[논문리뷰] Uni-Edit: Intelligent Editing Is A General Task For Unified Model Tuning
링크: 논문 PDF로 바로 열기
저자: Dian Zheng, Manyuan Zhang, Hongyu Li, Hongbo Liu, Kai Zou, Kaituo Feng, Hongsheng Li
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- UMM (Unified Multimodal Models): 시각적 이해, 생성, 편집 능력을 하나의 latent space 내에서 통합적으로 수행하도록 설계된 모델.
- Uni-Edit: 이해(Understanding)와 생성(Generation) 능력을 동시에 강화하기 위해 제안된 지능형 이미지 편집 작업.
- Nano-Pro: 본 논문에서 편집 데이터 생성을 위해 사용한 강력한 성능의 이미지 편집 백본 모델.
- BAGEL: 본 논문의 베이스 모델로 사용된 최신 Unified Multimodal Model.
- Intelligent Editing: 단순히 객체를 수정하는 수준을 넘어, VQA(Visual Question Answering)와 같은 추론 과정을 동반한 복합적인 편집 지시를 수행하는 방식.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 UMM 학습 시 이해와 생성 작업 간에 발생하는 아키텍처적 충돌과 이로 인한 성능 트레이드오프 문제를 해결하고자 한다. 기존의 다중 작업 학습(Multi-task learning)은 복잡한 파이프라인과 데이터 균형 조정 기법을 필요로 하며, 종종 한 작업의 성능 향상이 다른 작업의 저하를 초래하는 한계가 있다. 저자들은 기존의 편집 데이터셋이 지나치게 단순한 지시어로 구성되어 있어 모델의 이해 능력을 충분히 활용하지 못한다는 점을 지적한다. 따라서 본 논문은 이해와 생성 능력을 동시에 극대화할 수 있는 새로운 일반적인 튜닝 작업으로서 지능형 편집을 제안하며, [Figure 2]에 제시된 데이터 구축 파이프라인을 통해 이러한 한계를 극복하고자 한다.
