[논문리뷰] You Only Need Minimal RLVR Training: Extrapolating LLMs via Rank-1 Trajectories
링크: 논문 PDF로 바로 열기
메타데이터
저자: Zhepei Wei, Xinyu Zhu, Wei-Lin Chen, Chengsong Huang, Jiaxin Huang, Yu Meng
1. Key Terms & Definitions (핵심 용어 및 정의)
- RLVR (Reinforcement Learning with Verifiable Rewards): 수학적 정답과 같이 프로그래밍적으로 검증 가능한 보상을 사용하여 LLM의 추론 능력을 향상시키는 강화학습 패러다임입니다.
- SVD (Singular Value Decomposition): 행렬을 세 개의 행렬로 분해하여 고차원 데이터의 핵심 기저(Subspace)와 가중치를 추출하는 수학적 기법으로, 논문에서는 RLVR 학습 시 파라미터 업데이트의 주요 방향을 찾는 데 사용됩니다.
- Rank-1 Subspace: 파라미터 델타($\Delta\theta$)의 변동 중 정보량이 가장 많은 단일 주요 방향으로, 본 논문은 이 방향이 작업 관련 성능 변화의 대부분을 설명함을 발견했습니다.
- RELEX (REinforcement Learning EXtrapolation): RLVR 학습 초기의 짧은 궤적에서 Rank-1 subspace를 추출하고 선형 회귀(Linear Regression)를 통해 향후 체크포인트를 예측하는 학습 불필요(Training-free) 방법론입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 고비용의 RLVR 학습 과정에서 발생하는 막대한 컴퓨팅 자원 소비 문제를 해결하기 위해 고안되었습니다. 기존의 RLVR은 성능 향상을 위해 방대한 최적화 단계가 필수적이지만, 학습 궤적의 기하학적 구조에 대한 이해가 부족하여 효율적인 최적화가 어려웠습니다. 연구진은 RLVR 학습이 새로운 능력을 창조하기보다 이미 잠재된 능력을 증폭시키는 과정이라는 점에 주목하여, 초기 단계의 학습 역학(Dynamics)을 바탕으로 최종 모델을 예측할 수 있는지에 대한 의문을 제기합니다 [Figure 1]. 이를 통해 전체 학습을 수행하지 않고도 최종 성능에 도달할 수 있는 새로운 접근 방식이 요구됩니다.
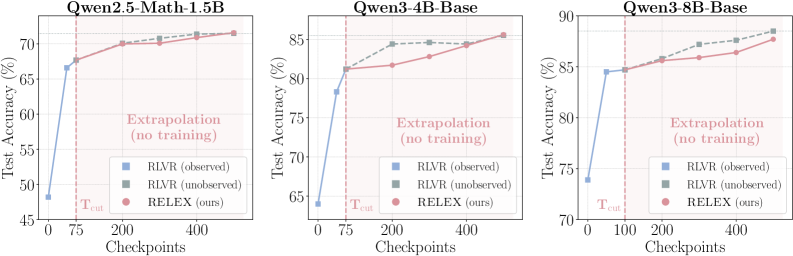
Figure 1 — RELEX의 전체 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 RLVR 학습 궤적이 extremely low-rank하며, rank-1 근사만으로도 대부분의 성능 향상을 캡처할 수 있다는 핵심 발견을 바탕으로 RELEX를 제안합니다 [Figure 2]. 제안된 RELEX는 (1) 첫 $T_{\text{cut}}$ 단계의 가중치 델타를 사용하여 Rank-1 subspace를 추정하고, (2) 이 공간으로 투영된 스칼라 계수를 선형 함수로 피팅한 뒤, (3) 미래의 체크포인트를 예측하는 3단계 과정을 거칩니다 [Figure 3]. Qwen2.5-Math-1.5B, Qwen3-4B-Base, Qwen3-8B-Base 모델을 대상으로 실험한 결과, RELEX는 전체 RLVR 학습 비용의 15%~20%만을 사용하여 기존 RLVR 성능과 대등하거나 능가하는 결과를 보였습니다 [Table 1]. 특히, 정량적 지표인 MATH 벤치마크에서 Qwen2.5-Math-1.5B 기준 71.6% (Full RLVR: 71.5%)의 성능을 달성하였으며, 5개의 외부 데이터셋(OOD)에서도 일반화 성능이 우수함을 입증하였습니다. 또한 rank-1 projection이 최적화 과정의 노이즈를 제거하는 spectral denoiser 역할을 하여 외삽(Extrapolation)의 안정성을 높인다는 점이 확인되었습니다 [Figure 5].
