[논문리뷰] UniT: Unified Geometry Learning with Group Autoregressive Transformer
링크: 논문 PDF로 바로 열기
메타데이터
저자: Haotian Wang, Yusong Huang, Zhaonian Kuang, Hongliang Lu, Xinhu Zheng, Meng Yang, Gang Hua
1. Key Terms & Definitions (핵심 용어 및 정의)
- Group Autoregressive Transformer: 센서 관측 그룹을 기본 autoregressive 단위로 처리하여 온라인 및 오프라인 추론을 통합하는 새로운 프레임워크입니다.
- Queue-Style KV Caching: long-horizon 추론 시 KV-cache의 메모리 소모를 고정된 용량으로 제한하여 일정한 계산 복잡도를 유지하는 메커니즘입니다.
- Scale-Adaptive Geometry Loss: 상대적 기하학적 제약과 부분적인 절대적 스케일 항을 결합하여 metric-scale 추정을 점진적으로 학습하게 하는 손실 함수입니다.
- Anchor-Free Relational Modeling: 고정된 기준 프레임에 의존하지 않고 시점 간 상대적 관계를 모델링하여 메모리 효율성과 스케일 일반화를 높이는 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 Feed-forward 기하학적 인식 모델들이 파편화되어 있다는 문제를 해결하고자 합니다. 현재 연구들은 온라인 스트리밍 인식, 오프라인 다중 뷰 재구성, metric-scale 추정, 긴 시퀀스 확장성 등 각기 다른 Paradigm에 집중하고 있어 통합적인 프레임워크가 부재합니다. 