[논문리뷰] On the Direction of RLVR Updates for LLM Reasoning: Identification and Exploitation
링크: 논문 PDF로 바로 열기
저자: Kexin Huang, Haoming Meng, Junkang Wu, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Reinforcement Learning with Verifiable Rewards (RLVR) : Task-specific verifiers를 사용하여 Large Language Model (LLM)의 generation policy를 fine-tune함으로써 reasoning ability를 증폭시키는 강화 학습 기법.
- Signed, Token-Level Log Probability Difference (Δlogp) : Base model (πBase)과 RLVR fine-tuned model (πRL) 간의 token-level log probability 차이 (logπRL(yt|x,y<t)−logπBase(yt|x,y<t))를 나타내며, RLVR이 각 token의 probability mass를 어떻게 변화시켰는지 directionally 포착하는 핵심 지표.
- Test-Time Extrapolation : 학습된 Δlogp 방향을 따라 RLVR model의 distribution을 선택적으로 증폭시켜, 추가 training 없이 reasoning accuracy를 개선하는 test-time augmentation 기법.
- Advantage Reweighting : Training 과정에서 low-probability tokens에 대한 learning signal을 증폭시켜 reasoning performance를 향상시키는 training-time method.
- Sparse Updates : RLVR이 LLM의 output sequence 내에서 소수의 critical tokens에만 변화를 주어 reasoning capability를 개선하는 현상.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
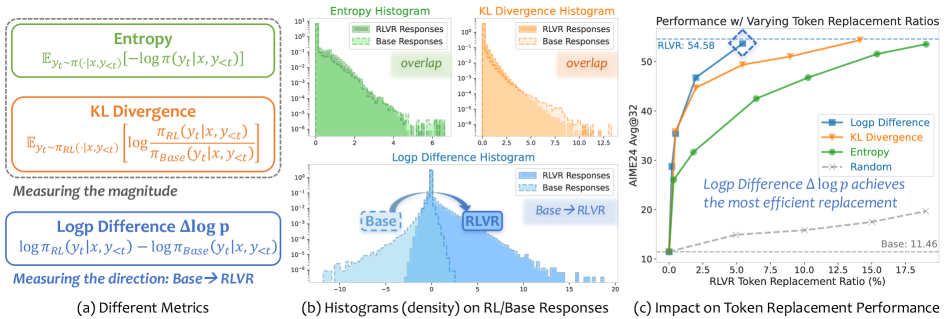
Large Language Models (LLMs)의 reasoning capability는 Reinforcement Learning with Verifiable Rewards (RLVR)와 같은 기법을 통해 크게 발전했습니다. 기존 연구들은 RLVR로 인한 변화가 output sequence의 small subset of tokens에만 영향을 미치는 sparse 하다는 점을 일관되게 보여주었지만, 주로 이러한 update의 magnitude 에 초점을 맞추어 왔습니다. 그러나 magnitude-based metrics (예: entropy, KL divergence)는 Figure 1(b)에 나타난 바와 같이 base model과 RLVR model 간의 분포 변화를 충분히 특성화하지 못하며, 이는 두 모델의 histogram이 거의 identical하기 때문입니다. 이러한 한계는 RLVR이 어떻게 reasoning gains를 제공하는지에 대한 심층적인 이해를 방해하며, update의 direction 이 간과되어 왔음을 시사합니다. 본 연구는 이러한 gap을 해결하고 RLVR update의 direction을 분석함으로써 LLM reasoning 개선을 위한 새로운 통찰력을 제공하고자 합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 RLVR update의 direction 을 분석하기 위해 Signed, Token-Level Log Probability Difference (Δlogp) 를 핵심 metric으로 제안합니다. Δlogp는 base model (πBase)과 RLVR model (πRL) 간의 token-level log probability 차이를 나타내며, positive value는 πRL이 해당 token의 probability를 증가시켰음을, negative value는 감소시켰음을 의미합니다. Figure 1(b)에서 Δlogp의 histogram은 명확한 bimodal pattern 을 보여주며, 이는 magnitude-based metrics에서는 나타나지 않는 directional signature를 포착함을 입증합니다.