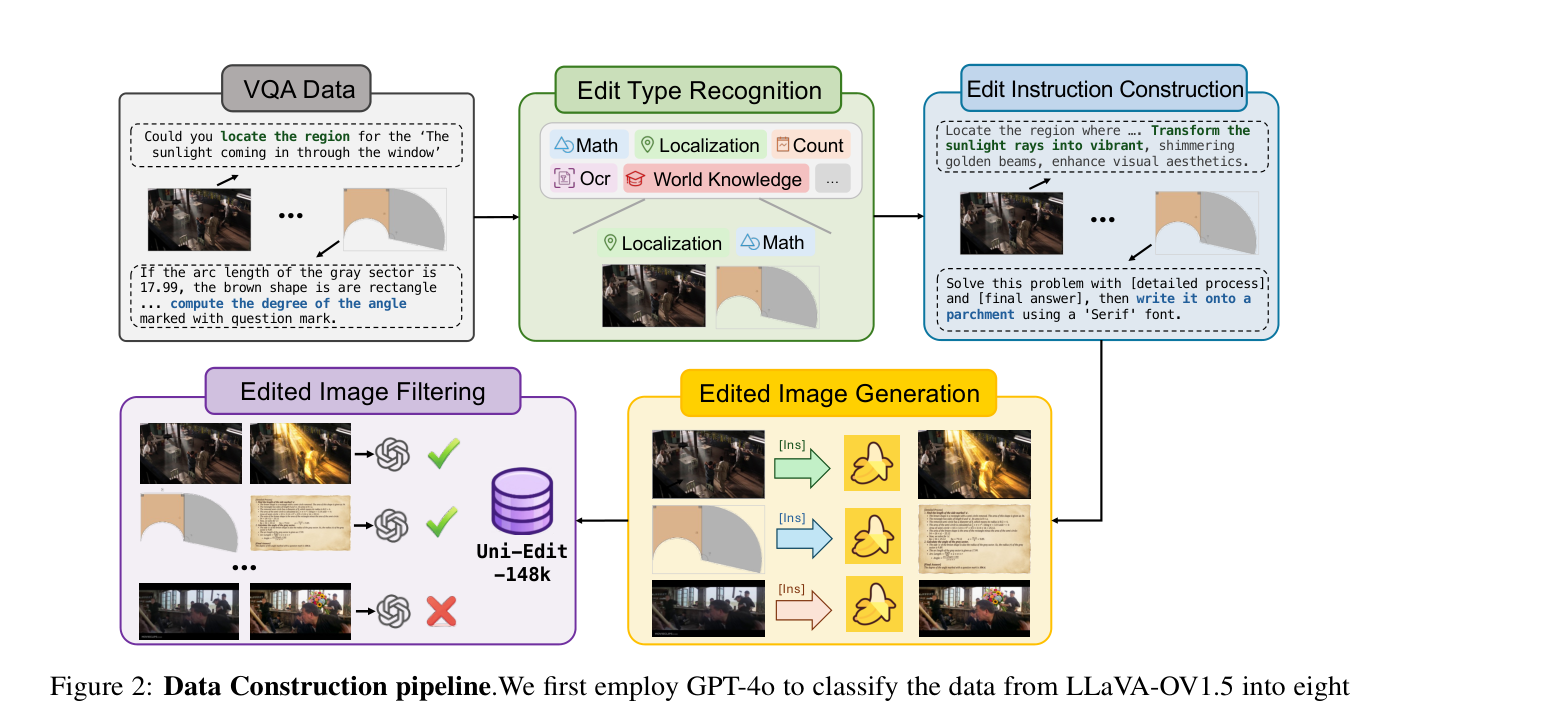
Figure 2 — VQA 데이터를 지능형 편집 지시어로 변환하는 핵심 데이터 구축 프로세스를 도식화함
## 3. Method & Key Results (제안 방법론 및 핵심 결과) Uni-Edit은 다양한 VQA 데이터를 추론 집약적 편집 지시문으로 변환하고 이를 통해 모델을 단일 단계에서 튜닝하는 효율적인 프레임워크를 제공한다. 저자들은 GPT-4o를 활용하여 LLaVA-OV1.5 데이터를 7개의 범주로 분류한 뒤, 수학적 추론, OCR, 공간 지각 등 고차원적인 지시사항을 포함한 Uni-Edit-148k 데이터셋을 구축하였다. 또한, 학습 중 VAE(Variational Autoencoder) feature dropout을 통해 이해 능력을 담당하는 ViT backbone의 활용도를 극대화하고, [Figure 4]의 2단계 학습 파이프라인을 통해 모델의 성능을 향상시켰다. 실험 결과, BAGEL 모델을 Uni-Edit으로 튜닝했을 때 MMMU 벤치마크 점수가 52.8에서 53.6으로, MathVista가 73.2에서 73.8로, GenEval이 0.87에서 0.89로 개선되는 등 이해, 생성, 편집 모든 영역에서 성능 향상을 달성하였다. 이는 [Table 2]를 통해 확인할 수 있듯, 별도의 auxiliary 모듈 없이도 종합적인 성능 향상을 도출했다는 점이 핵심이다.

Table 2 — 제안 모델(Uni-Edit)이 기존 베이스라인(BAGEL 등) 대비 이해, 생성, 편집 성능을 어떻게 개선하는지 보여주는 주요 실험 결과
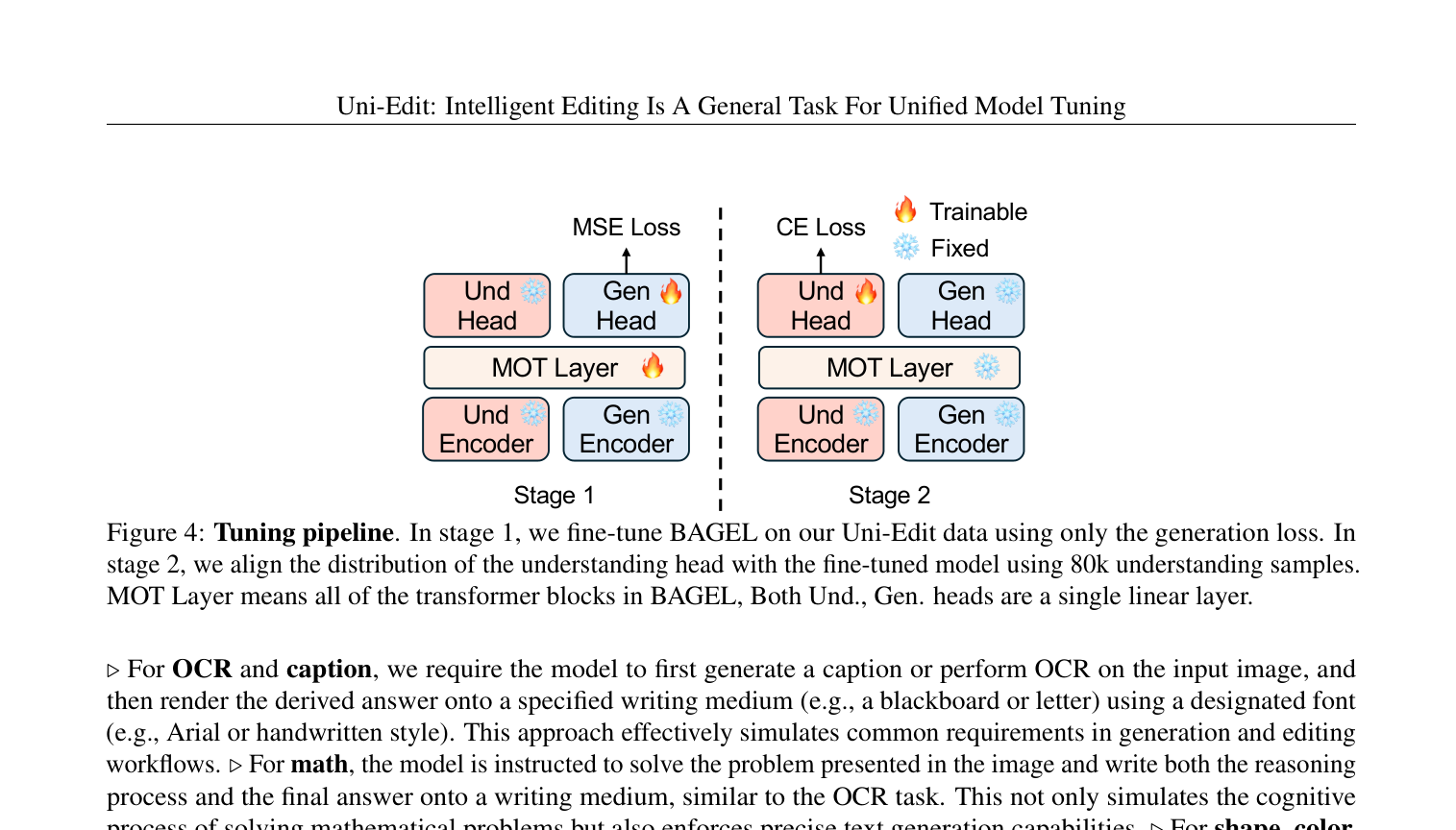
Figure 4 — Uni-Edit 학습을 위한 2단계 튜닝 파이프라인 구조를 설명함