기존의 autoregressive 방식은 시퀀스 길이가 길어질수록 KV-cache 메모리 소모가 선형적으로 증가하여 long-horizon 추론에 한계가 명확합니다 [Figure 2]. 또한 metric-scale 학습은 데이터 세트 간 일반화가 어렵고, 기존 모델들은 이를 위해 과도하게 복잡한 스케일 회귀를 수행하거나 환경에 따른 스케일 왜곡을 겪는다는 문제가 있습니다.
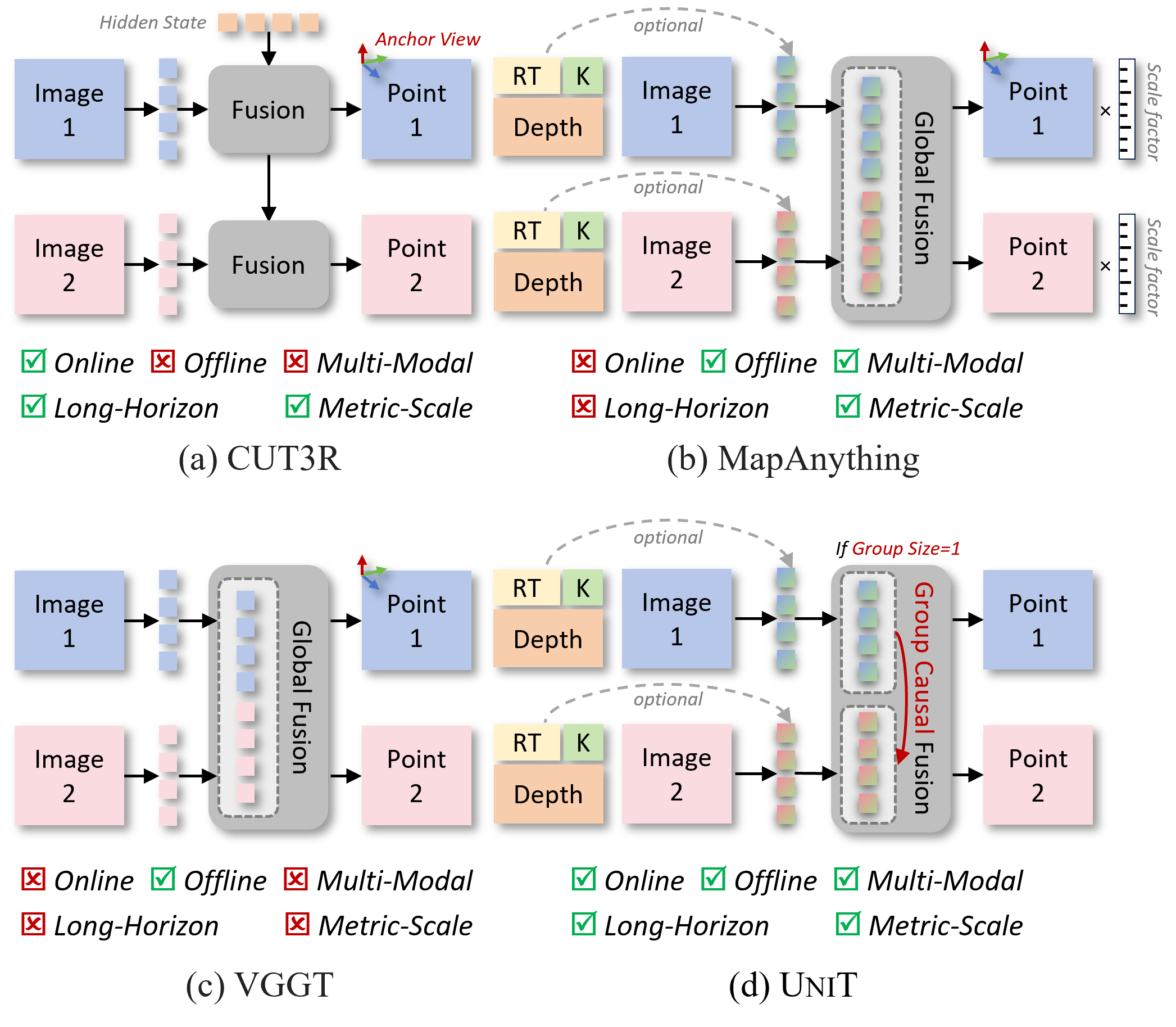
Figure 2 — 기존 및 제안 방식 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 센서 관측 그룹을 autoregressive 단위로 처리하여 다양한 view configuration을 단일 프레임워크로 통합하는 UniT를 제안합니다 [Figure 3]. UniT는 Bidirectional Attention(그룹 내부)과 Causal Attention(그룹 간)을 결합하여 온라인과 오프라인 방식을 유연하게 전환합니다 [Figure 4]. Queue-Style KV Caching을 통해 오래된 메모리를 상시 삭제함으로써 long-horizon 환경에서도 계산 복잡도를 $O(Q)$로 제한하며, Modal Attention 모듈을 통해 Depth Map, Camera Intrinsics, Extrinsics 등 이기종 데이터를 효율적으로 통합합니다 [Figure 5, Figure 6]. 실험 결과, UniT는 7-Scenes, NRGBD 등 10개 벤치마크에서 SOTA 수준의 성능을 달성하였습니다 [Table 3, Table 5]. 특히 metric-scale 추정 성능은 기존 MapAnything 및 DepthAnything3 대비 더 우수한 정량적 지표(ATE, RMSE 등)를 보이며, 다양한 모달리티 조합과 긴 시퀀스에서도 일관된 성능 우위를 유지합니다 [Table 7, Table 8].
