[논문리뷰] Look Where It Matters: High-Resolution Crops Retrieval for Efficient VLMs
링크: 논문 PDF로 바로 열기
The browsing result contains the full HTML content of the paper. I can now extract the required information.
Metadata Extraction:
-
Authors: Ehud Rivlin, Sivan Haray, Artem Spector, Moshe Kimhi, Nimrod Shabtay, Chaim Baskin, Raja Giryes, Eli Schwartz. The request asks for "제1저자, 제2저자, et al.". Looking at the provided metadata in the user query, it already lists "Ehud Rivlin, Sivan Haray, Artem Spector, Moshe Kimhi, Nimrod Shabtay". The paper itself lists "Nimrod Shabtay", "Moshe Kimhi", "Artem Spector", "Sivan Haray", "Ehud Rivlin", "Chaim Baskin", "Raja Giryes", "Eli Schwartz". I should follow the instruction to use the provided metadata from the user for the top 5 authors.
-
Keywords: I'll extract 5-8 keywords from the abstract and introduction.
Vision-language models (VLMs)High-resolution cropsTool-callingEfficiencyReinforcement Learning(GRPO)Multi-turn interactionData curationSpatial-on-demand
Part 1: Summary
## 1. Key Terms & Definitions
- VLMs (Vision-language models) : 이미지와 텍스트를 함께 처리하여 질의응답, 캡셔닝 등 멀티모달 태스크를 수행하는 모델.
- High-Resolution Crops : 이미지 전체를 고해상도로 처리하는 대신, VLM의 쿼리에 필요한 특정 공간 영역만을 고해상도로 잘라낸(crop) 부분 이미지.
- Tool-calling : VLM이 외부 도구(여기서는 고해상도 이미지 크롭을 요청하는 도구)를 호출하여 특정 작업을 수행하고 그 결과를 모델의 컨텍스트에 통합하는 메커니즘.
- Coupled-Decision Policy (CDP) : AwaRes 프레임워크 내에서 VLM이 추가 해상도가 필요한지(when to crop)와 어떤 영역을 가져와야 하는지(where to crop)를 동시에 결정하는 정책.
- Retain Token Ratio (RTR) : 전체 해상도 이미지 처리 시 사용되는 시각 토큰 수 대비 실제 처리된 시각 토큰의 비율로, 모델의 효율성을 나타내는 지표.
## 2. Motivation & Problem Statement 기존 VLM들은 detail-sensitive tasks 를 해결하기 위해 high-resolution visual inputs 에 의존하지만, 이로 인해 computational costs 와 inference latency 가 크게 증가하는 문제가 발생한다. 특히, visual tokens 의 수가 해상도에 비례하여 빠르게 늘어나 inference bottleneck 이 된다. 기존 접근 방식에는 token pruning 과 resolution escalation 이 있다. Token pruning 은 불규칙한 token patterns 와 동적인 sequence lengths 를 유발하여 end-to-end serving speedups 를 달성하기 어렵고, resolution escalation 은 추가 세부 정보가 필요할 때 전체 high-resolution image 를 검색하여 불필요한 영역에 computation 을 낭비하는 한계가 있다. 저자들은 high fidelity 에 대한 요구가 종종 spatially sparse 하다는 핵심 관찰을 통해, where to look 이 whether to look 만큼 중요하다고 주장하며 이 문제를 해결하고자 한다.
