[논문리뷰] Stitched Value Model for Diffusion Alignment
링크: 논문 PDF로 바로 열기
저자: Hyojun Go, Hyungjin Chung, Prune Truong, Goutam Bhat, Li Mi, Zhaochong An, Zixiang Zhao, Dominik Narnhofer, Serge Belongie, Federico Tombari, Konrad Schindler
1. Key Terms & Definitions (핵심 용어 및 정의)
- StitchVM: 프리트레이닝된 pixel-space reward model과 diffusion backbone을 stitching layer로 결합하여 noisy latent 공간에서 value function을 직접 도출하는 프레임워크.
- Value Function ($V_t$): 특정 noisy latent $z_t$가 주어졌을 때, 최종 생성될 clean image가 가질 기대 보상(expected reward)을 예측하는 함수.
- Alignment: diffusion 또는 flow 기반 모델이 prompt fidelity, aesthetic preference 등 특정 보상 기준을 따르도록 가이드하는 과정.
- Tweedie Approximation: noisy latent $z_t$에서 직접 보상을 계산할 수 없기에, posterior mean을 통해 clean sample을 근사한 후 보상을 평가하는 방식.
- FK Steering (Feynman-Kac Steering): 여러 particle의 denoising 경로를 병렬로 탐색하고, value function을 이용한 잠재적 보상을 기반으로 particle을 resampling하는 추론 기법.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 diffusion model의 효과적인 alignment를 위해 noisy latent regime에서 정확하고 효율적인 Value Function을 구축하는 문제를 다룬다. 기존 연구들은 pixel-space reward model을 사용하기 위해 Tweedie approximation이나 고비용의 Monte Carlo (MC) rollout을 활용하는데, 전자는 high-noise regime에서 bias가 크고 후자는 계산 효율성이 매우 낮다는 한계가 있다. 따라서 프리트레이닝된 강력한 reward model의 이점을 유지하면서 noisy latent를 직접 처리할 수 있는 효율적인 방식이 절실하다. 저자들은 기존의 고비용 반복 계산을 피하고, 학습된 가치 모델을 통해 추론 및 학습 단계의 alignment 성능을 극대화하고자 한다. [Figure 1]
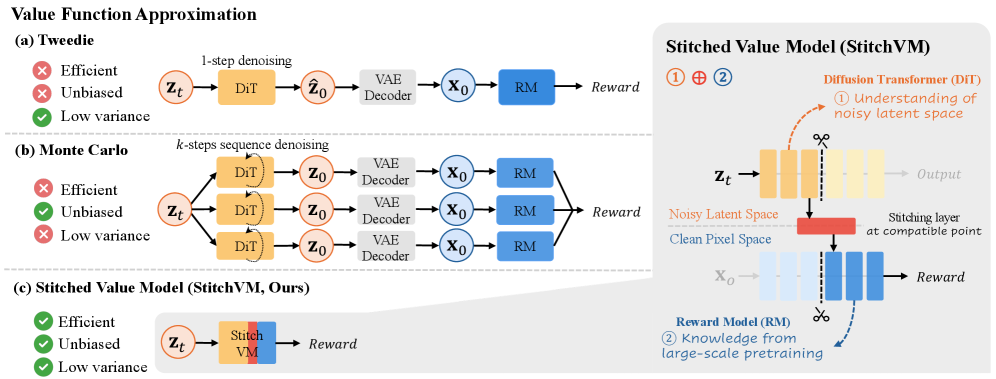
Figure 1 — StitchVM 구조 및 가치 모델 전환
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 StitchVM을 제안하여, 훈련된 diffusion backbone의 앞부분(head)과 pretrained reward model의 뒷부분(tail)을 stitching layer로 연결함으로써, 낮은 비용으로 noisy latent에 적응된 가치 모델을 구현한다. 첫 단계로, feature representation이 호환되는 지점을 찾아 linear mapping을 수행하고, 이후 경량화된 finetuning을 통해 representation gap을 최소화한다. 제안된 StitchVM은 SD 3.5 및 FLUX 등 다양한 backbone에 적용 가능하며, 학습 비용이 약 10 GPU-hours 내외로 매우 경제적이다. 실험 결과, StitchVM을 적용한 DPS (Diffusion Posterior Sampling)는 기존 대비 3.2배의 속도 향상과 함께 peak GPU 메모리를 50% 절감하는 성과를 보였다. 또한, DiffusionNFT와의 결합에서도 2.3배의 효율성 개선을 달성하였으며, 이는 중간 단계(intermediate noisy latents)에서의 직접적인 value supervision 덕분이다. [Figure 2] [Table 1]
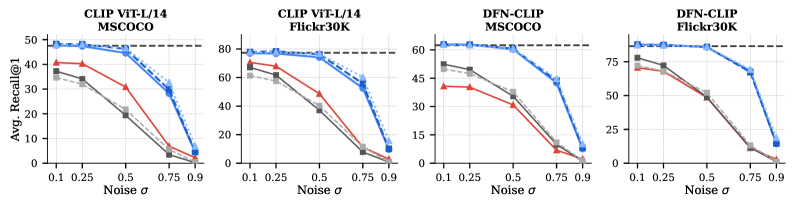
Figure 2 — 다양한 노이즈 레벨에서의 성능 비교
4. Conclusion & Impact (결론 및 시사점)
본 연구는 모델 stitching 기법을 noisy latent regime으로 확장하여, 강력한 pixel-space 보상 지식을 효율적으로 전이하는 실용적인 해법을 제시하였다. StitchVM은 별도의 대규모 학습 없이도 기존 diffusion 모델과 reward model의 강점을 결합할 수 있어, 생성형 AI의 제어 가능성(controllability)과 정렬(alignment) 기술 발전에 중요한 토대가 된다. 이 접근법은 추론 시 steering 비용을 획기적으로 낮추고, 훈련 시의 학습 효율을 높여 실무적인 AI 파이프라인 최적화에 기여할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Reproducing, Analyzing, and Detecting Reward Hacking in Rubric-Based Reinforcement Learning
- [논문리뷰] Geo-Align: Video Generation Alignment via Metric Geometry Reward
- [논문리뷰] MARBLE: Multi-Aspect Reward Balance for Diffusion RL
- [논문리뷰] FP4 Explore, BF16 Train: Diffusion Reinforcement Learning via Efficient Rollout Scaling
- [논문리뷰] Geometry-Guided Reinforcement Learning for Multi-view Consistent 3D Scene Editing
Review 의 다른글
- 이전글 [논문리뷰] SpecBench: Measuring Reward Hacking in Long-Horizon Coding Agents
- 현재글 : [논문리뷰] Stitched Value Model for Diffusion Alignment
- 다음글 [논문리뷰] The Unlearnability Phenomenon in RLVR for Language Models
댓글