[논문리뷰] MuRF: Unlocking the Multi-Scale Potential of Vision Foundation Models
링크: 논문 PDF로 바로 열기
저자: Bocheng Zou, Mu Cai, Mark Stanley, Dingfu Lu, and Yong Jae Lee
1. Key Terms & Definitions (핵심 용어 및 정의)
- Vision Foundation Models (VFMs) : 대규모 데이터셋으로 사전 학습되어 다양한 downstream task에 대해 robust한 feature representation을 제공하는 컴퓨터 비전 모델입니다.
- Multi-Resolution Fusion (MuRF) : inference 시점에 단일
VFM을 통해 여러 resolution의 이미지를 처리하고, 그 결과로 얻은 feature를 통합하여 scale-robust한 unified representation을 생성하는 training-free 전략입니다. - Dense Prediction : Semantic Segmentation 및 Depth Estimation과 같이 이미지의 각 픽셀에 대한 예측을 요구하는 task를 지칭합니다.
- Multimodal Understanding (MLLMs) : Visual Question Answering (VQA)과 같이 시각 및 언어 정보를 통합하여 복합적인 추론을 수행하는 Multimodal Large Language Models의 능력을 의미합니다.
- Unsupervised Anomaly Detection : 훈련 데이터에서 정상 샘플만 사용하여 모델을 학습시키고, inference 시점에 비정상 샘플을 식별하는 task입니다. 본 논문에서는 training-free 방식으로
MuRF를 적용합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 VFM은 다양한 task에서 강력한 representation을 제공하며 컴퓨터 비전 분야의 핵심으로 자리 잡았습니다. 이 모델들은 multi-resolution training을 통해 다양한 입력 aspect ratio와 scale을 유연하게 처리할 수 있게 되었지만, inference는 일반적으로 단일의 고정된 scale로 제한되는 경향이 있습니다. 이러한 단일 scale paradigm은 시각적 인지의 근본적인 특성을 간과합니다. 저해상도 view는 global semantic recognition에 강점을 가지는 반면, 고해상도 view는 fine-grained refinement에 필수적입니다. 기존 inference 방식은 global coherence 또는 local precision 중 하나를 희생할 수밖에 없는 한계점을 가지며, [Figure 1]에서 볼 수 있듯이 단일 scale에서는 이 두 가지 역할을 동시에 최적화하기 어렵습니다. 따라서 저자들은 inference 시점에 이러한 complementary view를 적극적으로 활용하여 VFM의 잠재력을 최대한 발휘할 수 있는 새로운 접근 방식의 필요성을 제기합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 VFM의 multi-scale 잠재력을 inference 시점에 활용하기 위해 Multi-Resolution Fusion (MuRF)을 제안합니다. MuRF는 frozen VFM backbone을 feature extractor로 사용하여 동일한 입력 이미지를 여러 resolution pyramid로 처리하고, 그 결과 feature map들을 통합하여 unified representation을 생성합니다. 구체적으로, 입력 이미지 x는 Sres 스케일링 팩터 세트에 따라 여러 resolution의 이미지 xs로 resize됩니다. 각 xs는 frozen VFM encoder Φ를 통과하여 patch-level feature map Fs를 생성합니다. 이 Fs들은 bilinear interpolation을 사용하여 공통 target spatial resolution (H', W')으로 upsample된 후, channel dimension을 따라 concatenate되어 최종 MuRF representation FMURF를 형성합니다. `
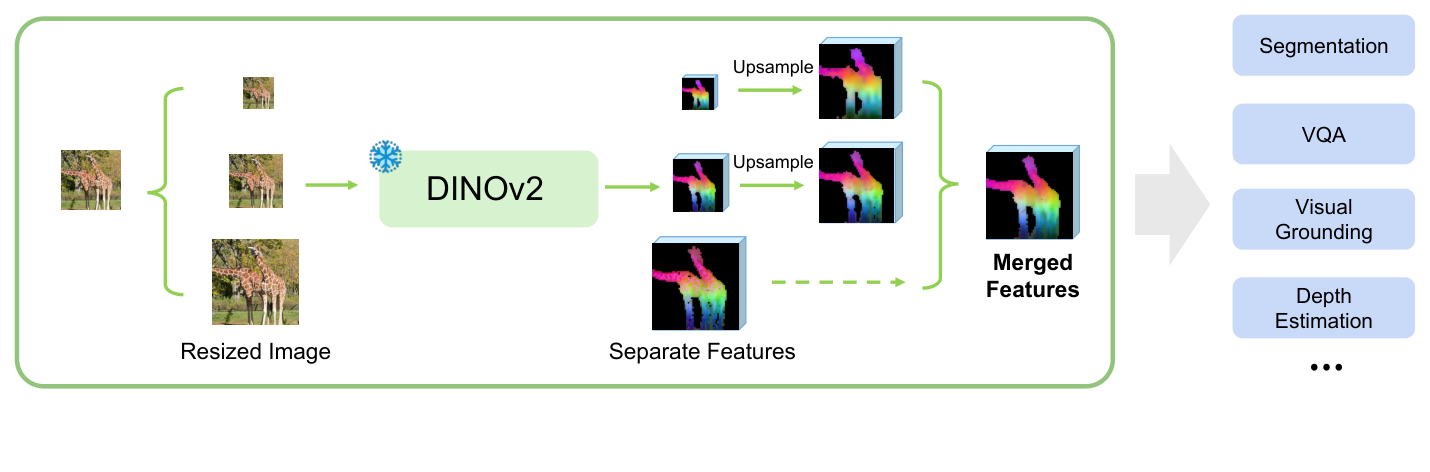
에서 볼 수 있듯이, 이러한 channel-wise concatenation은 recognition및refinement신호의strict independence를 유지하여 lightweight downstream head가 적절한 scale information`을 적응적으로 선택하도록 돕습니다.
