[논문리뷰] MemDLM: Memory-Enhanced DLM Training
링크: 논문 PDF로 바로 열기
저자: Zehua Pei, Hui-Ling Zhen, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Diffusion Language Models (DLMs) : Auto-Regressive (AR) 모델의 대안으로 제시되는 생성 모델로, 병렬 디코딩(full-attention parallel decoding)과 유연한 텍스트 생성(flexible generation)이 특징이다. 마스킹(masking)된 텍스트를 점진적으로 디노이징(denoising)하여 원본 텍스트를 재구성하는 방식으로 작동한다.
- Train-Inference Mismatch : DLM이 학습 시에는 정적(static), 단일 단계(single-step)의 마스크 예측(masked prediction) objective를 사용하지만, 추론 시에는 다단계(multi-step)의 점진적 디노이징(progressive denoising) trajectory를 통해 배포되는 과정에서의 불일치를 의미한다.
- Parametric Memory : MemDLM에서 제안하는 메커니즘으로, Inner Loop에서 업데이트되는 일련의
fast weights(예: LoRA adapter)를 통해 각 샘플의 local trajectory 경험을 캡처하는 역할을 한다. 이는 토큰 표현(token representations)에 가해지는 기억 압력(memorization pressure)을 경감시킨다. - Bi-level Optimization : MemDLM 훈련에 사용되는 최적화 프레임워크로,
fast weights를 업데이트하는 Inner Loop와 이memory에 기반하여 Base Model을 업데이트하는 Outer Loop로 구성된다. - Exposure Bias Ratio (ℛEB) :
Sequential Condition에서의 Negative Log-Likelihood를Static Condition에서의 Negative Log-Likelihood로 나눈 값으로, 모델이 자체적으로 생성한 noisy한 중간 결과에 대한 디노이징 능력의 저하 정도를 정량화하는 지표이다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Diffusion Language Models (DLMs)는 병렬 생성(parallel generation) 및 양방향 context 인지(bidirectional context awareness) 등 Auto-Regressive (AR) 모델 대비 매력적인 이점을 제공한다. 그러나 DLM은 train-inference mismatch라는 근본적인 최적화 문제에 직면한다. 학습 시 DLM은 static, single-step masked prediction objective를 통해 강하게 마스킹된 텍스트에서 원본 시퀀스를 예측하도록 훈련된다. 반면, 추론 시에는 multi-step, progressive denoising trajectory를 통해 텍스트를 생성하며, 이전 단계에서 모델이 생성한 자체적인 noisy outputs에 조건화된다.