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 지능형 편집 작업이 UMM 튜닝을 위한 효율적이고 일반적인 작업이 될 수 있음을 입증하였다. Uni-Edit 프레임워크는 기존 모델의 아키텍처를 변경하지 않고도 데이터와 학습 패러다임 설계를 통해 시각적 이해와 생성 능력의 상호 보완적 발전을 가능케 한다. 본 연구에서 제안한 자동화된 데이터 합성 파이프라인은 향후 다양한 도메인의 데이터를 확장 가능한 형태로 통합하는 데 중요한 기반이 될 것이며, UMM의 범용적 성능 개선을 위한 새로운 방법론적 패러다임을 제시했다는 점에서 큰 의의가 있다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] InternVL-U: Democratizing Unified Multimodal Models for Understanding, Reasoning, Generation and Editing
- [논문리뷰] Less is Enough: Synthesizing Diverse Data in Feature Space of LLMs
- [논문리뷰] Streaming Video Instruction Tuning
- [논문리뷰] EHR-R1: A Reasoning-Enhanced Foundational Language Model for Electronic Health Record Analysis
- [논문리뷰] RecGPT-V3 Technical Report
Review 의 다른글
- 이전글 [논문리뷰] Toto 2.0: Time Series Forecasting Enters the Scaling Era
- 현재글 : [논문리뷰] Uni-Edit: Intelligent Editing Is A General Task For Unified Model Tuning
- 다음글 [논문리뷰] UniT: Unified Geometry Learning with Group Autoregressive Transformer
댓글