[논문리뷰] iTryOn: Mastering Interactive Video Virtual Try-On with Spatial-Semantic Guidance
링크: 논문 PDF로 바로 열기
저자: Jun Zheng, Zhengze Xu, Mengting Chen, Jing Wang, Jinsong Lan, Xiaoyong Zhu, Kaifu Zhang, Bo Zheng, Xiaodan Liang
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Interactive VVT: 사용자가 옷을 당기거나 지퍼를 올리는 등 의류와 능동적으로 상호작용하는 상황을 포함하는 새로운 비디오 가상 피팅 작업입니다.
- A-RoPE (Action-aware Rotational Position Embedding): 시간 정보를 포함하는 포즈 궤적 내에서 대화형 세그먼트와 비대화형 세그먼트를 구분하고, 텍스트 가이드가 특정 비디오 프레임에 정확히 동기화되도록 제어하는 임베딩 방식입니다.
- VVT-Interact: 능동적 인간-의류 상호작용을 연구하기 위해 구축된 최초의 대규모 데이터셋으로, 5,292개의 비디오-의류 쌍을 포함합니다.
- ISR (Interaction Success Rate): VLM을 활용하여 생성된 비디오에서 의도한 동작(예: 지퍼 올리기)이 물리적으로 정확하고 의미 있게 수행되었는지 평가하는 새로운 지표입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존의 비디오 가상 피팅(VVT) 연구는 주로 피동적인 피사체나 단순한 움직임만을 다루어, 실제 이커머스 라이브 스트리밍 등에서 발생하는 인간-의류 간의 복잡한 상호작용을 포착하지 못한다는 한계가 있습니다. 기존의 2D pose 정보는 depth나 손의 정밀한 형태를 복원하기 어려워 동작의 의미적 모호성(Interaction Ambiguity)을 유발합니다. 또한, 대화형 이벤트는 비디오 내에서 드물고 짧게 발생하므로 일반적인 학습 방식으로는 모델이 복잡한 물리적 변형을 학습하기 어렵습니다. 저자들은 이러한 한계를 극복하기 위해 [Figure 2]와 같이 공간적/의미적 가이드를 제공하는 새로운 프레임워크를 제안합니다.
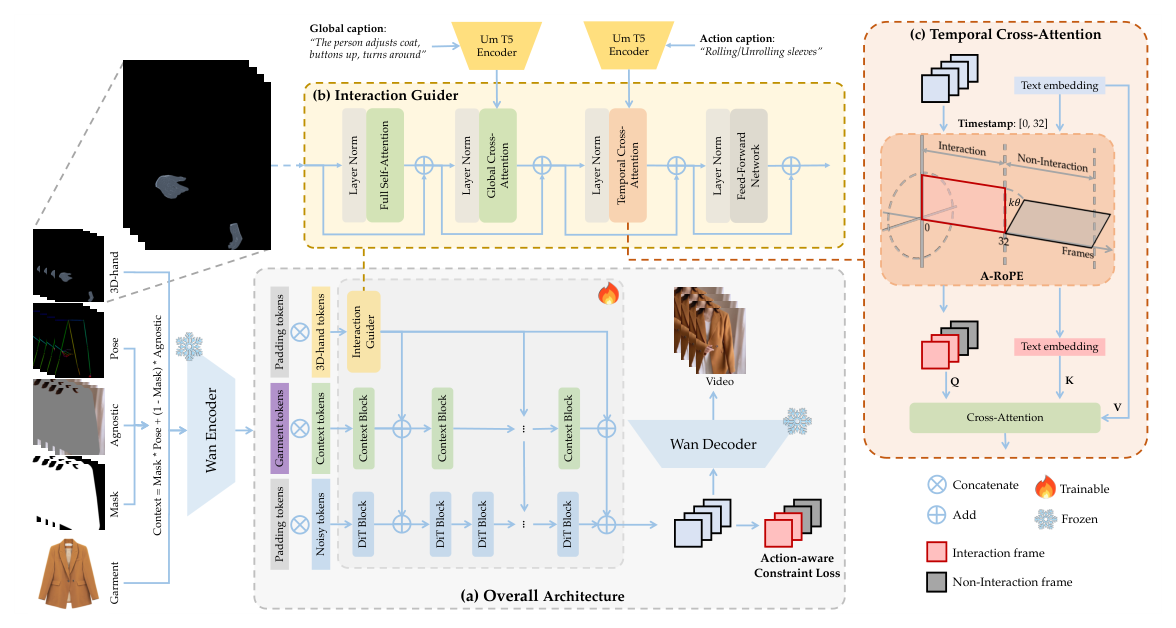
Figure 2 — 프레임워크의 전체 구조 및 모듈 구성을 설명하는 핵심 다이어그램
## 3. Method & Key Results (제안 방법론 및 핵심 결과)
iTryOn은 Diffusion Transformer (DiT) 백본을 기반으로 하며, 능동적 상호작용을 완벽하게 재현하기 위해 다단계 상호작용 주입 메커니즘과 타겟팅된 제어 손실 함수를 도입합니다. 공간 수준에서는 HaMeR를 통해 추출한 garment-agnostic 3D hand prior를 활용하여 미세한 손과 옷 사이의 접촉을 가이드하고, 의미 수준에서는 A-RoPE를 사용하여 글로벌 컨텍스트와 시간별 액션 캡션을 동기화합니다. 