scale Multimodal Dataset from Scientific Literature
Review 의 다른글
- 이전글 [논문리뷰] The DAWN of World-Action Interactive Models
- 현재글 : [논문리뷰] The Extrapolation Cliff in On-Policy Distillation of Near-Deterministic Structured Outputs
- 다음글 [논문리뷰] TrackCraft3R: Repurposing Video Diffusion Transformers for Dense 3D Tracking
댓글