[논문리뷰] DeVI: Physics-based Dexterous Human-Object Interaction via Synthetic Video Imitation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Hyeonwoo Kim, Jeonghwan Kim, Kyungwon Cho, Hanbyul Joo et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- DeVI (Dexterous Video Imitation): 고품질 3D 모션 캡처 데이터 없이 텍스트 기반의 합성 비디오로부터 dexterous hand-object manipulation을 학습하는 물리 기반 프레임워크입니다.
- Hybrid Imitation Target: 3D human pose(3D 재구성)와 2D object trajectory(2D 추적)를 결합하여 물리 시뮬레이션의 학습 목표로 활용하는 데이터 포맷입니다.
- Visual HOI Alignment: 2D 비디오 생성물과 3D 물체 사이의 정합성을 높이기 위해 SMPL-X 파라미터를 최적화하는 기법입니다.
- Hybrid Tracking Reward: 3D 인체 추적 보상과 2D 물체 추적 보상을 결합하여 에이전트가 복잡한 dexterous 상호작용을 imitation하도록 유도하는 강화학습 보상 함수입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 기존 물리 기반 시뮬레이션의 한계인 복잡한 Dexterous Human-Object Interaction (HOI) 모델링의 어려움을 해결하는 것을 목표로 합니다. 기존 연구들은 고품질의 3D 모션 캡처 데이터에 의존하여 확장성이 낮고, 학습 가능한 객체와 동작 범위가 매우 제한적이라는 문제가 있습니다 [Figure 1]. 2D 비디오 생성 모델이 높은 시각적 사실성을 제공함에도 불구하고, 이를 3D 물리 제어의 정확한 타겟으로 변환하는 것은 여전히 기술적 난제입니다 [Figure 3]. 따라서 저자들은 대규모 비디오 생성 모델의 풍부한 상호작용 지식을 활용하면서, 물리적으로 타당한 제어를 가능케 하는 새로운 프레임워크인 DeVI를 제안합니다.

Figure 1 — DeVI 프레임워크 개요
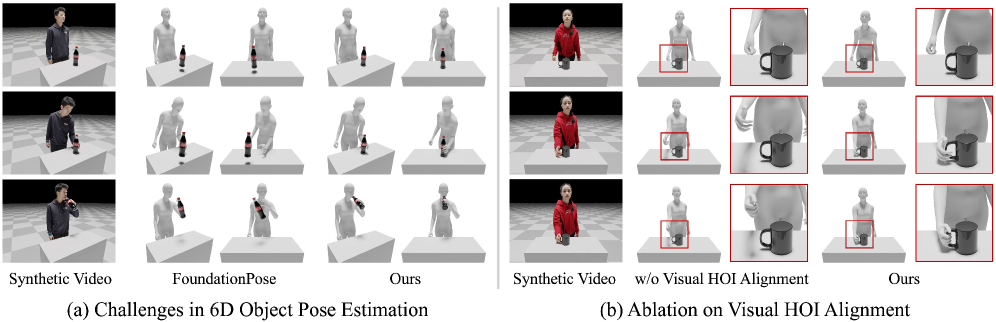
Figure 3 — 4D HOI 재구성의 도전 과제
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 저자들은 텍스트 기반의 합성 비디오에서 hybrid imitation target을 추출하여 이를 통해 humanoid control policy를 학습하는 DeVI 프레임워크를 제안합니다 [Figure 2]. 우선 3D 인간 모델과 물체를 포함한 씬에서 텍스트 프롬프트를 사용하여 2D HOI 비디오를 생성합니다. 생성된 비디오로부터 monocular human motion estimator와 2D object tracker를 활용해 3D 인체 동작과 2D 물체 궤적을 추출하고, Visual HOI Alignment 과정을 통해 3D 인체 모델을 비디오 및 물체와 시공간적으로 정렬합니다 [Figure 4]. 최종적으로 3D 인체 및 2D 물체 추적 정보를 결합한 hybrid tracking reward를 사용하여 PPO 기반의 강화학습을 수행합니다 [Figure 5]. Table 1의 정량적 평가 결과, DeVI는 MPJPE (All) 및 Tobj 지표에서 기존 Baseline인 PhysHOI, SkillMimic, InterMimic 대비 우수한 imitation 성능을 보였습니다. 특히 2D object trajectory를 활용하는 것만으로도 기존 6D pose 기반 학습 방법론을 능가하는 일반화 능력을 입증하였습니다.
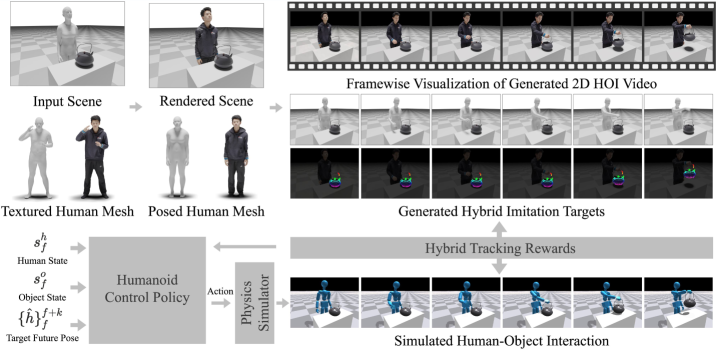
Figure 2 — DeVI 학습 아키텍처
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 텍스트 기반의 비디오 생성을 물리 기반 제어의 motion planner로 활용하여, 고비용의 3D 데이터 수집 없이도 dexterous HOI를 구현하는 DeVI를 제안하였습니다. 본 연구는 다양한 객체 카테고리에 대한 zero-shot 일반화 가능성을 확인했으며, 비디오 생성 기술과 물리 시뮬레이션 간의 간극을 효과적으로 좁혔다는 평가를 받습니다. 이러한 접근 방식은 향후 로봇 조작 학습 및 가상 에이전트 제어 분야에서 데이터 효율적인 강화학습 프레임워크로서 중요한 이정표가 될 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] InterPrior: Scaling Generative Control for Physics-Based Human-Object Interactions
- [논문리뷰] DexNDM: Closing the Reality Gap for Dexterous In-Hand Rotation via Joint-Wise Neural Dynamics Model
- [논문리뷰] HERMES: Human-to-Robot Embodied Learning from Multi-Source Motion Data for Mobile Dexterous Manipulation
- [논문리뷰] Where, What, Why, and Importance: Structured Defect Grounding for Text-to-Image Feedback
- [논문리뷰] N-GRPO: Embedding-Level Neighbor Mixing for Enhanced Policy Optimization
Review 의 다른글
- 이전글 [논문리뷰] DR-Venus: Towards Frontier Edge-Scale Deep Research Agents with Only 10K Open Data
- 현재글 : [논문리뷰] DeVI: Physics-based Dexterous Human-Object Interaction via Synthetic Video Imitation
- 다음글 [논문리뷰] Diverse Dictionary Learning
댓글