MuRF의 보편성은 architecture나 task에 묶여있지 않은 training-free enhancement라는 점입니다. 다양한 downstream task에서 MuRF의 효과를 검증했습니다.
- Dense Prediction (Semantic Segmentation & Depth Estimation) :
MuRF는ADE20K에서 47.4% mIoU 를 달성하여 단일resolution DINOv2의 45.5% 를 상회하고,PASCAL VOC에서는 83.1% mIoU 로 78.5% 를 크게 넘어섰습니다.NYU Depth V2depth estimation에서는RMSE0.368 을 기록하여 단일resolution의 0.394 보다 훨씬 낮은error rate를 보였습니다 `
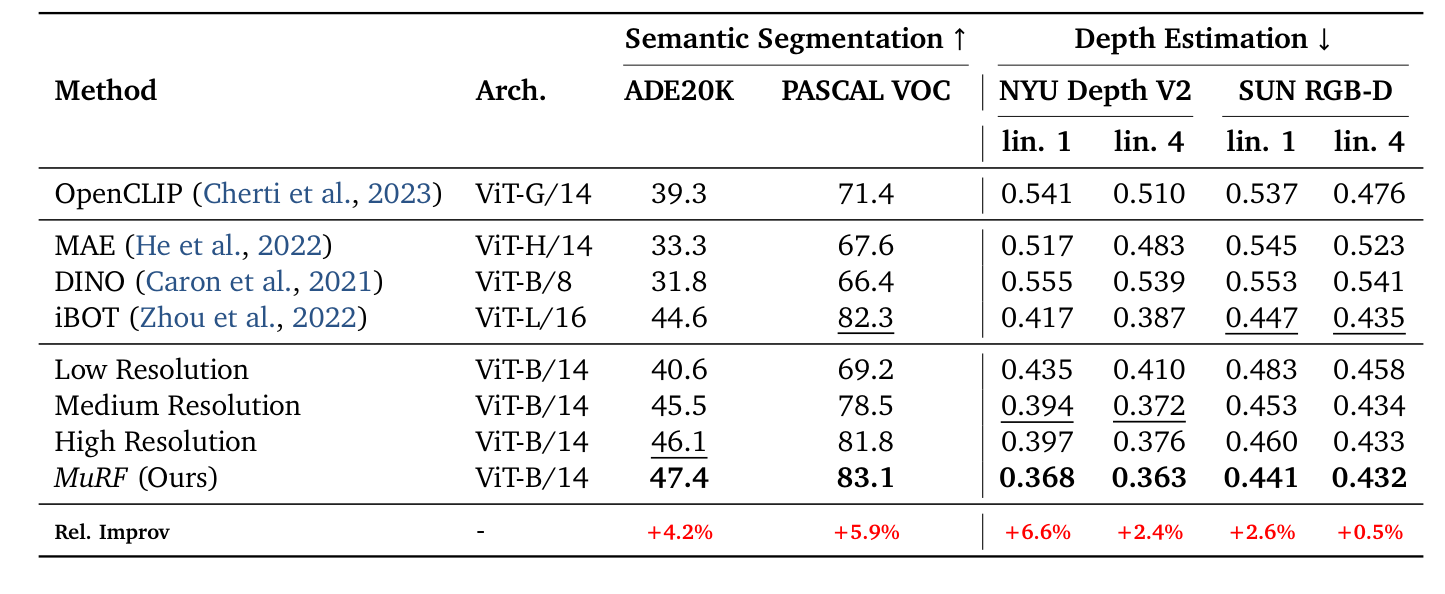
. SigLip2 backbone을 사용한 ADE20K semantic segmentation에서도 MuRF는 **37.10% mIoU** 로 단일 resolution 대비 **1.83% absolute mIoU 향상을 보였습니다 [Table 6].