또한, 대화형 프레임에 학습을 집중시키는 action-aware constraint loss를 통해 Sparse한 학습 신호 문제를 해결하였습니다. 실험 결과, [Table 2]에서 볼 수 있듯이 iTryOn은 기존 방식 대비 ISR 지표에서 61% 이상의 높은 성공률을 기록하며 압도적인 성능을 보였습니다. 또한, VFID 및 FVD 지표에서도 가장 낮은 수치를 기록하며 시각적 충실도와 시간적 일관성 측면에서 우월한 성능을 입증하였습니다.

Table 2 — 상호작용 정확도 및 Fidelity 성능을 보여주는 정량적 비교 테이블
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 Interactive VVT라는 새로운 과제를 공식화하고, 이를 해결하기 위한 공간-의미론적 가이드 프레임워크인 iTryOn을 성공적으로 제시하였습니다. 제안된 방법론은 복잡한 인간-의류 상호작용을 정밀하게 제어할 수 있음을 입증하였으며, 새롭게 구축된 데이터셋과 ISR 지표는 향후 해당 분야의 표준 벤치마크 역할을 할 것입니다. 이 연구는 고도화된 이커머스 시각 콘텐츠 생성 기술의 비약적인 발전을 촉진하며, 더욱 역동적이고 실감 나는 가상 피팅 경험을 가능하게 할 것으로 기대됩니다.

Table 1 — 제안 모델의 시각적 충실도 성능을 보여주는 정량적 비교 테이블
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Qwen-Music Technical Report
- [논문리뷰] Boogu-Image-0.1: Boosting Open-Source Unified Multimodal Understanding and Generation
- [논문리뷰] Motion4Motion: Motion Transfer Across Subjects at Inference
- [논문리뷰] CtrlVTON: Controllable Virtual Try-On via Visual-Instance-Prompt Segmentation
- [논문리뷰] Scaling Mixture-of-Experts Video Pretraining for Embodied Intelligence
Review 의 다른글
- 이전글 [논문리뷰] You Only Need Minimal RLVR Training: Extrapolating LLMs via Rank-1 Trajectories
- 현재글 : [논문리뷰] iTryOn: Mastering Interactive Video Virtual Try-On with Spatial-Semantic Guidance
- 다음글 [논문리뷰] ACC: Compiling Agent Trajectories for Long-Context Training
댓글