[논문리뷰] OpenResearcher: A Fully Open Pipeline for Long-Horizon Deep Research Trajectory Synthesis
링크: 논문 PDF로 바로 열기
저자: Zhuofeng Li, Dongfu Jiang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Deep Research Agents : 반복적인 탐색, 증거 취합, 다단계 추론을 통해 장기적인 연구 작업을 수행할 수 있는 시스템을 의미합니다.
- Long-Horizon Trajectories : 복잡한 연구 과제를 해결하기 위해 필요한, 검색, 브라우징, 추론 등 100회 이상의 도구 호출(Tool Calls)을 포함하는 다단계 상호작용 시퀀스입니다.
- Offline Trajectory Synthesis : 라이브 웹 API에 의존하지 않고, 로컬에서 구축된 고정된 문서 Corpus와 검색 엔진을 활용하여 연구 Trajectory를 생성하는 방법론입니다.
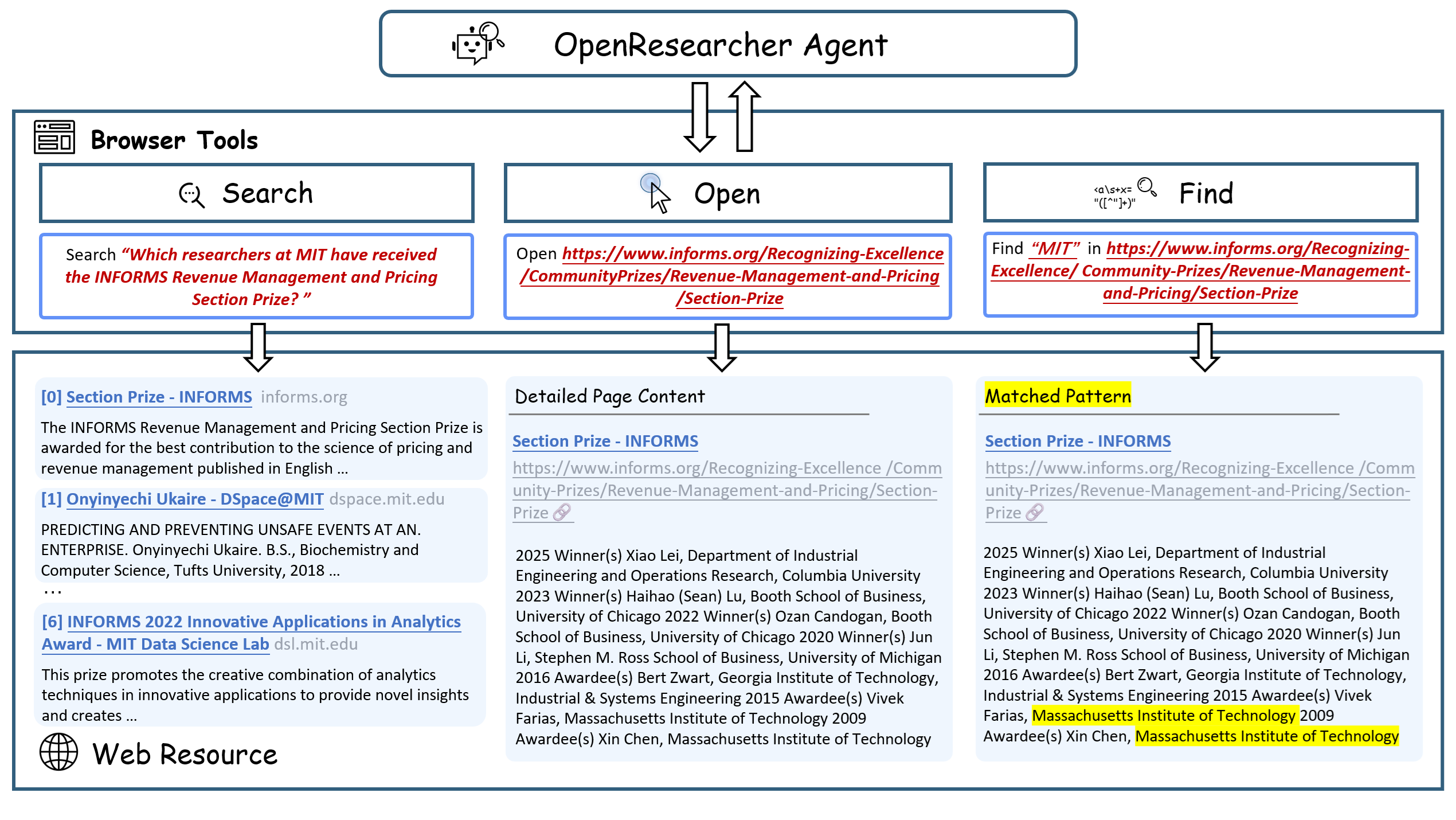
- Browser Primitives (search, open, find) : OpenResearcher가 제안하는 핵심 브라우저 동작 도구로, search 는 광범위한 정보 검색, open 은 문서 내용 확인, find 는 문서 내 특정 정보 탐색을 가능하게 하여 다차원적인 정보 발견을 지원합니다.