- Multimodal Understanding (VQA):
LLaVA-MRF VQAtask에서MuRFrepresentation을 적용한MLLM은DinoV2및SigLip2vision encoder모두에서multimodal understanding capacity를 크게 향상시켰습니다[Table 3]. 이는MuRF가holistic scene understanding과fine-grained detail을 모두 포착하여 언어 모델의 추론 능력을 강화함을 시사합니다. - Unsupervised Anomaly Detection:
MVTec AD 2 TESTpriv,mix벤치마크에서MuRF는 62.3% AU-PRO0.05를 달성하여PatchCore(52.6%) 및SuperAD(59.3%)와 같은state-of-the-art method들을 능가했습니다
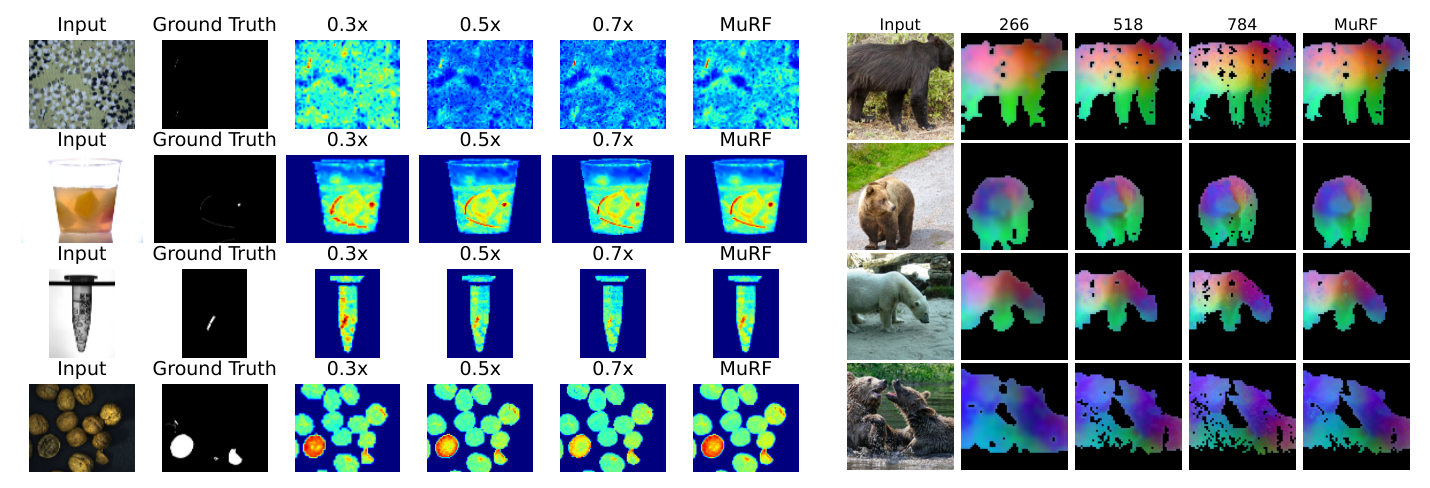
. 이는 MuRF의 multi-resolution design이 microscopic scratch부터 large structural defect까지 다양한 scale의 anomaly`를 효과적으로 처리할 수 있음을 증명합니다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 frozen VFM의 representation을 강화하기 위한 Multi-Resolution Fusion (MuRF)이라는 간단하면서도 강력한 inference-time strategy를 소개했습니다. MuRF는 입력 space에서 feature pyramid를 구성하고 결과 representation을 융합함으로써, 저해상도 view에서 얻는 global context와 고해상도 view에서 얻는 fine-grained detail을 효과적으로 통합합니다. 광범위한 실험을 통해 MuRF가 dense prediction, multimodal reasoning, unsupervised anomaly detection을 포함한 다양한 fundamental vision task에서 일관되고 중요한 성능 향상을 가져온다는 것을 입증했습니다. 이러한 결과는 multi-resolution aggregation이 특정 task에 국한된 trick이 아니라, 사전 학습된 visual encoder의 잠재력을 최대한 발휘하기 위한 general principle임을 확립합니다. MuRF는 기존 VFM 기반 시스템에 쉽게 적용되어 scale-robust visual representation을 제공함으로써, 학계와 산업계 모두에서 computer vision system의 성능 향상에 크게 기여할 수 있는 잠재력을 가집니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Vision as Unified Multimodal Generation
- [논문리뷰] UniDDT: Unifying Multimodal Understanding and Generation with Decoupled Diffusion Transformer
- [논문리뷰] Phase Marginalization for Patch-Grid Instability in Vision Transformers
- [논문리뷰] CogOmniControl: Reasoning-Driven Controllable Video Generation via Creative Intent Cognition
- [논문리뷰] CoME-VL: Scaling Complementary Multi-Encoder Vision-Language Learning
Review 의 다른글
- 이전글 [논문리뷰] MemMA: Coordinating the Memory Cycle through Multi-Agent Reasoning and In-Situ Self-Evolution
- 현재글 : [논문리뷰] MuRF: Unlocking the Multi-Scale Potential of Vision Foundation Models
- 다음글 [논문리뷰] PixelSmile: Toward Fine-Grained Facial Expression Editing
댓글