이러한 불일치로 인해 Base Model은 실제 배포되는 sequential trajectories에 대해 훈련된 적이 없으므로, 생성 과정에서 오류가 누적(compound)될 수 있으며, 훈련 중의 최적화 landscape가 실제 배포와 잘 맞지 않게 된다. 저자들은 Exposure Bias Ratio (ℛEB)를 통해 이 문제를 정량화하며, Standard MDLM이 디노이징 단계가 진행됨에 따라 Exposure Bias가 급격히 증가함을 실험적으로 보여준다
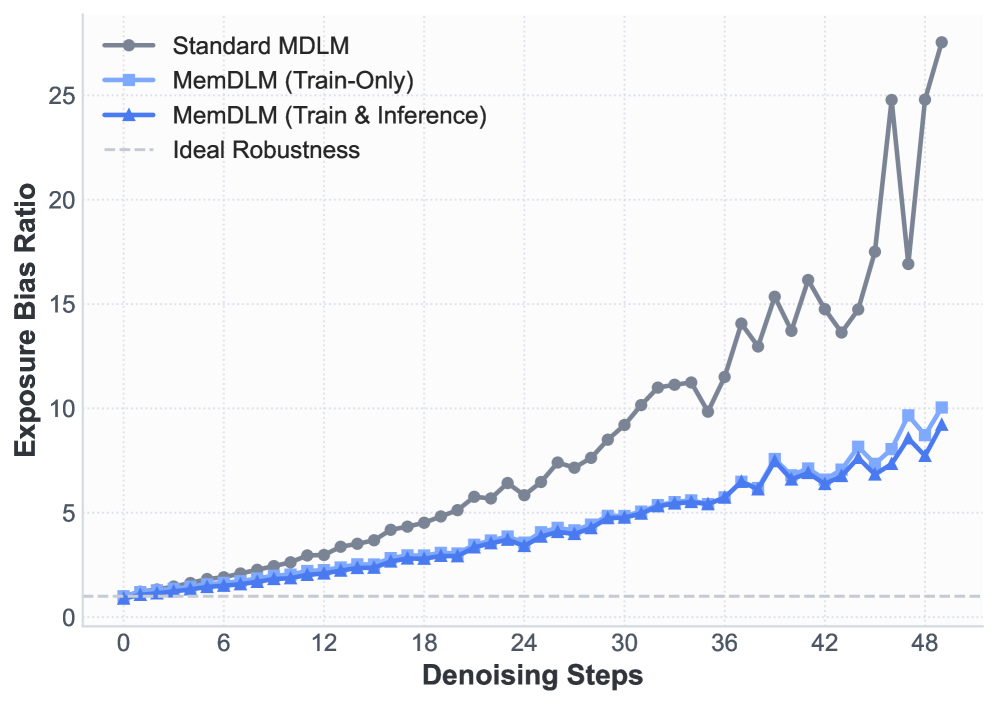
이는 모델이 자체적인 sequential noise에 매우 취약하다는 것을 의미하며, token-space의 fragile context에 전적으로 의존하는 기존 DLM의 한계를 극복하기 위한 새로운 접근 방식의 필요성을 제시한다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 train-inference mismatch를 해소하고 Base Model의 context memorization 부담을 줄이기 위해 MemDLM (Memory-Enhanced DLM)을 제안한다. MemDLM은 Bi-level Optimization 프레임워크를 통해 훈련 과정에 시뮬레이션된 디노이징 trajectory를 내장한다
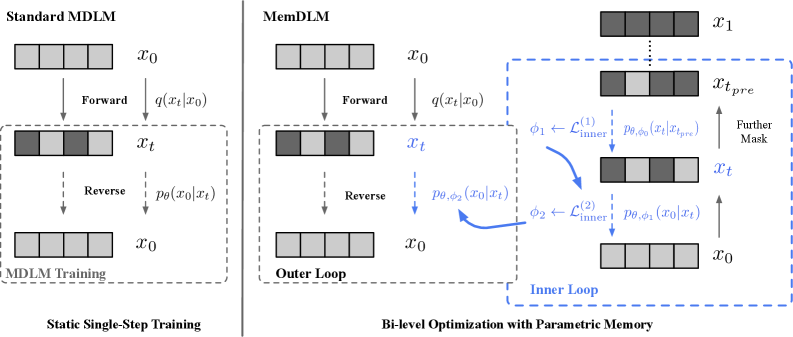
MemDLM의 Inner Loop는 parameter-efficient fast weights (예: LoRA adapters) 세트를 업데이트하여 각 샘플의 local trajectory experience를 캡처하는 Parametric Memory를 형성한다. 이 Inner Loop는 Anchor-Consistent Local Trajectory를 시뮬레이션하기 위해 두 단계로 구성된다: 첫 번째 단계인 Pre-Anchor Alignment에서는 더 noisy한 x_{t_{pre}} 상태에서 anchor state x_t로 디노이징하도록 fast weights를 업데이트하고, 두 번째 단계인 Anchor-to-Target에서는 x_t에서 최종 clean state x_0로 예측하도록 업데이트한다. Outer Loop에서는 이 internalized Parametric Memory (ϕK)에 조건화(condition)하여 Base Model의 파라미터(θ)를 업데이트한다. First-Order approximation을 사용하여 계산 비용을 절감한다 [Figure 2].
