[논문리뷰] Video2GUI: Synthesizing Large-Scale Interaction Trajectories for Generalized GUI Agent Pretraining
링크: 논문 PDF로 바로 열기
메타데이터
저자: Weimin Xiong, Shuhao Gu, Bowen Ye, Zihao Yue, Lei Li, Feifan Song, Sujian Li, Hao Tian
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Video2GUI: 인터넷상의 비디오로부터 GUI 상호작용 궤적(trajectory)을 자동으로 추출하고 주석을 달아주는 확장 가능한 프레임워크입니다.
- WildGUI: 5억 개의 비디오 메타데이터를 필터링하여 구축한 대규모 GUI 사전 학습 데이터셋으로, 1,200만 개의 상호작용 궤적을 포함합니다.
- Action Spatial Grounding: 비디오에서 추출된 GUI 작업 텍스트 명령을 화면의 정확한 좌표(bounding box)로 매핑하는 기술입니다.
- POMDP: GUI 에이전트의 상호작용 과정을 정의하는 프레임워크로, Partially Observable Markov Decision Process의 약어입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의)
- 본 논문은 GUI 에이전트의 일반화 성능을 저해하는 대규모 학습 데이터의 부족 문제를 해결하고자 합니다.
- 기존 연구들은 고비용의 수동 주석 데이터셋이나 제한적인 시뮬레이션 환경에 의존하여 확장성에 한계를 보입니다.
- 실제 인터넷 비디오는 풍부한 GUI 활용 사례를 포함하지만, 관련 없는 영상 필터링과 비구조적인 raw 비디오로부터 정확한 액션 궤적을 추출하는 과정이 복잡하다는 기술적 도전 과제가 있습니다.
[Figure 1]에 제시된 파이프라인은 이러한 데이터 구축 과정의 비효율성을 자동화된 필터링과 추출 방식으로 개선합니다.
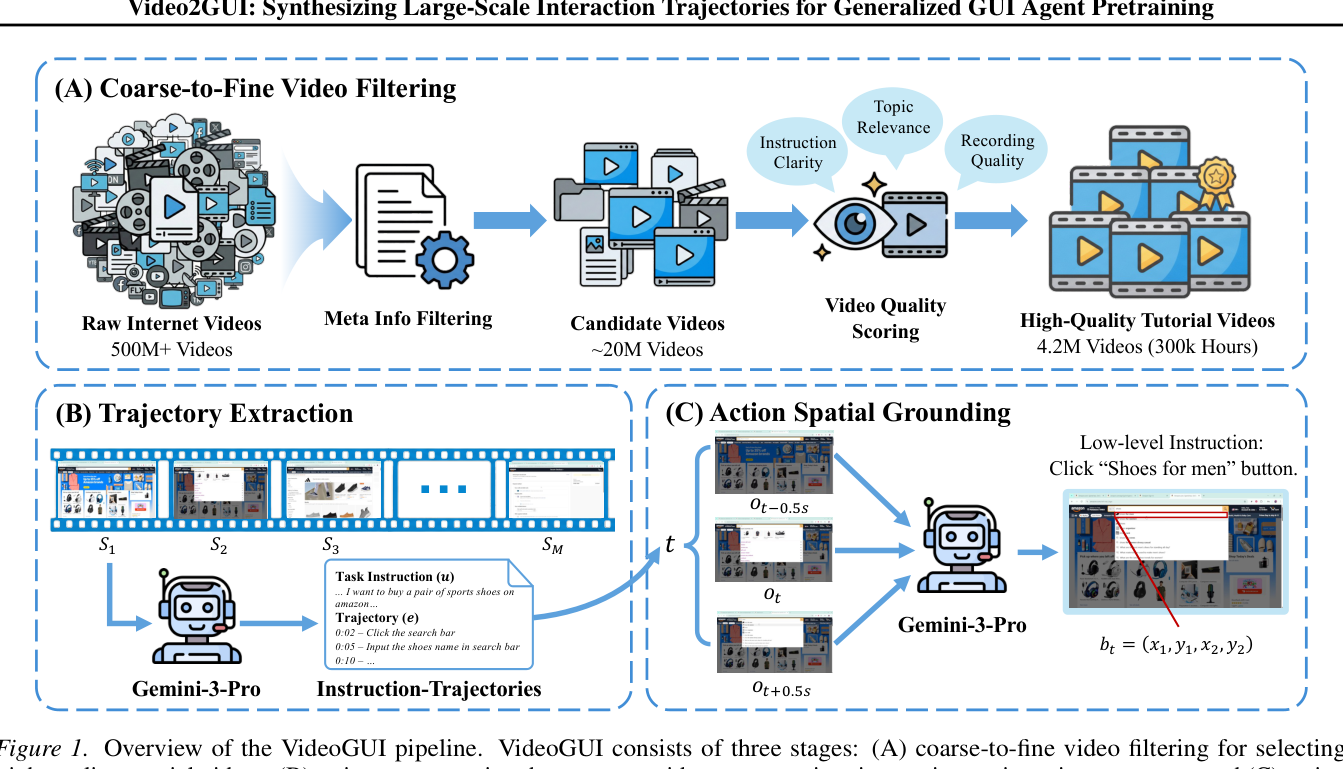
Figure 1 — Video2GUI의 데이터 처리 및 추출 파이프라인을 설명하는 핵심 아키텍처 다이어그램
## 3. Method & Key Results (제안 방법론 및 핵심 결과)
- 본 논문은 coarse-to-fine filtering, trajectory extraction, action spatial grounding으로 구성된 Video2GUI 파이프라인을 통해 대규모 데이터를 구축합니다.
