[논문리뷰] LongCat-Flash-Prover: Advancing Native Formal Reasoning via Agentic Tool-Integrated Reinforcement Learning
링크: 논문 PDF로 바로 열기
저자: Jianing Wang, Jianfei Zhang, Qi Guo, Linsen Guo, Rumei Li, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Native Formal Reasoning : Large Language Models (LLMs)의 핵심 역량으로, Lean4 와 같은 formal operators를 활용하여 복잡한 추론 작업을 해결하는 패러다임이다. 이는 native multimodal이나 native tool calls와 유사하게 모델이 formal operators를 직접 활용하도록 한다.
- Auto-formalization (AF) : 자연어로 주어진 informal statement를 Lean4 의 verified formal statement로 변환하는 작업이다. 이 과정에서 모델은 구문적으로 부정확하거나 의미론적으로 일관되지 않은 formal statement를 생성할 수 있다.
- Sketching : 주어진 formal statement에 기반하여 Lean4 로 lemma-style sketch를 생성하는 작업이다. 이는 Divide and Conquer 및 Dynamic Programming 전략에서 영감을 받아, unproved helper lemmas를 통해 전체 증명을 더 쉽게 접근할 수 있도록 분해한다.
- Proving : Lean4 에서 valid proof를 생성하는 작업으로, 입력 형식에 따라 Whole-Proof Generation 과 Sketch-Proof Generation 의 두 가지 스키마로 정의된다. 이는 proof의 유효성을 검증하는 도구와 함께 사용된다.
- Hierarchical Importance Sampling Policy Optimization (HisPO) : Mixture-of-Experts (MoE) 모델의 agentic Reinforcement Learning (RL) 훈련 안정화를 목표로 하는 알고리즘이다. 이는 sequence 및 token level에서 policy staleness와 train-inference engine discrepancies를 고려하는 gradient masking strategy를 사용하여 최적화 불안정성 위험을 완화한다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 Large Language Models (LLMs)의 추론 능력 향상에도 불구하고, 현재 LLMs는 Lean4 와 같이 엄격하고 검증된 formal language를 요구하는 formal theorem-proving task에서 여전히 어려움을 겪고 있다. 이러한 task들은 신뢰할 수 있는 formal statements 및 proofs를 보장하기 위해 정밀한 논리적 진행이 필수적이다. 기존 연구들은 verification tools의 피드백을 활용하여 Lean4 코드 스니펫을 수정하는 모델을 훈련시키는 데 집중했지만, Lean4 의 엄격한 특성 때문에 vanilla Tool-Integrated Reasoning (TIR) 을 이러한 formal verification task에 직접 적용하는 것은 여전히 중대한 도전 과제로 남아 있다. 