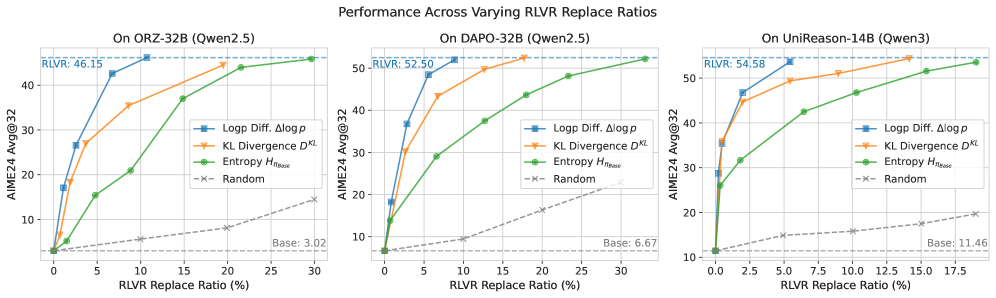
저자들은 Selective Token Replacement 실험을 통해 Δlogp의 utility를 검증했습니다. 이 실험에서는 각 metric(entropy, KL divergence, Δlogp)이 식별한 salient positions에서 base model의 token을 RLVR model의 token으로 교체하여 reasoning performance를 측정했습니다. Figure 1(c)와 Figure 2에서 볼 수 있듯이, Δlogp를 기준으로 token을 선택하는 것이 가장 적은 수의 replacement (약 10% 의 tokens)로 RLVR-level performance를 회복하여, reasoning-critical updates를 정밀하게 식별하는 Δlogp의 우수성을 보여줍니다. 이는 magnitude-only metrics보다 더 높은 precision을 가집니다.
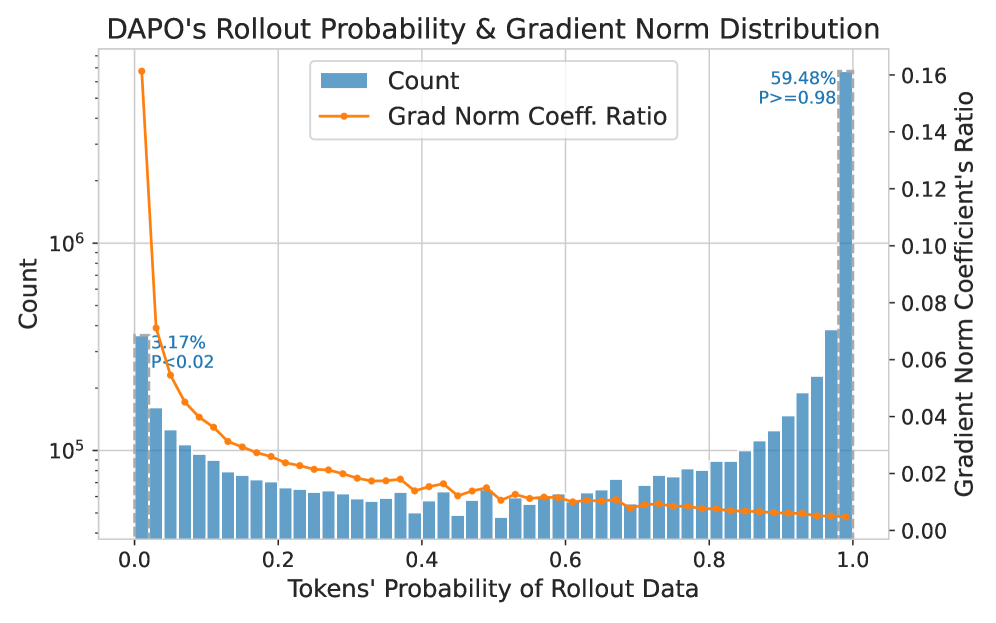
또한, 저자들은 RLVR의 sparse update가 low-probability tokens 에 대한 policy gradient의 내재적인 집중에서 비롯된다는 gradient-based explanation 을 제시합니다. Lemma 3.1은 softmax-parameterized LLM policy의 gradient ℓ1-norm이 1-πθ(y)에 비례하며, 이는 low-probability tokens가 disproportionately large gradient updates를 받는다는 것을 의미합니다. Figure 3(a)는 low-probability tokens가 전체 gradient mass의 대부분을 차지함을 실증적으로 보여줍니다. Figure 3(b)는 high-Δlogp tokens가 base 및 RLVR model 모두에서 lower probability를 가짐을 확인하며, RLVR의 가장 중요한 updates가 이러한 low-probability tokens를 target으로 한다는 것을 입증합니다. Figure 3(c)의 top-p sampling 실험 결과는 low-probability tokens를 제외하면 RLVR training performance가 크게 저하됨을 보여주며, 이들이 reasoning improvement에 필수적임을 causal하게 입증합니다.
