[논문리뷰] RewardHarness: Self-Evolving Agentic Post-Training
링크: 논문 PDF로 바로 열기
저자: Yuxuan Zhang, Penghui Du, Bo Li, Cong Wei, Junwen Miao, Huaisong Zhang, Songcheng Cai, Yubo Wang, Dongfu Jiang, Yuyu Zhang, Ping Nie, Wenhu Chen, Changqian Yu, Kelsey R. Allen
1. Key Terms & Definitions (핵심 용어 및 정의)
- Orchestrator: 인간의 피드백 데모를 분석하고, 평가를 위한 Skills와 Tools 라이브러리를 설계/수정하며, 적절한 평가 컨텍스트를 구성하는 관리자 LLM입니다.
- Skills & Tools Library: 평가를 위한 구조적 가이드라인(Skills)과 목표 지향적 시각 분석 프로토콜(Tools)을 포함하는 버전화된 지식 저장소입니다.
- Sub-Agent: 라이브러리에서 제공받은 Skills와 Tools를 사용하여, 소스 이미지와 편집 결과 간의 선호도를 판단하는 Frozen VLM입니다.
- Self-Evolution Loop: 약 100개의 피드백 데모를 활용하여 평가 성공 및 실패 사례를 분석하고, 별도의 파라미터 업데이트 없이 외부 라이브러리를 개선하는 자동 최적화 공정입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 Reward Modeling 방식이 대규모 인간 피드백 데이터에 의존하여 비용이 높고, 유연성이 부족하다는 문제점을 해결하고자 합니다. 대다수 연구들은 수십만 개의 비교 데이터로 Reward Model을 학습시키지만, 인간은 소수의 예시만으로도 평가 기준을 파악할 수 있다는 점에서 큰 데이터 효율성 격차가 존재합니다. 또한 기존의 고정된 보상 체계는 폐쇄형 모델이나 API 기반 모델에 적용하기 어렵고 해석 가능성이 낮습니다. 저자들은 파라미터 최적화 대신, 상황에 맞는 외부 지식 라이브러리를 진화시키는 RewardHarness 프레임워크를 제안합니다 [Figure 1].
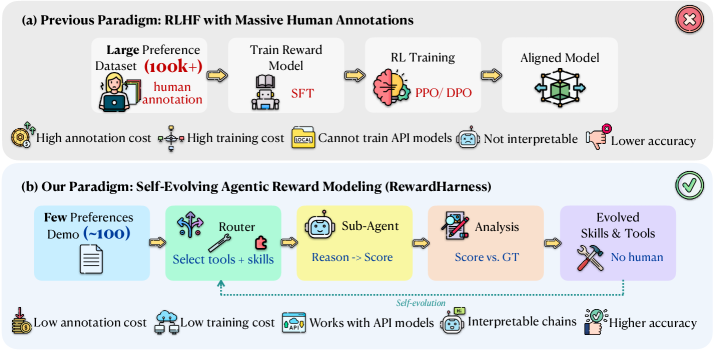
Figure 1 — 기존 패러다임과 RewardHarness 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
RewardHarness는 평가 능력을 모델 파라미터 내부에 저장하지 않고, Skills와 Tools라는 외부 라이브러리로 분리하여 컨텍스트 내에서 실행하는 에이전트 기반 프레임워크입니다 [Figure 2]. Orchestrator는 각 작업에 최적화된 Skills와 Tools를 검색하여 Sub-Agent에게 제공하며, 이는 구조화된 추론 체인을 통해 선호도 판단을 수행합니다 [Figure 3]. Self-Evolution Loop를 통해 평가 오류를 분석하고 라이브러리를 지속적으로 보정함으로써, 최소한의 인간 개입으로 평가 성능을 극대화합니다.
