[논문리뷰] The Unlearnability Phenomenon in RLVR for Language Models
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yulin Chen, He He, Chen Zhao
1. Key Terms & Definitions (핵심 용어 및 정의)
- RLVR (Reinforcement Learning with Verifiable Reward): 수학, 코딩 등 정답이 명확한 작업에서 LLM의 추론 능력을 향상시키기 위해 보상 신호를 활용하는 강화학습 기법입니다.
- Unlearnable Examples: 학습 과정에서 정답을 맞힌 rollouts이 존재함에도 불구하고, 모델의 성능 향상이 관찰되지 않거나 보상이 정체되는 데이터 샘플을 의미합니다.
- GRPO (Group Relative Policy Optimization): RLVR에서 표준적으로 사용되는 알고리즘으로, 그룹 내 rollouts의 보상 분산을 활용하여 정책을 최적화합니다.
- Gradient Similarity: 서로 다른 데이터 샘플 혹은 학습 과정 간의 기울기 벡터들이 공유하는 유사도를 의미하며, 이는 모델이 학습하는 지식의 전이 가능성을 판단하는 지표로 활용됩니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM 학습 과정에서 특정 문제들이 정답 보상을 받음에도 불구하고 왜 지속적으로 학습되지 않는지(Unlearnability)라는 역설적인 현상을 규명합니다. 저자들은 기존의 RLVR 접근 방식이 모든 데이터에 대해 보상 신호를 제공하지만, 특정 하드 샘플의 경우 모델이 이를 학습하지 못하고 정체되는 현상을 발견하였습니다 [Figure 1]. 이는 단순히 보상 신호가 부족하거나 최적화 과정의 문제로 치부하기 어려운 근본적인 한계점이 존재함을 시사하며, 이에 대한 체계적인 분석이 필요합니다 [Figure 1].
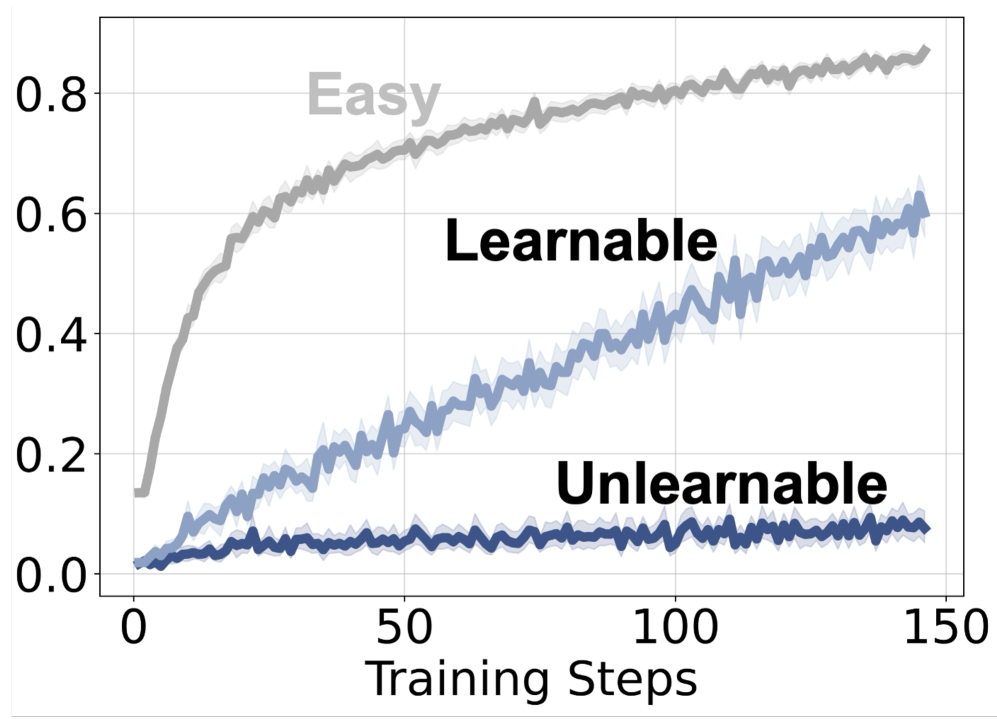
Figure 1 — 예제별 학습 보상 역학
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Unlearnability 현상을 설명하기 위해 positive rollout의 부족, 기울기 정규화(Clipping 및 KL 페널티) 효과, 그리고 기울기 간섭(Gradient Interference) 등 세 가지 핵심 가설을 실험적으로 검증하였습니다. 실험 결과, 이들 요인을 보정하거나 제거하더라도 학습 불가능한 현상은 해소되지 않았으며, 이를 통해 해당 문제가 최적화 기법의 결함이 아님을 입증하였습니다 [Figure 2, Figure 4, Figure 5].
대신 저자들은 cross-example gradient analysis를 통해, 학습 불가능한 샘플들이 최적화 공간 내에서 gradient outliers임을 확인하였습니다 [Figure 6]. 또한 정성적 분석 결과, 모델은 정답을 맞히더라도 실제로는 논리적인 추론이 아닌 'shortcut'이나 'fake reasoning'을 사용하여 보상을 획득하고 있음이 드러났습니다 [Figure 7]. 데이터 증강(Data Augmentation) 및 커리큘럼 학습 또한 근본적인 표현(Representation) 문제를 해결하지 못했지만, 학습 초기 단계의 mid-training이 표현 정렬(Representation Alignment)을 개선하여 문제를 완화할 수 있음을 확인하였습니다 [Figure 11].