- 메타데이터 기반의 1차 필터링 후, Gemini-3-Pro를 활용하여 영상의 품질과 교육적 가치를 평가하고 고품질의 영상만 선별하여 구조화된 상호작용 궤적을 생성합니다.
- Qwen2.5-VL과 Mimo-VL 모델에 WildGUI를 사전 학습시킨 결과, 다수의 GUI grounding 및 에이전트 벤치마크에서 기존 SOTA 모델 대비 5~20% 향상된 일관된 성능 개선을 입증하였습니다.
- 특히 OSWorld-G와 ScreenSpot-Pro 벤치마크에서 기존의 강력한 베이스라인 모델들을 상회하는 Grounding 능력을 보여주었습니다.
[Table 1]은 기존 데이터셋들과 비교하여 WildGUI가 가진 압도적인 데이터 스케일과 환경 커버리지를 명확히 보여줍니다.
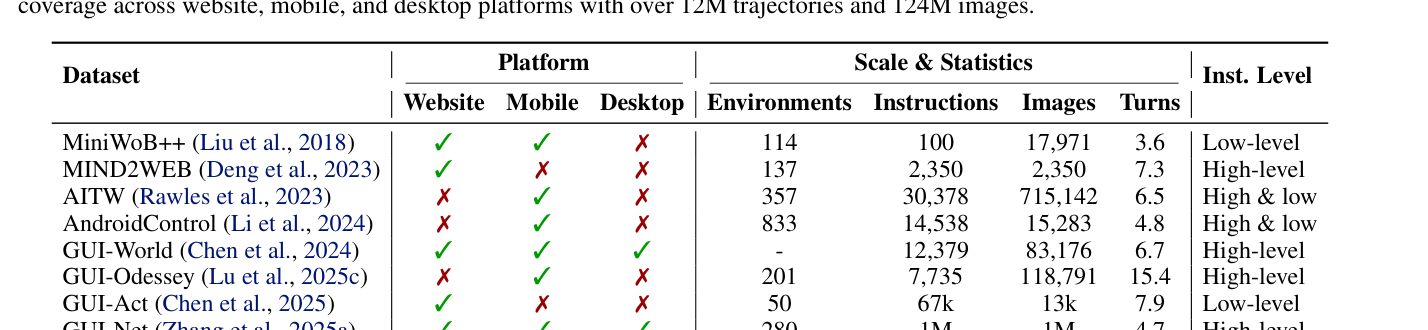
Table 1 — WildGUI 데이터셋이 기존 데이터셋과 비교하여 가지는 규모와 다양성을 나타내는 주요 비교 테이블
## 4. Conclusion & Impact (결론 및 시사점)
- 본 논문은 대규모 비정형 인터넷 비디오로부터 고품질의 GUI 상호작용 데이터를 체계적으로 추출하는 자동화된 파이프라인을 성공적으로 제안하였습니다.
- 이를 통해 구축된 WildGUI 데이터셋은 GUI 에이전트가 실세계의 복잡하고 다양한 환경에서 일반화 성능을 높이는 데 강력한 기반을 제공합니다.
- 학계와 산업계는 본 연구를 통해 GUI 에이전트 개발 시 직면하는 데이터 희소성 문제를 해결하고, 에이전트의 실질적인 자율 수행 능력을 한 단계 높일 수 있는 전기를 마련하게 되었습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] BTL-UI: Blink-Think-Link Reasoning Model for GUI Agent
- [논문리뷰] Understanding Reasoning from Pretraining to Post-Training
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] MuseBench: Benchmarking Intent-Level Audiovisual Arts Understanding in MLLMs
- [논문리뷰] UI-MOPD: Multi-Platform On-Policy Distillation for Continual GUI Agent Learning
Review 의 다른글
- 이전글 [논문리뷰] UniT: Unified Geometry Learning with Group Autoregressive Transformer
- 현재글 : [논문리뷰] Video2GUI: Synthesizing Large-Scale Interaction Trajectories for Generalized GUI Agent Pretraining
- 다음글 [논문리뷰] You Only Need Minimal RLVR Training: Extrapolating LLMs via Rank-1 Trajectories
댓글