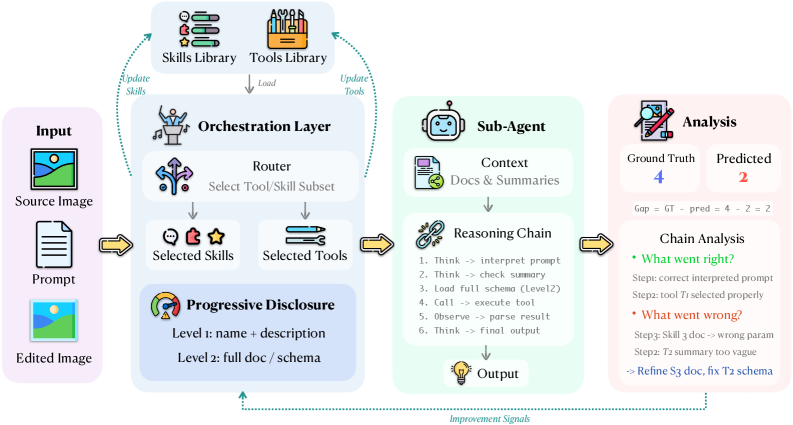
Figure 2 — RewardHarness 파이프라인 개요
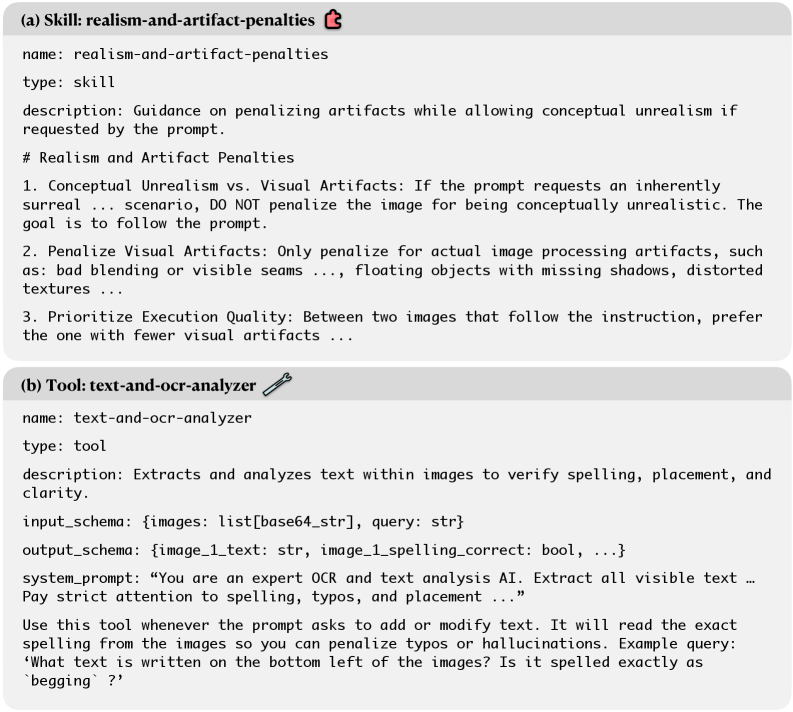
Figure 3 — Skills 및 Tools 라이브러리 예시
실험 결과, RewardHarness는 EditReward-Bench와 GenAI-Bench에서 평균 47.4%의 정확도를 기록하며 GPT-5의 42.1%를 상회하는 성능을 보였습니다 [Table 1]. 특히, 전체 데이터의 0.05% 수준인 100개의 샘플만으로도 강력한 평가 성능을 달성했습니다. 또한, GRPO 미세 조정의 보상 신호로 활용되었을 때, ImgEdit-Bench에서 3.52의 점수를 기록하며 기존 EditReward 모델(3.45)보다 우수한 정량적 성과를 나타냈습니다 [Table 2]. 이는 제안 방법론이 데이터 효율성과 성능 측면에서 기존 방식 대비 비교 우위에 있음을 입증합니다 [Figure 5].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Reward Modeling을 파라미터 최적화가 아닌 명시적 컨텍스트 진화 과정으로 재정의함으로써 데이터 효율적인 평가 시스템을 구축했습니다. 제안된 프레임워크는 대규모 모델 학습 없이도 고도의 추론 성능을 보여주며, 특히 블랙박스 모델의 평가나 해석 가능한 보상 시스템 구현에 중요한 이정표를 제시합니다. 본 연구의 성과는 향후 비전-언어 모델의 에이전트형 평가 체계를 확장하고, 효율적인 인간-AI 정렬을 실현하는 데 큰 학술적·산업적 기여를 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] RLAnything: Forge Environment, Policy, and Reward Model in Completely Dynamic RL System
- [논문리뷰] SSRL: Self-Search Reinforcement Learning
- [논문리뷰] The Hitchhiker's Guide to Agentic AI: From Foundations to Systems
- [논문리뷰] Skill-RM: Unifying Heterogeneous Evaluation Criteria via Agent Skill
- [논문리뷰] Socratic-SWE: Self-Evolving Coding Agents via Trace-Derived Agent Skills
Review 의 다른글
- 이전글 [논문리뷰] Realiz3D: 3D Generation Made Photorealistic via Domain-Aware Learning
- 현재글 : [논문리뷰] RewardHarness: Self-Evolving Agentic Post-Training
- 다음글 [논문리뷰] RouteProfile: Elucidating the Design Space of LLM Profiles for Routing
댓글