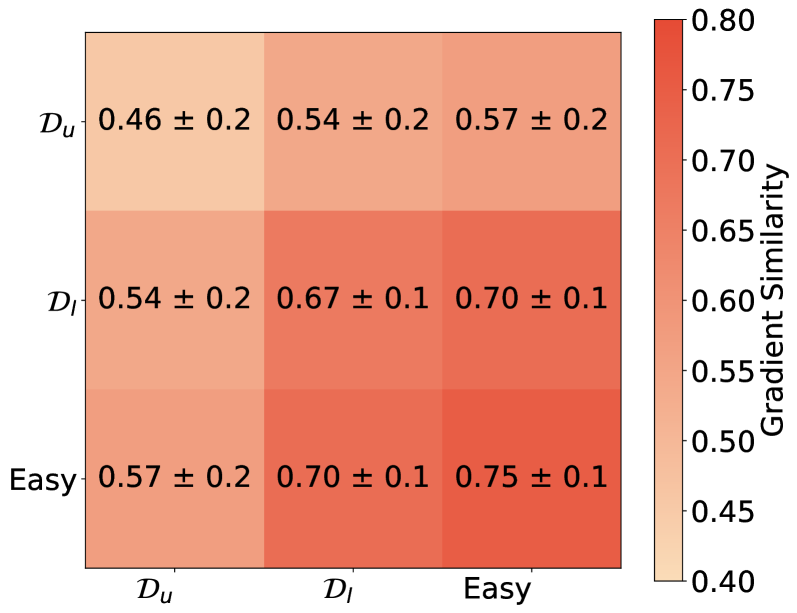
Figure 6 — 데이터별 기울기 유사도 분포
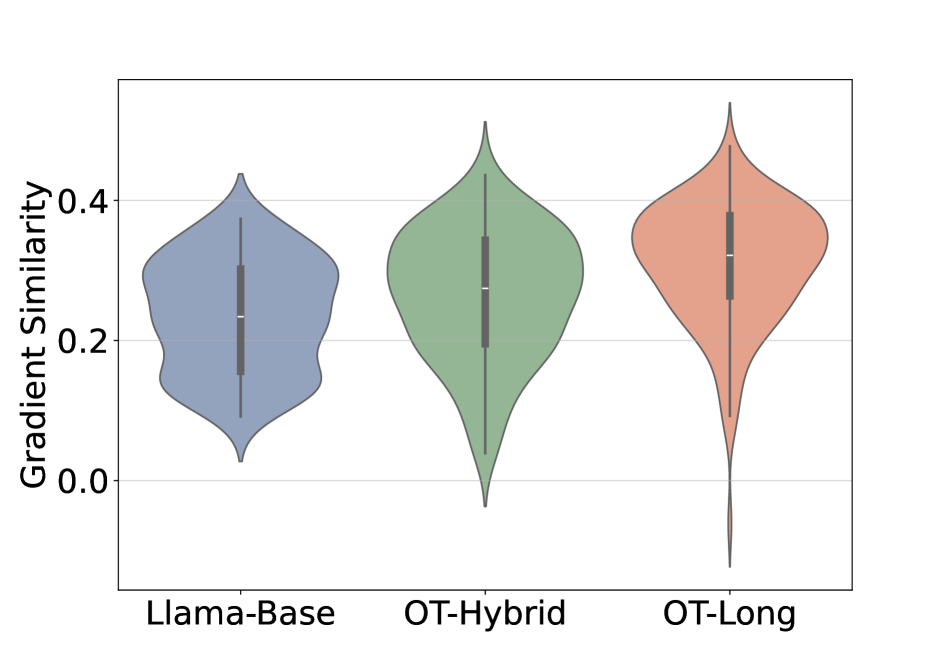
Figure 11 — Mid-training이 기울기 유사도에 미치는 영향
4. Conclusion & Impact (결론 및 시사점)
본 연구는 RLVR 학습에서 발생하는 데이터의 학습 불가능성이 최적화 기법이 아닌, 모델 내부의 결함 있는 표현(Flawed Representation)에서 기인한다는 점을 체계적으로 밝혔습니다. 결과적으로 outcome-based RL만으로는 모델의 근본적인 추론 결함을 교정하는 데 한계가 있음을 시사합니다. 본 논문은 미래 LLM 학습 파이프라인에서 RL 이전 단계인 mid-training의 중요성을 강조하며, 단순 보상 학습을 넘어선 표현 중심의 강화학습 연구로의 전환 필요성을 제시합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] ThinkTwice: Jointly Optimizing Large Language Models for Reasoning and Self-Refinement
- [논문리뷰] Heterogeneous Agent Collaborative Reinforcement Learning
- [논문리뷰] Exploration v.s. Exploitation: Rethinking RLVR through Clipping, Entropy, and Spurious Reward
- [논문리뷰] Beyond Entropy: Correctness-Aware Advantage Shaping via Contrastive Policy Optimization
- [논문리뷰] Agon: Competitive Cross-Model RL with Implicit Rival Grading of Reasoning
Review 의 다른글
- 이전글 [논문리뷰] Stitched Value Model for Diffusion Alignment
- 현재글 : [논문리뷰] The Unlearnability Phenomenon in RLVR for Language Models
- 다음글 [논문리뷰] Toto 2.0: Time Series Forecasting Enters the Scaling Era
댓글