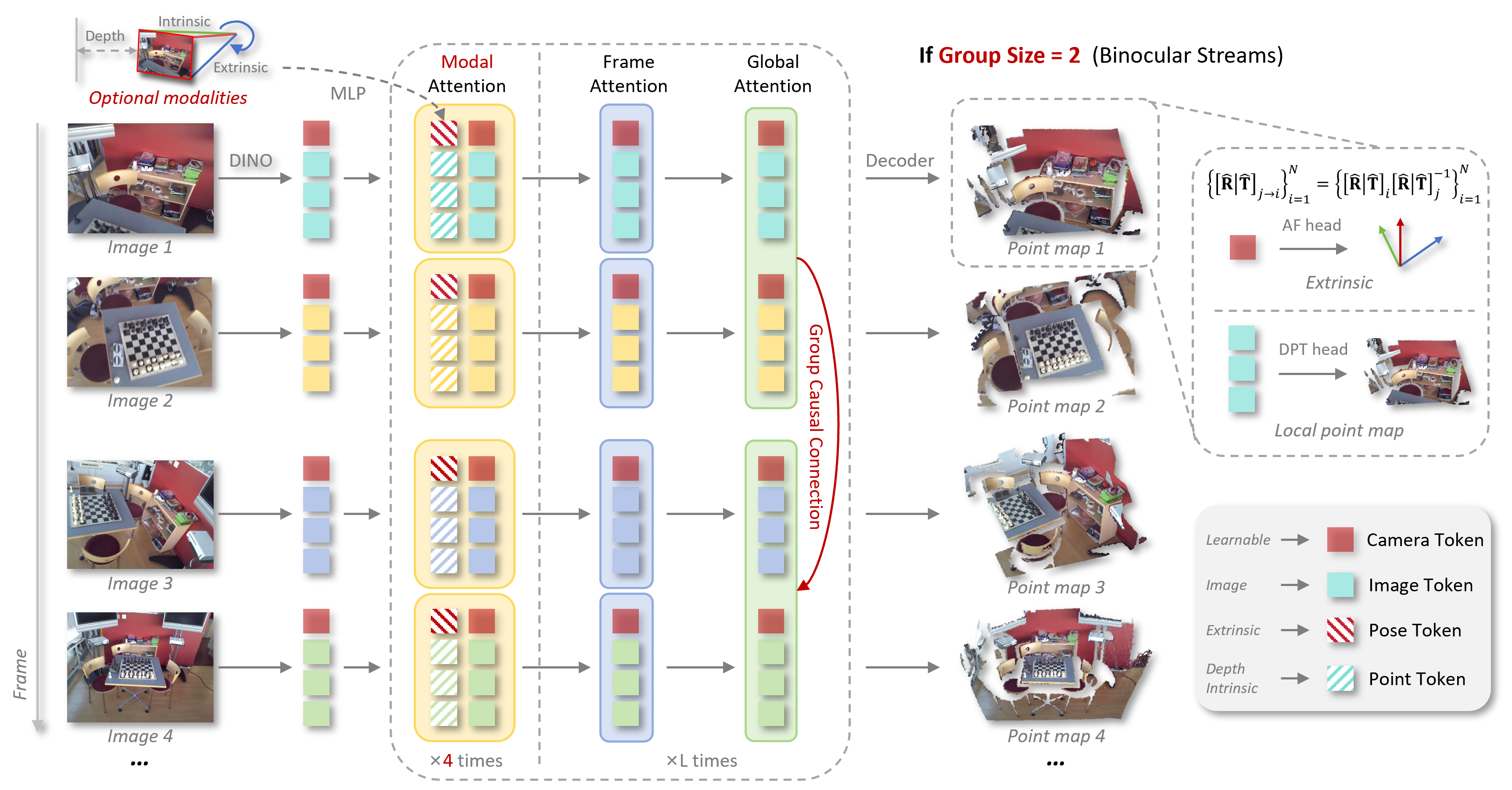
Figure 3 — UniT 모델 아키텍처
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Group Autoregressive Transformer를 통해 다양한 기하학적 인식 과제를 단일 Feed-forward 모델로 수렴시킨 UniT를 성공적으로 제시하였습니다. 이 프레임워크는 유연한 추론 모드 전환과 메모리 효율적인 긴 시퀀스 처리를 지원함으로써, robotics나 autonomous driving과 같은 실제 산업 현장에서의 확장 가능성을 크게 증명했습니다. 본 연구가 도입한 scale-adaptive 학습 방식과 anchor-free 모델링은 3D foundation model의 metric-scale 일반화 문제를 해결하는 핵심적인 전환점이 될 것으로 기대됩니다.