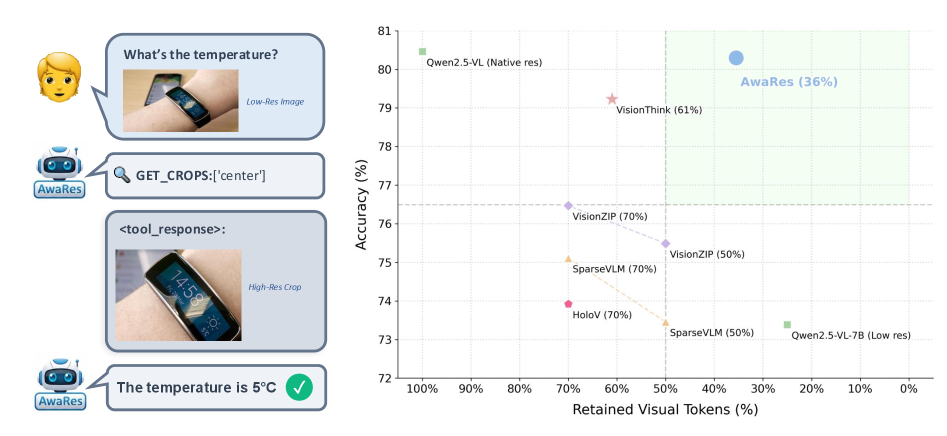
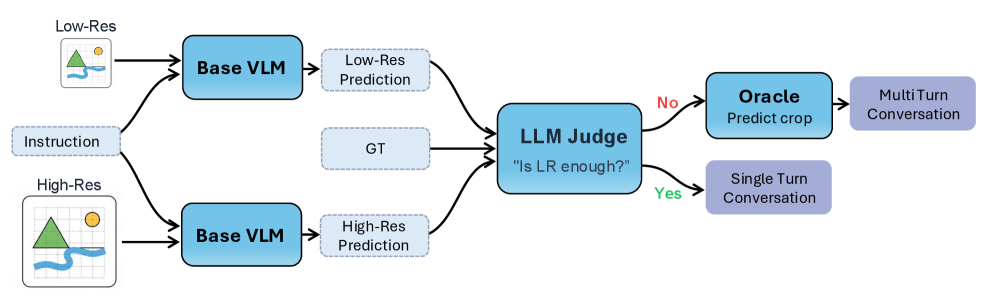
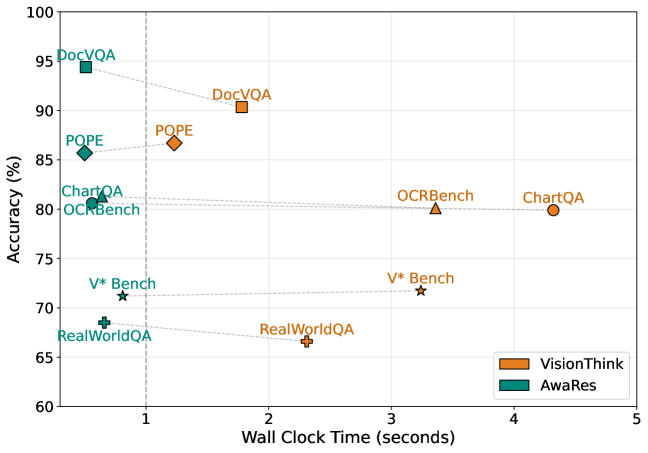
## 3. Method & Key Results 저자들은 spatial-on-demand 방식을 통해 efficiency 를 높이는 VLM 프레임워크인 AwaRes 를 제안한다. AwaRes 는 기본적으로 low-resolution global view 를 처리하고, 추가적인 세부 정보가 필요할 경우 tool-calling 을 사용하여 특정 high-resolution sub-regions (crops) 만을 요청한다 [cite: 1, Figure 1]. 이러한 multi-turn structure 는 KV-caching 과 자연스럽게 호환되어 실제 배포에 유리하다. AwaRes 는 (i) 추가 해상도가 필요한지( whether )와 (ii) 어디에서 얻어야 하는지( where )를 동시에 결정하는 coupled-decision policy (CDP) 를 학습한다. 이 학습을 위해 저자들은 수동적인 spatial annotations 없이 automatic data curation pipeline 을 구축했다 [cite: 1, Figure 2]. 이 파이프라인은 LLM as a Judge (LaaJ) 를 사용하여 low-resolution 이 불충분한 예시를 식별하고, oracle grounding model 을 사용하여 정답에 필요한 시각적 증거를 localize 하여 target crops 를 생성한다 [cite: 1, Figure 2]. 학습은 두 단계로 이루어진다: (i) cold-start Supervised Fine-Tuning (SFT) 단계는 모델에게 tool-calling protocol 을 가르치고 reference policy πref\pi_{\text{ref}}를 생성하며, (ii) Multi-turn Group Relative Policy Optimization (GRPO) 단계는 πref\pi_{\text{ref}}에서 초기화되어 KL penalty 로 정규화되고 accuracy–efficiency trade-off 를 명시적으로 최적화한다. GRPO 의 reward function 은 semantic answer correctness 와 명시적인 crop-cost penalties 를 결합하여 불필요한 crop acquisition 을 줄이면서 필요한 경우 crop requests 를 놓치지 않도록 유도한다. 실험 결과, AwaRes 는 6가지 벤치마크에서 full-resolution baseline (Qwen2.5-VL-7B) 과 거의 동등한 평균 Accuracy (80.30% vs. 80.46%)를 달성하면서도 평균 visual tokens 의 36% 만을 사용하여 inference cost 를 크게 절감했다 [cite: 1, Table 1]. 특히 ChartQA , DocVQA , OCRBench 에서는 full-resolution baselines 보다 약간 높은 Accuracy 를 보였다 [cite: 1, Table 1]. 또한, end-to-end latency 측면에서 AwaRes 는 VisionThink 대비 평균 4.4배 빠른 0.61초 의 latency 를 달성했다 [cite: 1, Figure 4, Table 5]. 