[논문리뷰] Omni-WorldBench: Towards a Comprehensive Interaction-Centric Evaluation for World Models
링크: 논문 PDF로 바로 열기
저자: Meiqi Wu, Zhixin Cai, Fufangchen Zhao, Xiaokun Feng, Rujing Dang, Bingze Song, Ruitian Tian, Jiashu Zhu, Jiachen Lei, Hao Dou, Jing Tang, Lei Sun, Jiahong Wu, Xiangxiang Chu, Zeming Liu, Kaiqi Huang
1. Key Terms & Definitions (핵심 용어 및 정의)
- World Models : 주어진 상호작용 조건 하에서 환경 상태의 시간적 진화를 특징화하여 반사실적 추론(counterfactual reasoning), 계획(planning) 및 의사결정(decision-making)의 기반을 제공하는 모델.
- 4D Generation : 공간 구조(spatial structure)와 시간적 진화(temporal evolution)를 공동으로 모델링하는 비디오 기반 World Model 패러다임.
- Interactive Response : 상호작용 액션(interaction actions)이 시공간을 가로지르는 상태 전이(state transitions)를 얼마나 충실하게 반영하는지를 나타내는 World Model의 핵심 능력.
- Omni-WorldBench : 4D 환경에서 World Model의 Interactive Response 기능을 종합적으로 평가하기 위해 특별히 설계된 벤치마크.
- AgenticScore : Omni-Metrics 내에서 다양한 평가 도구의 출력을 프롬프트 의미에 따라 적응적으로 결합하여 World Model의 전반적인 성능을 정량화하는 통합 메트릭.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존 비디오 기반 World Models 의 평가 벤치마크들은 주로 시각적 충실도(visual fidelity) 및 텍스트-비디오 정렬(text-video alignment)에만 협소하게 초점을 맞추거나, 시간적 역동성(temporal dynamics)을 근본적으로 무시하는 정적 3D 재구성(3D reconstruction) 메트릭에 의존해왔다. 저자들은 World Modeling 의 미래가 공간 구조와 시간적 진화를 동시에 모델링하는 4D Generation 에 있다고 주장하며, 이때 핵심 역량은 상호작용 액션이 시공간을 가로지르는 상태 전이를 얼마나 충실하게 유도하는지를 반영하는 Interactive Response 능력이라고 강조한다. 그러나 현재까지 이 중요한 차원을 체계적으로 평가하는 벤치마크가 부재하여, World Model 디자인의 급속한 발전과 달리 전용 평가 벤치마크 개발은 뒤처져 있었다. 