[논문리뷰] Toto 2.0: Time Series Forecasting Enters the Scaling Era
링크: 논문 PDF로 바로 열기
메타데이터
저자: Emaad Khwaja, Chris Lettieri, Gerald Woo, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Contiguous Patch Masking (CPM): Autoregressive decoding의 순차적 비효율성을 개선하기 위해, 훈련 시 연속적인 마스킹 구간을 사용하고 추론 시 단일 Forward pass로 예측하는 병렬 예측 방식입니다.
- u-μP (Unit-scaled Maximal Update Parametrization): 모델의 width가 변하더라도 최적의 Learning rate가 유지되도록 파라미터 업데이트를 정규화하여, 소규모 모델에서 찾은 Hyperparameter를 대규모 모델로 직접 전이할 수 있게 하는 기술입니다.
- NorMuon: Pinball loss의 Sign-valued gradient 환경에서 성능이 저하되는 AdamW의 한계를 극복하기 위해, 행(row) 단위 정규화를 통해 Neuron 간 기여도를 균형 있게 조정하는 최적화 기법입니다.
- Quantile Output Head: 고정된 분포 대신 9개의 Quantile 수준을 예측하여 다중 확률 예측을 수행하며, 대규모 Scaling 상황에서 수치적 안정성을 제공하는 출력 구조입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 TSFM(Time Series Foundation Models)이 NLP나 Vision 모델과 달리 모델 크기가 커져도 예측 성능이 정체되거나 저하되는 Scaling의 불확실성 문제를 해결하고자 합니다. 기존 연구들은 독립적인 튜닝을 통해 다양한 크기의 모델을 구현했으나, 이는 계산 자원의 낭비를 초래하며 체계적인 성능 개선을 보장하지 못했습니다. 저자들은 데이터와 아키텍처, 훈련 방식을 최적화함으로써 Toto 2.0 패밀리가 모든 크기에서 일관되게 성능이 향상되는 Scaling 현상을 입증하고자 합니다 [Figure 1].
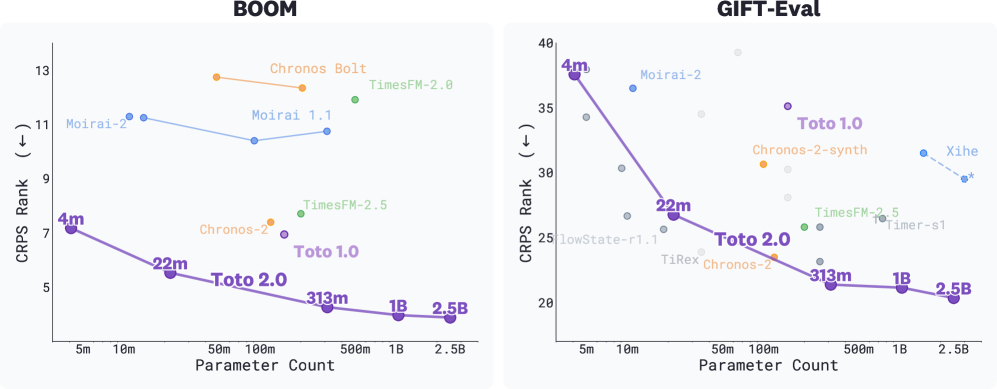
Figure 1 — 모델 크기별 성능 개선
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Toto 2.0을 위해 Contiguous Patch Masking, Quantile Output Head, 그리고 NorMuon을 포함한 정교한 아키텍처 및 훈련 레시피를 제안합니다 [Figure 2]. 특히, 10M 규모의 Proxy 모델에서 u-μP를 사용하여 최적화된 Hyperparameter를 4M부터 2.5B 파라미터까지의 타겟 모델로 전이하는 효율적인 파이프라인을 구축했습니다 [Figure 4]. 훈련 데이터는 전적으로 Datadog의 내부 Observability 메트릭과 합성 데이터로 구성하여, 범용 벤치마크에서의 Cross-domain 일반화 능력을 검증했습니다 [Figure 3]. 실험 결과, Toto 2.0은 BOOM, GIFT-Eval, TIME 벤치마크에서 기존 SOTA 모델들을 제치고 모든 모델 크기에서 Pareto frontier를 달성하는 성능 우위를 보였습니다 [Figure 5, 8]. 특히 22M 모델은 이전 Toto 1.0과 동일한 품질을 7배 적은 파라미터로 달성하였으며, 2.5B 모델은 최고 수준의 예측 정확도를 기록했습니다 [Table 1].
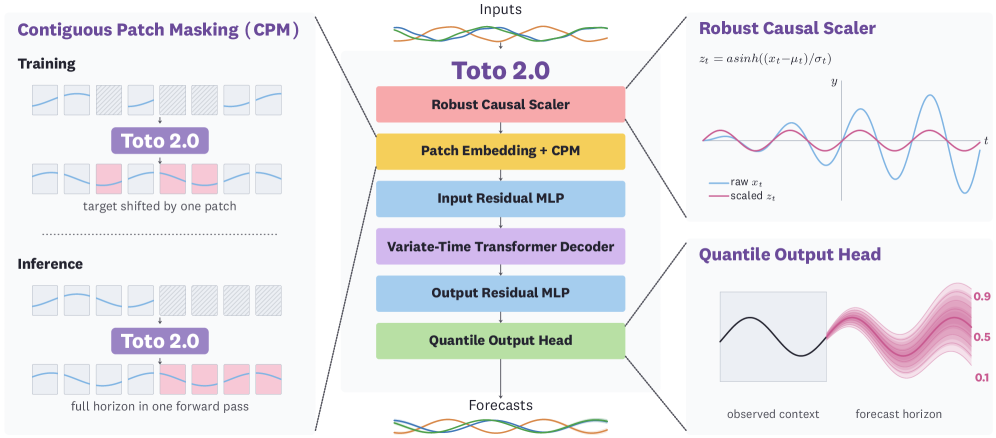
Figure 2 — Toto 2.0 아키텍처

Figure 4 — u-μP 기반 하이퍼파라미터 전이
4. Conclusion & Impact (결론 및 시사점)
본 논문은 TSFM 분야에서도 모델 크기 확장이 예측 성능 향상으로 직결되는 Scaling의 시대를 열었음을 증명했습니다. Toto 2.0의 성공적인 Scaling 법칙은 TSFM 연구가 데이터 큐레이션 및 모델 설계에서 더욱 성숙한 단계로 진입했음을 시사합니다. 향후 연구는 고차원 메트릭의 독특한 특성을 반영한 Multimodal World Model 구축과 클래식 통계 모델과의 성능 격차를 좁히는 방향으로 나아갈 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Xiaomi-Robotics-1: Scaling Vision-Language-Action Models with over 100K Hours of Real-World Trajectories
- [논문리뷰] Principled Analysis of Deep Reinforcement Learning Evaluation and Design Paradigms
- [논문리뷰] EdgeBench: Unveiling Scaling Laws of Learning from Real-World Environments
- [논문리뷰] DataComp-VLM: Improved Open Datasets for Vision-Language Models
- [논문리뷰] OpenThoughts-Agent: Data Recipes for Agentic Models
Review 의 다른글
- 이전글 [논문리뷰] The Unlearnability Phenomenon in RLVR for Language Models
- 현재글 : [논문리뷰] Toto 2.0: Time Series Forecasting Enters the Scaling Era
- 다음글 [논문리뷰] Uni-Edit: Intelligent Editing Is A General Task For Unified Model Tuning
댓글