이는 VisionThink 의 긴 reasoning traces 와 달리 AwaRes 가 짧고 구조화된 tool call 을 통해 결정을 내리고 KV cache 를 재사용하기 때문이다. SFT 단계에서는 tool-calling protocol 학습으로 인해 over-invoking 경향이 있었으나, GRPO 단계에서 tool-use cost 를 통해 LR 결정이 72.2% 로 증가하고 “All” (full-image crop) 사용이 4.9% 로 감소하는 등 selective tool use 로 전환되었다 [cite: 1, Figure 5].
## 4. Conclusion & Impact 본 논문은 spatial-on-demand 추론 프레임워크 AwaRes 를 제시하며, 이는 low-resolution global view 를 유지하면서 쿼리에 필요한 high-resolution crops 만을 선택적으로 검색하는 tool-calling interface 를 활용한다. 이 설계는 high-resolution VLM inference 의 실제적인 병목 현상을 해결하고, multi-turn KV-cache reuse 를 통해 배포 친화적이다. AwaRes 는 automatic data curation pipeline 을 통해 LLM judge 와 oracle grounding model 을 사용하여 수동 spatial supervision 없이 crop-request trajectories 를 생성한다. 이후 cold-start SFT 와 multi-turn GRPO 를 통해 accuracy–efficiency trade-off 를 최적화한다. 이 연구는 document understanding 및 general visual QA 를 포함한 6가지 벤치마크에서 full-resolution performance 와 거의 동등한 결과를 달성하면서도 visual tokens 사용량을 크게 줄여 end-to-end efficiency 를 향상시켰다. AwaRes 는 tight compute 및 latency budgets 하에서 high-detail multimodal reasoning 을 위한 실용적인 경로를 제공하며, 필요에 따라 점진적으로 해상도를 할당하는 더 풍부한 multi-step perception strategies 의 가능성을 열었다는 점에서 학계 및 산업계에 큰 시사점을 준다. 향후 연구는 discrete crop set 에서 continuous bounding box predictions 로 crop selection 을 확장하고, temporal sparsity 를 활용하여 video understanding 에 spatial-on-demand perception 을 일반화하는 방향으로 진행될 수 있다.
Part 2: Figure Information
I will select Figure 1 (AwaRes overview), Figure 2 (automatic supervision pipeline), and Figure 4 (Performance vs. Wall Clock Time). Figure 5 is also very good for showing the GRPO effect but the limit is 3 figures. Figure 1 and 2 are architecture/framework, and Figure 4 shows key quantitative results.
I need to get the exact image_url for these figures.