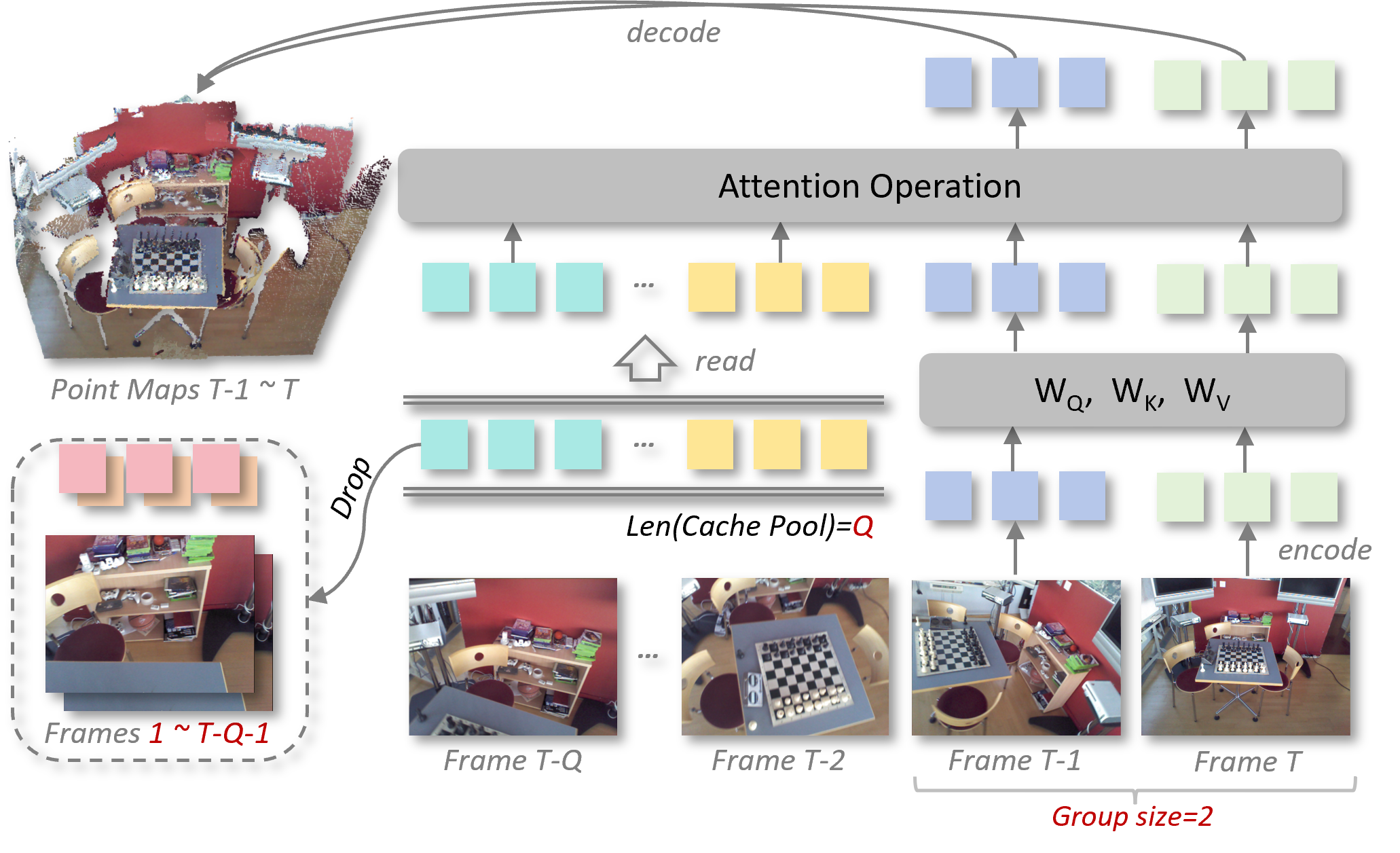
Figure 6 — Queue-style KV Caching
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] DualCamCtrl: Dual-Branch Diffusion Model for Geometry-Aware Camera-Controlled Video Generation
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] xHC: Expanded Hyper-Connections
- [논문리뷰] Xiaomi-Robotics-1: Scaling Vision-Language-Action Models with over 100K Hours of Real-World Trajectories
- [논문리뷰] When Does Muon Help Agentic Reinforcement Learning?
Review 의 다른글
- 이전글 [논문리뷰] Uni-Edit: Intelligent Editing Is A General Task For Unified Model Tuning
- 현재글 : [논문리뷰] UniT: Unified Geometry Learning with Group Autoregressive Transformer
- 다음글 [논문리뷰] Video2GUI: Synthesizing Large-Scale Interaction Trajectories for Generalized GUI Agent Pretraining
댓글