이러한 통찰력을 바탕으로, 저자들은 두 가지 practical applications을 제안합니다:
- Test-Time Extrapolation : Δlogp를 "reasoning direction"으로 간주하고, RLVR model의 distribution을 이 방향으로 선택적으로 증폭시키는 기법입니다. Figure 4는 ORZ-32B, DAPO-32B, UniReason-14B 모델에서 Selective Extrapolation이 πRL 대비 더 높은 Avg@32 성능을 달성함을 보여주며, 이는 Δlogp 방향으로 더 나아가는 것이 reasoning accuracy에서 incremental gains를 제공함을 시사합니다. 예를 들어, DAPO-32B 모델의 경우 Avg@32는 52.50% 에서 55.31% 로 향상됩니다.
- Training-Time Advantage Reweighting : high Δlogp와 low-probability tokens 간의 상관관계를 활용하여 DAPO objective (Equation 8)에서 low-probability tokens의 learning signal을 증폭시키는 방법입니다. Table 2는 Qwen2.5-Math-7B 및 Qwen3-8B-Base 모델에서 이 reweighting method가 AIME-24, AIME-25, AMC 벤치마크 전반에 걸쳐 Avg@32 및 Pass@16 성능을 DAPO baseline 대비 일관되게 향상시킴을 보여줍니다. Qwen2.5-Math-7B의 평균 Avg@32는 DAPO의 42.12% 에서 43.75% 로, Pass@16은 57.86% 에서 62.33% 로 개선되었습니다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 RLVR update를 분석하는 데 있어 logp difference (Δlogp) 기반의 directional analysis 가 기존의 magnitude-based metrics (entropy, divergence)보다 sparse 하고 reasoning-critical 한 update를 식별하는 데 더 효과적임을 입증했습니다. 이러한 통찰을 바탕으로, 저자들은 reasoning 성능을 향상시키기 위한 두 가지 실용적인 전략을 제안했습니다: test-time extrapolation 을 통해 directional update를 증폭하고, training-time advantage reweighting 을 통해 Δlogp가 강조하는 low-probability tokens에 학습을 집중하는 것입니다. 이 두 방법론은 다양한 설정에서 reasoning performance를 개선하였으며, RLVR의 update direction을 진단하고 개선하는 것이 핵심 원칙임을 입증했습니다. 이 연구는 RLVR의 효과를 분석하고 개선하는 새로운 관점을 제시하며, 향후 더 효율적이고 강력한 LLM reasoning 모델 개발에 기여할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Transferability for General Reasoning: An Automated Curriculum for Multi-Domain RLVR
- [논문리뷰] From Reasoning Chains to Verifiable Subproblems: Curriculum Reinforcement Learning Enables Credit Assignment for LLM Reasoning
- [논문리뷰] Nudging Beyond the Comfort Zone: Efficient Strategy-Guided Exploration for RLVR
- [논문리뷰] Rectifying LLM Thought from Lens of Optimization
- [논문리뷰] LSPO: Length-aware Dynamic Sampling for Policy Optimization in LLM Reasoning
Review 의 다른글
- 이전글 [논문리뷰] Omni-WorldBench: Towards a Comprehensive Interaction-Centric Evaluation for World Models
- 현재글 : [논문리뷰] On the Direction of RLVR Updates for LLM Reasoning: Identification and Exploitation
- 다음글 [논문리뷰] OpenResearcher: A Fully Open Pipeline for Long-Horizon Deep Research Trajectory Synthesis
댓글