- Figure 1:
->https://arxiv.org/html/2603.16932v1/x1.png - Figure 2:
->https://arxiv.org/html/2603.16932v1/x2.png - Figure 4:
->https://arxiv.org/html/2603.16932v1/x5.png저자: Ehud Rivlin, Sivan Haray, Artem Spector, Moshe Kimhi, Nimrod Shabtay, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- VLMs (Vision-language models) : 이미지와 텍스트를 함께 처리하여 질의응답, 캡셔닝 등 멀티모달 태스크를 수행하는 모델.
- High-Resolution Crops : 이미지 전체를 고해상도로 처리하는 대신, VLM의 쿼리에 필요한 특정 공간 영역만을 고해상도로 잘라낸(crop) 부분 이미지.
- Tool-calling : VLM이 외부 도구(여기서는 고해상도 이미지 크롭을 요청하는 도구)를 호출하여 특정 작업을 수행하고 그 결과를 모델의 컨텍스트에 통합하는 메커니즘.
- Coupled-Decision Policy (CDP) : AwaRes 프레임워크 내에서 VLM이 추가 해상도가 필요한지(when to crop)와 어떤 영역을 가져와야 하는지(where to crop)를 동시에 결정하는 정책.
- Retain Token Ratio (RTR) : 전체 해상도 이미지 처리 시 사용되는 시각 토큰 수 대비 실제 처리된 시각 토큰의 비율로, 모델의 효율성을 나타내는 지표.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존 Vision-language models (VLMs) 은 detail-sensitive tasks 를 해결하기 위해 high-resolution visual inputs 에 의존하지만, 이로 인해 computational costs 와 inference latency 가 크게 증가하는 문제가 발생한다. 특히, visual tokens 의 수가 이미지 해상도에 비례하여 빠르게 늘어나 high-resolution inference 가 주요 bottleneck 이 된다. 기존의 효율성 개선 접근 방식으로는 token pruning 과 resolution escalation 이 있다. Token pruning 방법은 불규칙한 token patterns 와 동적인 sequence lengths 를 유발하여 end-to-end serving speedups 를 달성하기 어렵고, resolution escalation 방법은 추가 세부 정보가 필요할 때 전체 high-resolution image 를 검색하여 쿼리와 관련 없는 영역에 불필요한 computation 을 낭비하는 한계가 있다. 저자들은 high fidelity 에 대한 요구가 종종 spatially sparse 하다는 핵심 관찰을 통해, where to look 이 whether to look 만큼 중요하다고 주장하며, 이 문제를 해결하고자 본 연구를 수행하였다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 spatial-on-demand 방식으로 efficiency 를 높이는 VLM 프레임워크인 AwaRes 를 제안한다. AwaRes 는 기본적으로 low-resolution global view 를 처리하고, 추가적인 세부 정보가 필요할 경우 tool-calling 을 사용하여 특정 high-resolution sub-regions (crops) 만을 요청한다 [cite: 1, Figure 1]. 이러한 multi-turn structure 는 KV-caching 과 자연스럽게 호환되어 실제 배포에 유리하다. AwaRes 는 (i) 추가 해상도가 필요한지( whether )와 (ii) 어디에서 얻어야 하는지( where )를 동시에 결정하는 coupled-decision policy (CDP) 를 학습한다. 이 학습을 위해 저자들은 수동적인 spatial annotations 없이 automatic data curation pipeline 을 구축했다 [cite: 1, Figure 2]. 이 파이프라인은 LLM as a Judge (LaaJ) 를 사용하여 low-resolution 이 불충분한 예시를 식별하고, oracle grounding model 을 사용하여 정답에 필요한 시각적 증거를 localize 하여 target crops 를 생성한다 [cite: 1, Figure 2]. 학습은 두 단계로 이루어진다: 첫째, cold-start Supervised Fine-Tuning (SFT) 단계는 모델에게 tool-calling protocol 을 가르치고 강력한 supervised reference policy πref\pi_{\text{ref}}를 생성한다. 둘째, Multi-turn Group Relative Policy Optimization (GRPO) 단계는 πref\pi_{\text{ref}}에서 초기화되어 KL penalty 로 정규화되고 accuracy–efficiency trade-off 를 명시적으로 최적화한다. GRPO 의 reward function 은 semantic answer correctness 와 명시적인 crop-cost penalties 를 결합하여 불필요한 crop acquisition 을 줄이면서 필요한 경우 crop requests 를 놓치지 않도록 유도한다. 