기존 평가 방법인 FID, FVD와 같은 일반적인 비디오 생성 메트릭이나 VBench와 같은 범용 벤치마크들은 시각적 품질과 텍스트-비디오 정렬에는 효과적이지만, 다양한 상호작용 조건 하에서 일관되고 그럴듯한 응답을 생성하는 World Model의 핵심 능력을 적절히 포착하지 못한다. 또한, WorldScore 와 같은 World Model 전용 벤치마크조차 평가하는 상호작용 형태가 주로 카메라 움직임에 국한되어 광범위한 상호작용 유형을 다루지 못하는 한계가 있었다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 이러한 격차를 해소하기 위해 4D 환경에서 World Models 의 Interactive Response 능력을 평가하기 위한 종합 벤치마크인 Omni-WorldBench 를 제안한다. Omni-WorldBench 는 크게 Omni-WorldSuite 와 Omni-Metrics 두 가지 핵심 구성 요소로 이루어진다
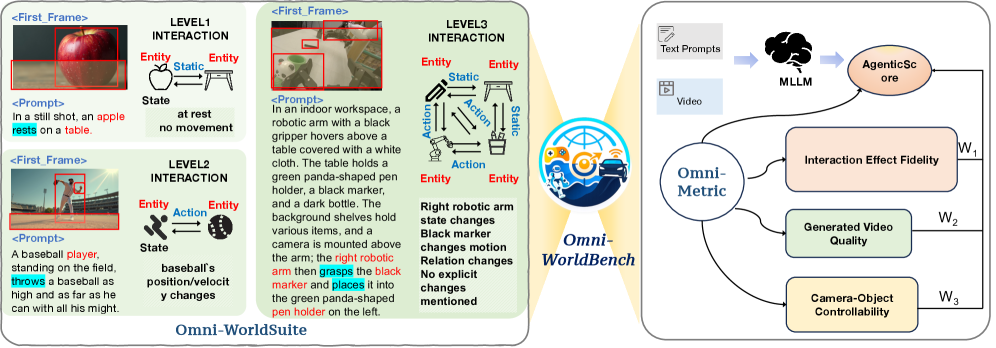
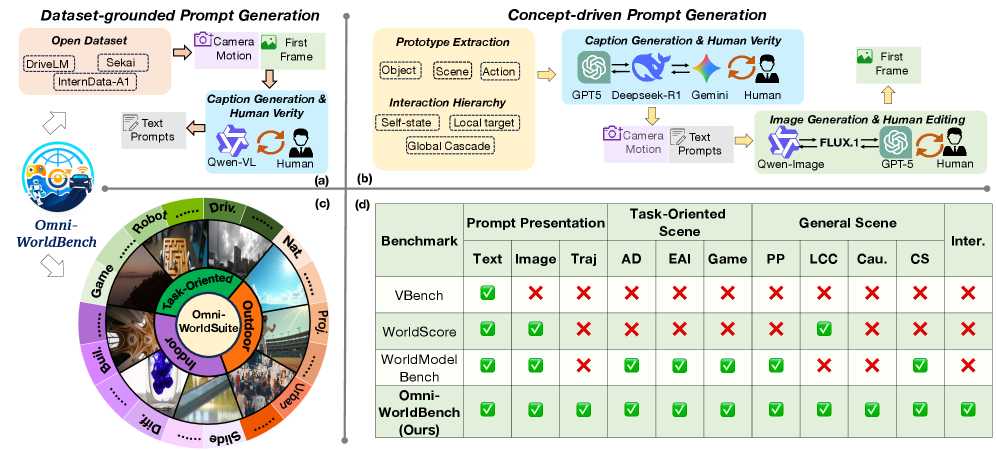
Omni-WorldSuite 는 다양한 상호작용 수준(단일 객체, 국지적 환경, 전역적 환경 변화)과 일반적인 일상 시나리오 및 자율 주행, 로봇 공학, 게임과 같은 태스크 지향 환경을 포괄하는 체계적인 프롬프트 스위트이다. 이 프롬프트는 데이터 기반(Dataset-grounded) 및 개념 기반(Concept-driven) 생성 전략을 통해 구축되며, 텍스트 설명과 초기 프레임 이미지로 정의된다
특히, 카메라 제어가 필요한 프롬프트에는 카메라 궤적 정보가 추가로 제공되어 World Model의 동적 제어 능력 평가를 지원한다

Omni-WorldSuite 는 1,068개 의 평가 프롬프트를 포함하며, Physics Principles, Commonsense, Causality, Camera Motion, Loop-Closure Consistency, Spatial Constraints 등 6가지 주요 주석 차원에서 균형 잡힌 분포를 보여준다. Omni-Metrics 는 World Models 의 Fidelity와 Consistency를 종합적으로 평가하기 위한 에이전트 기반 프로토콜이다. 이는 세 가지 주요 평가 차원을 포함한다: Generated Video Quality (정적 및 동적 시각적 충실도), Camera-Object Controllability (장면 일관성 및 객체 제어 가능성), Interaction Effect Fidelity (물리 법칙, 이벤트 상호작용, 시간적 순서 논리 준수)이다. 이질적이지만 상호 보완적인 이 차원들의 결과를 멀티모달 대규모 언어 모델(MLLM) 기반의 집계 에이전트(aggregation agent)가 프롬프트 의미에 따라 적응적으로 결합하여 최종 통합 메트릭인 AgenticScore 를 산출한다. AgenticScore 는 각 차원의 서브 메트릭 결과(예: InterStab-L, InterStab-N, InterCov, InterOrder for Interaction Effect Fidelity)를 종합하여 모델의 상호작용적 표현 능력을 포괄적으로 반영한다.