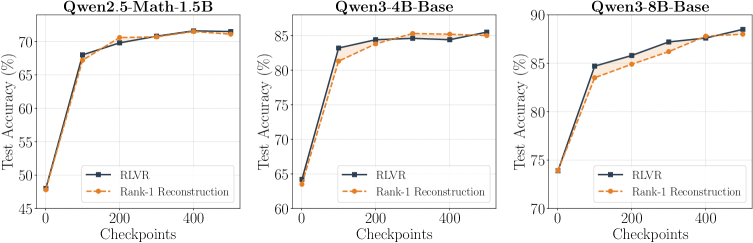
Figure 2 — Rank-1 SVD 재구성 성능
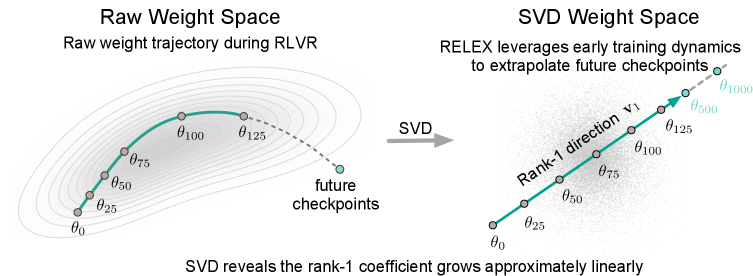
Figure 3 — Raw 궤적 및 RELEX 예측
4. Conclusion & Impact (결론 및 시사점)
본 연구는 RLVR의 학습 과정이 고차원 파라미터 공간에서 놀라울 정도로 단순하고 예측 가능한 rank-1 경로를 따른다는 기하학적 사실을 규명했습니다. RELEX는 학습 비용을 획기적으로 절감하면서도 강력한 성능을 보장하는 학습 불필요 방법론으로서, 대규모 모델의 추론 강화 학습 효율성을 극대화할 수 있는 강력한 도구를 제공합니다. 이 연구는 강화학습의 학습 역학을 모델링하는 새로운 방향을 제시하며, 향후 LLM 정렬(Alignment) 연구에서 컴퓨팅 자원 효율성을 개선하는 핵심적인 기여가 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Efficient RLVR Training via Weighted Mutual Information Data Selection
- [논문리뷰] Spurious Rewards Paradox: Mechanistically Understanding How RLVR Activates Memorization Shortcuts in LLMs
- [논문리뷰] JudgeRLVR: Judge First, Generate Second for Efficient Reasoning
- [논문리뷰] Shorter but not Worse: Frugal Reasoning via Easy Samples as Length Regularizers in Math RLVR
- [논문리뷰] Reasoning with Sampling: Your Base Model is Smarter Than You Think
Review 의 다른글
- 이전글 [논문리뷰] Video2GUI: Synthesizing Large-Scale Interaction Trajectories for Generalized GUI Agent Pretraining
- 현재글 : [논문리뷰] You Only Need Minimal RLVR Training: Extrapolating LLMs via Rank-1 Trajectories
- 다음글 [논문리뷰] iTryOn: Mastering Interactive Video Virtual Try-On with Spatial-Semantic Guidance
댓글