실험 결과, AwaRes 는 6가지 벤치마크에서 full-resolution baseline (Qwen2.5-VL-7B) 과 거의 동등한 평균 Accuracy ( 80.30% vs. 80.46% )를 달성하면서도 평균 visual tokens 의 36% 만을 사용하여 inference cost 를 크게 절감했다 [cite: 1, Table 1]. 특히 ChartQA , DocVQA , OCRBench 에서는 full-resolution baselines 보다 약간 높은 Accuracy 를 보였다 [cite: 1, Table 1]. 또한, end-to-end latency 측면에서 AwaRes 는 VisionThink 대비 평균 4.4배 빠른 0.61초 의 latency 를 달성했다 [cite: 1, Figure 4, Table 5]. 이는 VisionThink 의 긴 reasoning traces 와 달리 AwaRes 가 짧고 구조화된 tool call 을 통해 결정을 내리고 KV cache 를 재사용하기 때문이다. SFT 단계에서는 tool-calling protocol 학습으로 인해 over-invoking 경향이 있었으나, GRPO 단계에서 tool-use cost 를 통해 LR 결정이 72.2% 로 증가하고 “All” (full-image crop) 사용이 4.9% 로 감소하는 등 selective tool use 로 전환되었다 [cite: 1, Figure 5].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 spatial-on-demand 추론 프레임워크 AwaRes 를 제시하며, 이는 low-resolution global view 를 유지하면서 쿼리에 필요한 high-resolution crops 만을 선택적으로 검색하는 tool-calling interface 를 활용한다. 이 설계는 high-resolution VLM inference 의 실제적인 병목 현상을 해결하고, multi-turn KV-cache reuse 를 통해 배포 친화적이다. AwaRes 는 automatic data curation pipeline 을 통해 LLM judge 와 oracle grounding model 을 사용하여 수동 spatial supervision 없이 crop-request trajectories 를 생성한다. 이후 cold-start SFT 와 multi-turn GRPO 를 통해 accuracy–efficiency trade-off 를 최적화한다. 이 연구는 document understanding 및 general visual QA 를 포함한 6가지 벤치마크에서 full-resolution performance 와 거의 동등한 결과를 달성하면서도 visual tokens 사용량을 크게 줄여 end-to-end efficiency 를 향상시켰다. AwaRes 는 tight compute 및 latency budgets 하에서 high-detail multimodal reasoning 을 위한 실용적인 경로를 제공하며, 필요에 따라 점진적으로 해상도를 할당하는 더 풍부한 multi-step perception strategies 의 가능성을 열었다는 점에서 학계 및 산업계에 큰 시사점을 준다. 향후 연구는 discrete crop set 에서 continuous bounding box predictions 로 crop selection 을 확장하고, temporal sparsity 를 활용하여 video understanding 에 spatial-on-demand perception 을 일반화하는 방향으로 진행될 수 있다고 제안한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] TurnOPD: Making On-Policy Distillation Turn-Aware for Efficient Long-Horizon Agent Training
- [논문리뷰] Learning Adaptive Reasoning Paths for Efficient Visual Reasoning
- [논문리뷰] Act Wisely: Cultivating Meta-Cognitive Tool Use in Agentic Multimodal Models
- [논문리뷰] FP4 Explore, BF16 Train: Diffusion Reinforcement Learning via Efficient Rollout Scaling
- [논문리뷰] Apriel-Reasoner: RL Post-Training for General-Purpose and Efficient Reasoning
Review 의 다른글
- 이전글 [논문리뷰] LongCat-Flash-Prover: Advancing Native Formal Reasoning via Agentic Tool-Integrated Reinforcement Learning
- 현재글 : [논문리뷰] Look Where It Matters: High-Resolution Crops Retrieval for Efficient VLMs
- 다음글 [논문리뷰] MemDLM: Memory-Enhanced DLM Training
댓글