따라서, 저자들은 Lean4 환경에서 native formal reasoning 을 발전시키기 위해 agentic tool-integrated reasoning을 통해 새로운 state-of-the-art 성능을 달성하는 효율적인 open-source Mixture-of-Experts (MoE) 모델을 개발하는 것을 목표로 한다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
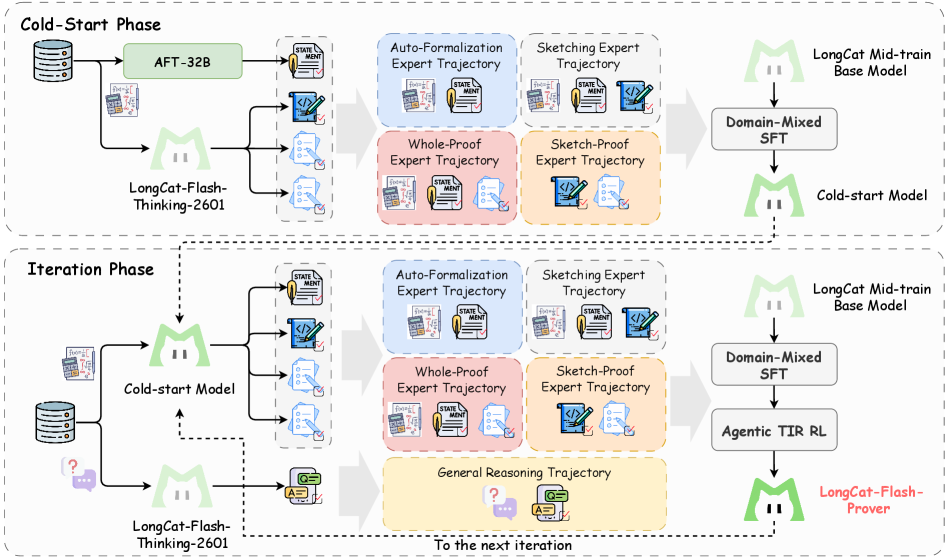
저자들은 LongCat-Flash-Prover 를 제안하며, 이는 560-billion-parameter의 open-source Mixture-of-Experts (MoE) 모델로 Native Formal Reasoning 을 발전시킨다. 이 모델은 native formal reasoning task를 auto-formalization , sketching , proving 의 세 가지 독립적인 formal capability로 분해한다. 이러한 capability를 촉진하기 위해, 저자들은 고품질 task trajectories를 확장하기 위한 Hybrid-Experts Iteration Framework 를 제안한다. 이 프레임워크는 여러 최적화된 expert models를 사용하여 native formal operators에 중점을 둔 일련의 trajectories를 합성하고, 여러 verifiable formal tools를 환경 피드백으로 활용하여 각 expert를 반복적으로 정제한다
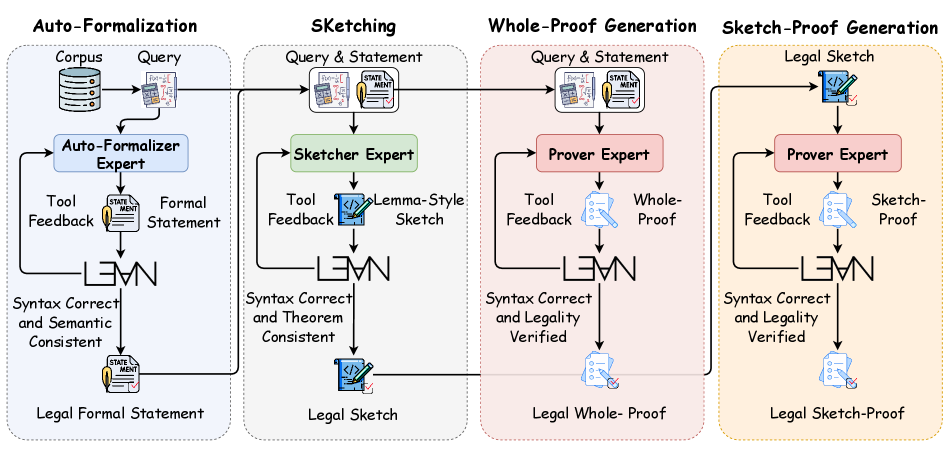
Agentic Reinforcement Learning (RL) 과정에서는 Hierarchical Importance Sampling Policy Optimization (HisPO) 알고리즘을 도입하여 long-horizon task에 대한 MoE 모델 훈련을 안정화한다. 이는 policy staleness와 train-inference engine discrepancies를 sequence 및 token level에서 고려하는 gradient masking strategy를 포함한다. 또한, reward hacking 문제를 제거하기 위해 theorem consistency 및 legality detection mechanisms을 통합한다.
광범위한 실험 결과, LongCat-Flash-Prover 는 auto-formalization 및 theorem proving 모두에서 open-weights 모델 중 새로운 state-of-the-art 를 달성했다. auto-formalization task에서는 MiniF2F-Test 에서 TIR 기반 향상으로 100% 의 점수를 달성했으며, theorem proving task에서는 MiniF2F-Test 에서 72 inference budget당 97.1% 의 Pass Rate를 기록하며 뛰어난 sample efficiency를 보였다 [Figure 1, Table 3]. 또한, MathOlympiad-Bench와 PutnamBench에서 Pass@32 Metric 기준으로 각각 25.5% 와 20.3% 의 상당한 성능 향상을 보였다