- Supervised Fine-tuning (SFT) : 대규모 "Teacher" 모델이 생성한 고품질의 Long-Horizon Trajectory 데이터셋을 사용하여 더 작은 "Student" 모델의 성능을 향상시키는 학습 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Deep Research Agent를 훈련시키기 위해서는 검색, 증거 취합 및 다단계 추론이 복합적으로 이루어지는 Long-Horizon Trajectory가 필수적입니다. 그러나 기존 데이터 수집 파이프라인은 대부분 독점적인 웹 API에 의존하고 있어, 대규모 Trajectory Synthesis가 고비용 , 불안정 , 재현 불가능 하다는 한계점이 있습니다. 예를 들어, Search-R1과 같은 이전 연구들은 현실적인 Deep Research 환경에 비해 훨씬 짧은 2-5회 상호작용의 Trajectory만을 생성합니다. WebExplorer나 MiroThinker와 같은 시스템들은 더 긴 Trajectory를 생성할 수 있지만, 라이브 웹 검색 API를 사용하기 때문에 모든 실패한 검색 경로에도 API 비용이 발생하며, 변화하는 라이브 웹 환경으로 인해 데이터 파이프라인의 재현성이 떨어집니다. 또한, Gold Document Annotation의 부재로 인해 관련 증거가 언제 발견되거나 누락되었는지에 대한 정밀한 분석이 어렵습니다. 이 연구는 확장 가능하고, 저비용이며, 재현 가능하고, 분석적으로 유용한 방식으로 고품질의 Long-Horizon Deep Research Trajectory를 합성하는 방법을 제안함으로써 이러한 핵심 문제들을 해결하고자 합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
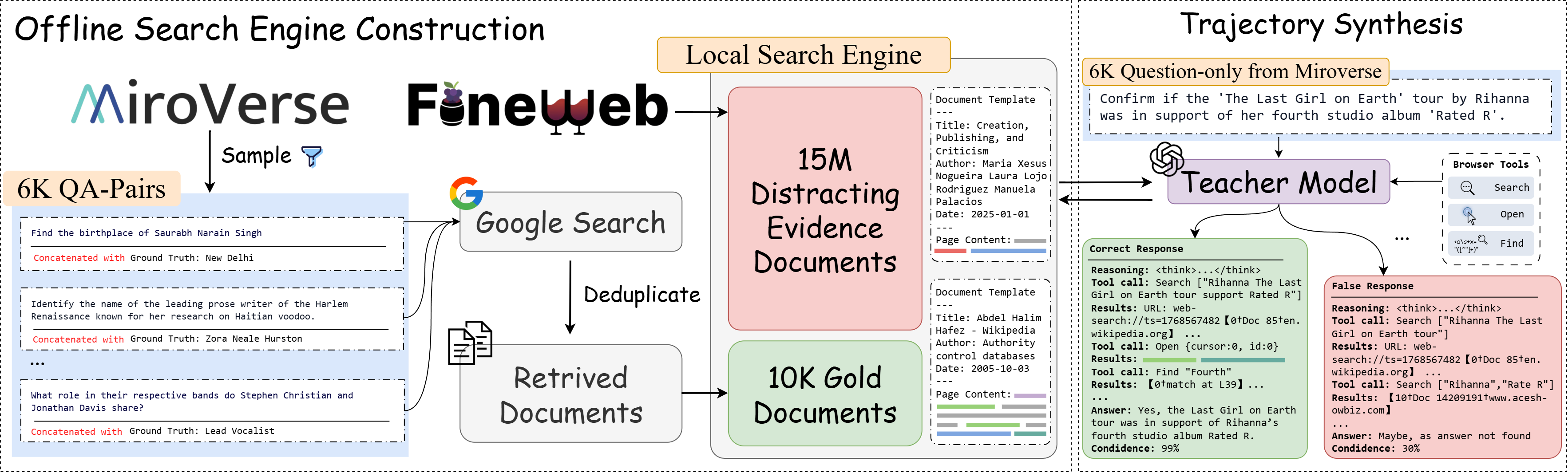
OpenResearcher는 Corpus 구축과 Trajectory 생성을 분리하는 파이프라인을 제안합니다. 한 번의 온라인 Corpus Bootstrapping 을 통해 Gold Document를 포함하는 15M 규모의 오프라인 Corpus와 검색 엔진을 구축하고, 이 환경에서 Multi-turn Synthesis Loop를 완전히 오프라인으로 실행합니다. 이 모델은 세 가지 명시적인 Browser Primitives 인 search , open , find 를 활용하여 검색 스니펫부터 전체 페이지 콘텐츠, 그리고 페이지 내 특정 증거 로컬라이제이션까지 다단계 정보 발견을 수행합니다 [Figure 3, cite: 1]. GPT-OSS-120B 를 Teacher Model로 사용하여 97K개 이상 의 Trajectory를 합성했으며, 이 중 상당수는 100회 이상의 Tool Calls 를 필요로 하는 Long-Horizon 질의를 포함합니다.