저자들은 Text-to-Video (T2V) , Image-to-Video (IT2V) , Camera-Conditioned 모델을 포함한 18개 의 대표적인 World Model에 대한 광범위한 평가를 수행했다 [cite: 1, Table 1]. 정량적 평가 결과, Image-to-Video (IT2V) 패러다임의 모델이 가장 높은 성능 잠재력을 보였으며, Wan2.2 가 75.92% 의 AgenticScore 로 모든 모델 중 가장 높은 점수를 달성했고, Cosmos 가 75.42% 로 그 뒤를 이었다 [cite: 1, Table 1]. Interaction Effect Fidelity 측면에서는 IT2V 그룹이 높은 일관성을 보였으나, Camera-Conditioned 그룹의 일부 모델(예: WonderWorld )은 InterStab-L 에서 84.96% 로 높은 점수를 기록하면서도 InterStab-N 에서는 24.89% 로 급격히 낮은 점수를 보여, 복잡한 카메라 스케줄링 하에서 상호작용 로직을 유지하는 것이 여전히 도전 과제임을 시사했다 [cite: 1, Table 1]. Generated Video Quality 에서 Temporal Flickering 과 Motion Smoothness 는 대부분의 모델에서 95.00% 이상으로 높게 나타났지만, Dynamic Degree 에서는 모델 간 상당한 차이를 보였다 [cite: 1, Table 1]. 특히 ViewCrafter 와 WonderWorld 는 Dynamic Degree 에서 100.00% 를 달성했다 [cite: 1, Table 1]. Camera-Object Controllability 에서 WonderWorld 는 Camera Control 에서 96.12% 의 압도적인 우위를 보였다 [cite: 1, Table 1]. Object Control 에서는 Cosmos (94.90%) 와 Wan2.2 (94.01%) 가 IT2V 그룹에서 뛰어난 성능을 보였다 [cite: 1, Table 1]. 이러한 결과는 현재 모델들이 전통적인 비디오 품질 메트릭에서는 강점을 보이지만, 액션 조건부 세계 진화, 인과적 상호작용 일관성, 그리고 카메라-객체 공동 제어 능력에서는 여전히 명확한 한계를 드러낸다는 것을 보여준다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 비디오 World Models 의 Interactive Response 능력을 평가하기 위한 최초의 벤치마크인 Omni-WorldBench 를 성공적으로 제시한다. 이 벤치마크는 기존 평가 방식의 시각적 품질 및 모션 현실성 중심의 한계를 넘어, 액션 기반 장면 진화, 중간 상태 전이, 그리고 상호작용 프롬프트 하의 Causal Consistency 를 강조하는 보다 포괄적이고 전체적인 평가 관점을 제공한다. Omni-WorldSuite 와 AgenticScore 를 포함하는 Omni-Metric 이라는 엄격한 평가 프레임워크를 통해 18개 의 다양한 비디오 생성 및 World Model을 체계적으로 평가한 결과, 대부분의 모델이 높은 시각적 충실도와 모션 부드러움을 달성했지만, 인과적으로 근거한 상호작용 역학을 유지하는 능력에는 여전히 상당한 격차가 존재함을 밝혀냈다.
Omni-WorldBench 는 현재 World Models 시스템의 시각적 현실성과 진정한 상호작용성(true interactivity) 사이의 격차를 진단하고, 더욱 상호작용적이며 Causal Consistency 가 높은 World Model 연구를 발전시키기 위한 표준화된 테스트베드 역할을 할 것으로 기대된다. 이 연구는 World Model 평가에 대한 새로운 패러다임을 제시하며, 미래 4D World Model Generation 분야의 발전에 중요한 지침을 제공하고 연구를 가속화하는 데 기여할 것이다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Infinite Worlds with Versatile Interactions
- [논문리뷰] Imagined Rollouts are Kinematic, Not Dynamic: A Diagnosis of Long-Horizon World-Model Failure
- [논문리뷰] QVal: Cheaply Evaluating Dense Supervision Signals for Long-Horizon LLM Agents
- [논문리뷰] PhysisForcing: Physics Reinforced World Simulator for Robotic Manipulation
- [논문리뷰] Hallucination in World Models is Predictable and Preventable
Review 의 다른글
- 이전글 [논문리뷰] MemDLM: Memory-Enhanced DLM Training
- 현재글 : [논문리뷰] Omni-WorldBench: Towards a Comprehensive Interaction-Centric Evaluation for World Models
- 다음글 [논문리뷰] On the Direction of RLVR Updates for LLM Reasoning: Identification and Exploitation
댓글