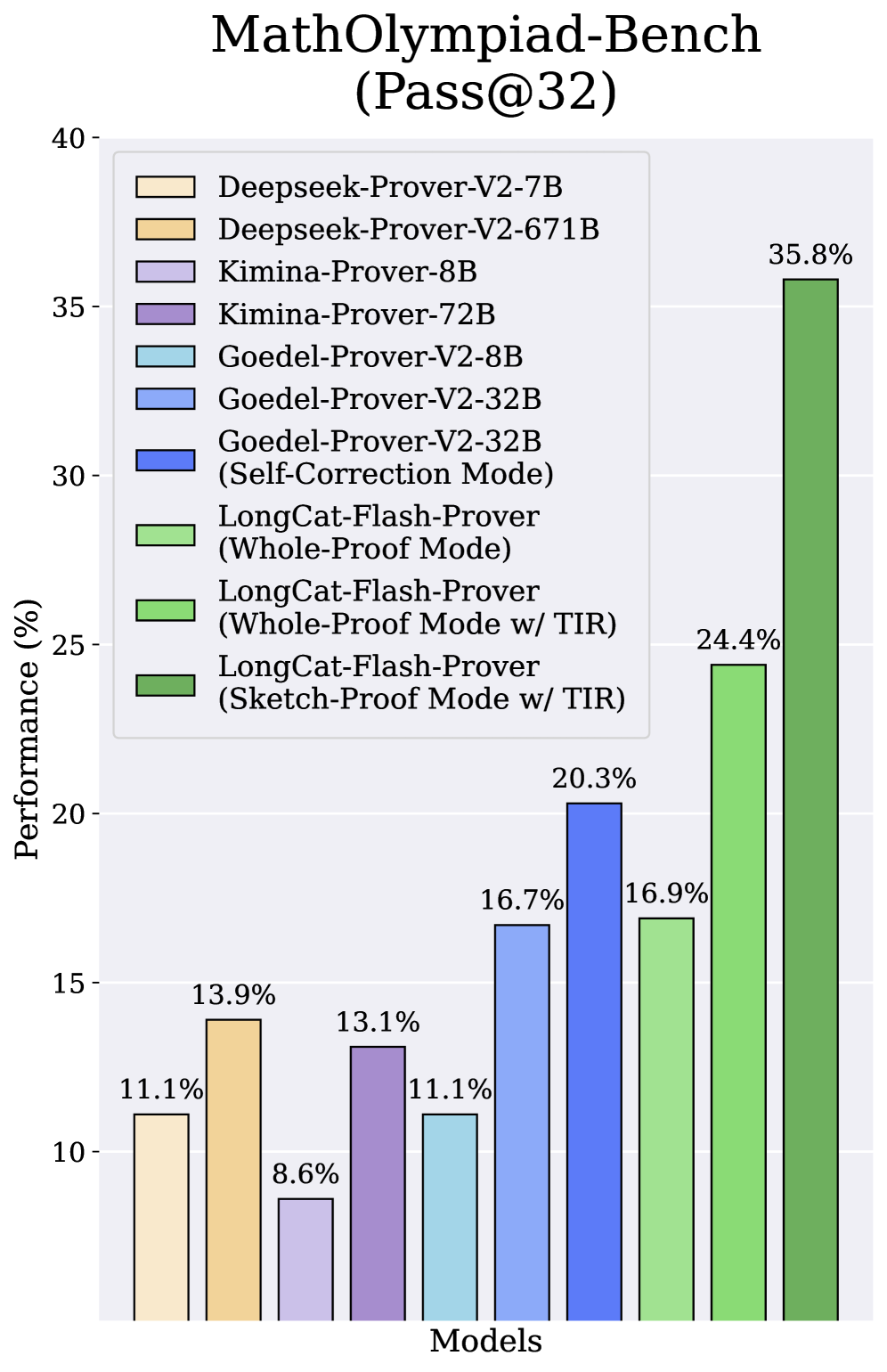
특히, sketch-proof mode w/ TIR & Tree Search 는 MiniF2F-Test 에서 72 attempts로 97.1% 를, ProverBench 에서 220 attempts로 70.8% 를 달성하며 기존 open-source prover 모델들을 크게 능가했다 [Table 3].
4. Conclusion & Impact (결론 및 시사점)
이 연구는 native formal reasoning 과 general reasoning 능력을 융합한 560-billion-parameter Mixture-of-Experts (MoE) 모델인 LongCat-Flash-Prover 를 성공적으로 도입했다. 이 모델은 여러 auto-formalization 및 theorem-proving task에서 검증된 도구를 활용하여 open-source 모델 중 state-of-the-art 성능을 달성했다. LongCat-Flash-Prover 의 핵심 혁신은 다수의 검증된 도구를 사용하여 고품질 synthesized trajectories를 효과적으로 구축하는 hybrid-experts iteration framework 와 MoE 모델 기반 RL 훈련을 안정화하는 Hierarchical Importance Sampling Policy Optimization (HisPO) 방법론이다. 추가적으로, theorem proving의 신뢰성을 보장하기 위해 legality detection 메커니즘을 탐색했다. 이 연구의 open-sourcing은 고품질 데이터 전략, 효율적인 RL 훈련, 그리고 native agentic reasoning 영역에서 informal 및 formal reasoning 연구 발전에 중요한 영향을 미칠 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Scaling Mixture-of-Experts Video Pretraining for Embodied Intelligence
- [논문리뷰] Gemma 4 Technical Report
- [논문리뷰] ELDR: Expert-Locality-Aware Decode Routing for PD-Disaggregated MoE Serving
- [논문리뷰] Scaling the Horizon, Not the Parameters: Reaching Trillion-Parameter Performance with a 35B Agent
- [논문리뷰] Focusing on What Matters: Saliency-Harnessing Accurate Routing for Diffusion MoE
Review 의 다른글
- 이전글 [논문리뷰] Insight-V++: Towards Advanced Long-Chain Visual Reasoning with Multimodal Large Language Models
- 현재글 : [논문리뷰] LongCat-Flash-Prover: Advancing Native Formal Reasoning via Agentic Tool-Integrated Reinforcement Learning
- 다음글 [논문리뷰] Look Where It Matters: High-Resolution Crops Retrieval for Efficient VLMs
댓글