[논문리뷰] DR-Venus: Towards Frontier Edge-Scale Deep Research Agents with Only 10K Open Data
링크: 논문 PDF로 바로 열기
메타데이터
저자: Venus Team (Ant Group)
1. Key Terms & Definitions (핵심 용어 및 정의)
- Deep Research Agents: 복잡한 정보 탐색 작업을 해결하기 위해 반복적인 검색, 브라우징, 증거 수집 및 답변 합성을 수행하는 에이전트 모델.
- Agentic SFT (Supervised Fine-Tuning): 에이전트의 기본적인 행동 패턴(추론, 도구 사용, 답변 생성)을 학습시키기 위한 지도 학습 단계로, 본 논문에서는 데이터 품질 향상과 데이터 활용 최적화에 집중함.
- IGPO (Information Gain-based Policy Optimization): 정보 이득(Information Gain)을 기반으로 turn-level 보상을 구성하여, 학습 데이터 효율성과 지도 신호의 밀도를 높이는 에이전트 강화 학습 알고리즘.
- Edge-Scale: 실제 배포 환경에서의 비용, 레이턴시, 개인정보 보호를 위해 최적화된 소규모 모델(예: 4B 파라미터).
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 제한적인 Open Data 환경에서 강력한 소규모 Deep Research Agent를 효율적으로 훈련하는 방법을 연구한다. 기존 연구들은 주로 대규모 모델에 의존하거나 복잡한 비공개 데이터 파이프라인을 사용하므로, 경량화된 에이전트 모델을 위한 실용적인 훈련 기법이 부족한 상황이다. 소규모 모델은 노이즈가 있는 학습 데이터에 더 민감하며, 복잡한 long-horizon 작업 수행 시 강화 학습 과정에서 수렴 실패(Advantage collapse)를 겪기 쉽다. 저자들은 데이터 품질을 정제하고 활용도를 극대화함으로써 이러한 한계를 극복하고자 한다 [Figure 1].
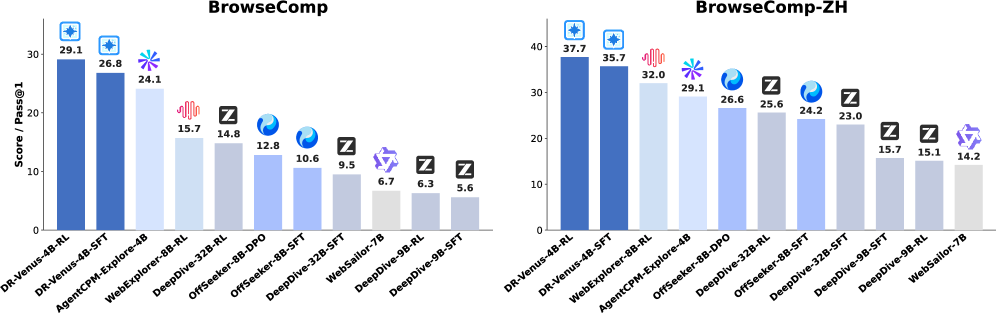
Figure 1 — DR-Venus-4B 성능 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 10K 규모의 Open Data만을 사용하여 4B 규모의 DR-Venus를 훈련하는 2단계 파이프라인을 제안한다. 첫 번째 단계인 Agentic SFT에서는 데이터 정제와 long-horizon 궤적 재샘플링(turn-aware resampling)을 통해 모델의 기초 능력을 확립한다. 두 번째 단계인 Agentic RL에서는 IGPO를 도입하여 정보 이득 기반의 turn-level 보상과 포맷 규제(format penalty)를 결합함으로써, 모델의 실행 신뢰성을 강화한다.
실험 결과, DR-Venus-4B-RL은 기존 9B 이하의 소규모 에이전트 모델들을 모든 벤치마크에서 능가하며, 30B 클래스 시스템과의 성능 격차를 크게 좁혔다 [Table 1]. 특히, Pass@K 평가를 통해 소규모 모델의 잠재적 성능 한계가 상당히 높음을 입증하였으며, 이는 테스트 타임 스케일링이 소규모 추론 모델의 가능성을 여는 데 효과적임을 시사한다. 또한, 성공적인 궤적은 검색(Search)보다 브라우징(Browse) 도구를 더 효과적으로 활용하는 경향이 있음을 확인하였다 [Figure 3].
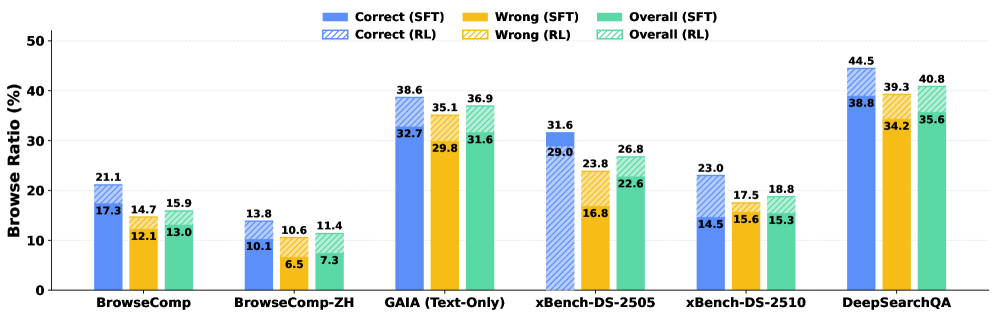
Figure 3 — SFT/RL 에이전트 브라우징 비율
4. Conclusion & Impact (결론 및 시사점)
본 연구는 고품질의 데이터 정제 및 효율적인 강화 학습 전략을 통해 4B 규모의 경량 모델로도 강력한 Deep Research 성능을 달성할 수 있음을 입증하였다. 이는 모델의 규모만이 성능을 결정하는 요소가 아니며, 데이터 활용 능력이 Edge-Scale 에이전트 배포의 핵심임을 보여준다. 제안된 모델, 코드, 그리고 학습 레시피의 공개는 향후 소규모 모델 기반의 에이전트 연구를 위한 중요한 출발점이 될 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] SlimSearcher: Training Efficiency-Aware Web Agents via Adaptive Reward Gating
- [논문리뷰] DRIFT: Decoupled Rollouts and Importance-Weighted Fine-Tuning for Efficient Multi-Turn Optimization
- [논문리뷰] QUEST: Training Frontier Deep Research Agents with Fully Synthetic Tasks
- [논문리뷰] InfoPO: Information-Driven Policy Optimization for User-Centric Agents
- [논문리뷰] ProAct: Agentic Lookahead in Interactive Environments
Review 의 다른글
- 이전글 [논문리뷰] CreativeGame:Toward Mechanic-Aware Creative Game Generation
- 현재글 : [논문리뷰] DR-Venus: Towards Frontier Edge-Scale Deep Research Agents with Only 10K Open Data
- 다음글 [논문리뷰] DeVI: Physics-based Dexterous Human-Object Interaction via Synthetic Video Imitation
댓글