합성된 Trajectory를 사용하여 NVIDIA-Nemotron-3-Nano-30B-A3B-Base-BF16 모델을 Supervised Fine-tuning (SFT) 한 결과, BrowseComp-Plus 벤치마크에서 54.8% 의 정확도를 달성하여 Base Model 대비 +34.0% 의 상당한 성능 향상을 보였습니다. 이는 GPT-4.1 (36.4%) , Claude-4-Opus (36.8%) 와 같은 강력한 Proprietary Baseline보다도 우수한 결과입니다. 또한, BrowseComp (26.3%) , GAIA (64.1%) , xbench-DeepSearch (65.0%) 등 라이브 웹 벤치마크에서도 경쟁력 있는 성능을 유지하며 기존 Open-source Deep Research 시스템들을 크게 능가했습니다. 이러한 성능 향상은 라이브 웹 데이터로 추가 훈련 없이, 오프라인 환경에서 합성된 고품질 Trajectory만으로 달성되었습니다.
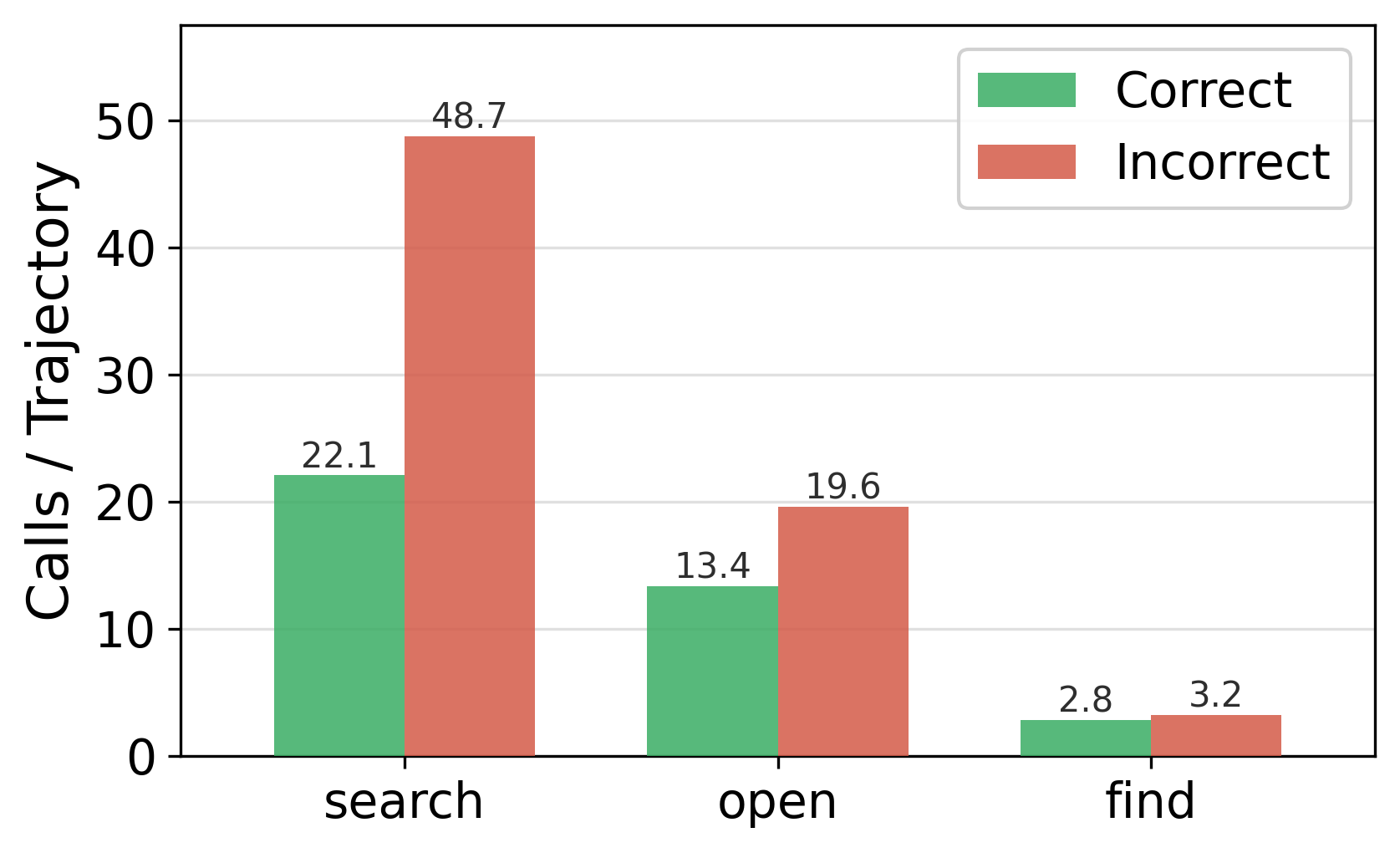
Ablation Study 결과, final-answer correctness 만을 기준으로 Trajectory를 필터링하는 것이 SFT 성능에 미치는 영향은 미미했으며, 오히려 incorrect trajectory 도 유용한 학습 신호를 제공함이 밝혀졌습니다. 반면, one-time online bootstrapping 을 통한 Corpus Coverage는 효과적인 오프라인 Synthesis에 필수적이며, Gold Document를 제외할 경우 BrowseComp-Plus 정확도가 54.81% 에서 6.35% 로 급격히 하락하는 것을 확인했습니다. 또한, search-only 에이전트 대비 search+open+find 의 모든 Browser Primitives 를 사용하는 것이 정확도를 43.86% 에서 62.17% 로 향상시키고, Gold-Document Hit Rate 를 높이며, 평균 Tool Calls 및 Token Usage 를 줄이는 데 크게 기여했습니다 [Figure 4, cite: 4]. [Figure 2, cite: 1]는 OpenResearcher의 전체 파이프라인 개요를 보여줍니다.
4. Conclusion & Impact (결론 및 시사점)