실험 결과, MemDLM은 long-context information retrieval (Needle-in-a-Haystack) 및 generalization task에서 Standard MDLM 대비 일관되게 우수한 성능을 보였다. 특히, LLaDA-MoE backbone에서 RULER Variable Tracking at 8K 성능을 78.8% 에서 95.8% 로 향상시켰으며, LLaDA2.1 backbone에서는 BABILong at 8K 성능을 47.4% 에서 57.0% 로 개선했다 [Table 1]. 심지어 Train-Only (추론 시 Inner Loop 비활성화) 설정에서도 상당한 성능 향상을 보여, Parametric Memory의 주요 이점이 훈련 과정에서 Base Model의 context representations를 개선하는 데 있음을 시사한다. Inner Loop를 추론 시에도 활성화하는 Train & Inference 설정은 추가적인 prompt-specific adaptation 효과를 제공하며, 이는 in-weight retrieval 메커니즘으로 해석된다
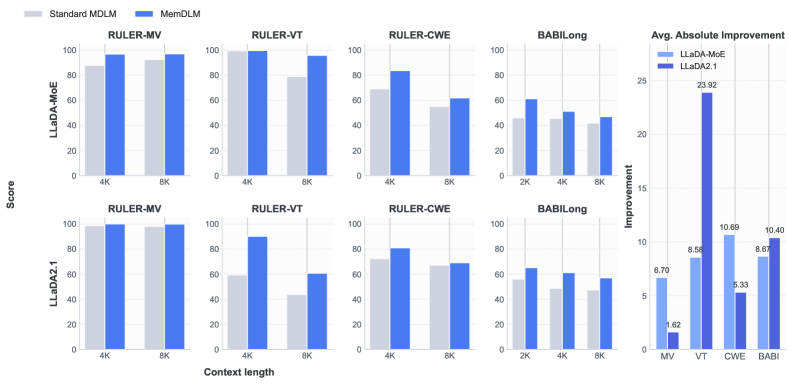
또한, MemDLM은 16K 및 32K context lengths에서도 Standard MDLM 대비 성능 우위를 유지하며 length extrapolation 능력을 입증했다 [Table 2]. 훈련 과정 분석에서는 MemDLM이 Standard MDLM보다 빠르게 train loss를 감소시키고 전반적으로 낮은 evaluation loss를 유지하여 최적화 효율성을 개선함을 확인했다 [Figure 4].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Bi-level Optimization과 Parametric Memory를 활용하는 MemDLM이라는 memory-aware training framework를 제안하여 Diffusion Language Models의 train-inference mismatch 문제를 해결했다. 핵심 결론은 훈련 중에 디노이징 trajectory를 시뮬레이션하는 것이 단순한 추론 모방을 넘어 Base Model의 학습 방식 자체를 변화시킨다는 점이다. fast weights가 batch-specific trajectory information을 흡수하도록 함으로써 token space에만 의존하여 context를 보존해야 하는 부담을 줄이고, 이는 최적화 개선, exposure bias 감소, 그리고 Train-Only 설정에서도 강력한 long-context performance로 이어졌다.
또한, 추론 시 Inner Loop를 재활성화하면 추가적인 prompt-specific adaptation 경로를 제공하며, 이는 in-weight retrieval 메커니즘으로 해석될 수 있다. 이러한 발견들은 Diffusion Language Models의 robustness와 long-context capabilities를 향상시키는 데 있어 parameter-space memory를 통한 train-inference mismatch 완화가 유망한 방향임을 시사한다. 이 연구는 학계 및 산업계에서 long-context 시나리오에서 DLM의 실용성과 성능을 크게 향상시킬 잠재력을 가진다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] dOPSD: On-Policy Self-Distillation for Diffusion Language Models
- [논문리뷰] Multimodal Continuous Reasoning via Asymmetric Mutual Variational Learning
- [논문리뷰] Multi-Block Diffusion Language Models
- [논문리뷰] BlockPilot: Instance-Adaptive Policy Learning for Diffusion-based Speculative Decoding
- [논문리뷰] Parallel Rollout Approximation for Pixel-Space Autoregressive Image Generation
Review 의 다른글
- 이전글 [논문리뷰] Look Where It Matters: High-Resolution Crops Retrieval for Efficient VLMs
- 현재글 : [논문리뷰] MemDLM: Memory-Enhanced DLM Training
- 다음글 [논문리뷰] Omni-WorldBench: Towards a Comprehensive Interaction-Centric Evaluation for World Models
댓글