OpenResearcher는 Long-Horizon Deep Research Trajectory Synthesis의 재현성을 향상시키기 위해 검색 및 브라우징 루프를 제어 가능한 오프라인 환경으로 전환하는 완전히 개방된 파이프라인을 제시합니다. 이는 라이브 웹 API 호출을 오프라인 설정으로 대체하여 대규모 Trajectory 생성 비용을 절감하고 독점 인프라에 대한 의존도를 낮춥니다. search , open , find 와 같은 명시적인 브라우저 추상화는 현실적인 정보 탐색 행동을 모델링하기 위한 간단한 인터페이스를 제공합니다. OpenResearcher로 합성된 Trajectory는 고정된 Corpus 평가 및 라이브 웹 벤치마크 전반에서 Open-Weight Deep Research Agent를 후속 훈련하는 데 효과적임이 입증되었습니다. 본 연구의 체계적인 분석은 데이터 필터링 전략, 에이전트 구성 선택, 검색 성공이 최종 답변 정확도와 어떻게 연관되는지 등 Deep Research 파이프라인 설계에 대한 실질적인 통찰력을 제공하며, 검색 감독에 대한 보다 체계적인 연구와 미래 에이전트 개발을 위한 지침을 제공할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Inference-Time Scaling of Verification: Self-Evolving Deep Research Agents via Test-Time Rubric-Guided Verification
- [논문리뷰] Step-DeepResearch Technical Report
- [논문리뷰] Dockerless: Environment-Free Program Verifier for Coding Agents
- [논문리뷰] Struct-Searcher: Agentic Structural Thinking Advances Multimodal Deep Information Seeking
- [논문리뷰] Compress-Distill: Reasoning Trace Compression for Efficient Knowledge Distillation
Review 의 다른글
- 이전글 [논문리뷰] On the Direction of RLVR Updates for LLM Reasoning: Identification and Exploitation
- 현재글 : [논문리뷰] OpenResearcher: A Fully Open Pipeline for Long-Horizon Deep Research Trajectory Synthesis
- 다음글 [논문리뷰] PivotRL: High Accuracy Agentic Post-Training at Low Compute Cost
댓글