[논문리뷰] Diverse Dictionary Learning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yujia Zheng, Zijian Li, Shunxing Fan, Andrew Gordon Wilson, Kun Zhang
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Diverse Dictionary Learning: 잠재 변수와 관측치 간의 비선형 생성 과정에서, 전체 잠재 변수를 복구하는 대신 집합론적 관계(교집합, 여집합 등)를 통해 부분적으로 구조를 식별하는 새로운 프레임워크입니다.
- Set-theoretic Indeterminacy: 두 모델이 관측 데이터상으로는 동일(Observational equivalence)하더라도 잠재 변수 간에는 특정 집합 연산(Intersection, Complement, Symmetric difference) 수준에서만 정보가 복구 가능한 모호성 상태를 의미합니다.
- Dependency Structure: 생성 모델의 Jacobian 행렬의 비영 패턴(Nonzero pattern)으로 정의되며, 어떤 잠재 변수가 어떤 관측치에 기능적으로 영향을 미치는지 나타내는 비매개변수적 구조입니다.
- Sufficient Nonlinearity: 생성 모델의 Jacobian이 충분한 변동성을 가져, 잠재 변수 간의 기능적 영향력을 선형적으로 독립적인 벡터들로 스캔할 수 있음을 보장하는 가정입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 관측 데이터 $X=g(Z)$로부터 잠재 변수 $Z$를 복구하는 문제에서, 기존의 강한 매개변수적 제약이나 보조 정보 없이도 식별 가능한 부분이 무엇인지 규명하고자 합니다. 기존의 딕셔너리 학습(Dictionary Learning)은 선형성에 의존하거나 강력한 가정을 필요로 하여 복잡한 실제 생성 과정을 반영하지 못하는 한계가 있습니다. 특히 기계적 해석 가능성(Mechanistic Interpretability)에서 널리 쓰이는 Sparse Autoencoders (SAEs)와 같은 방법은 희소한 선형 구조에 국한되어 비선형성이 강한 신경망의 실제 내부 표현을 온전히 설명하지 못한다는 문제가 있습니다. 따라서 저자들은 전역적인 완전 식별(Full identifiability)이 어려운 일반적인 환경에서도, 집합론적 관점을 통해 잠재 과정의 구조를 안전하고 원칙적으로 식별할 수 있는 프레임워크를 제안합니다 [Figure 1].
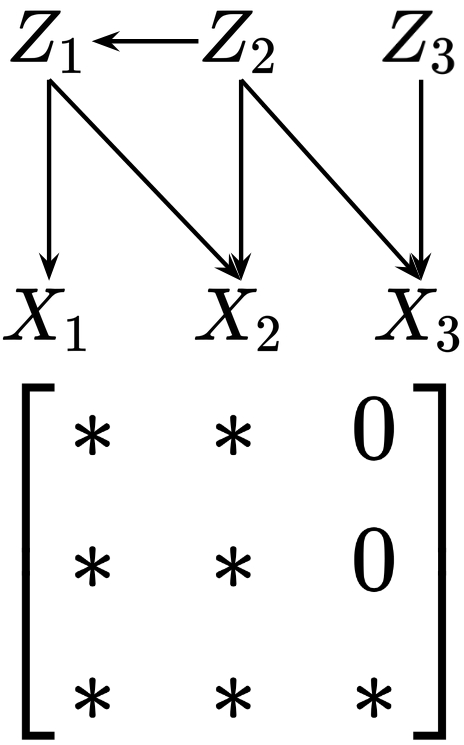
Figure 1 — 잠재-관측 변수 간 구조 예시
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 저자들은 관측치의 부분 집합에 연결된 잠재 변수들의 집합론적 관계(교집합, 여집합, 대칭 차집합)가 모델 간의 모호성을 넘어서 식별 가능함을 이론적으로 증명합니다. 구체적으로, Dependency Sparsity를 학습 목표 함수에 정규화 항($\alpha |D_{\hat{Z}}\hat{g}|_0$)으로 추가하는 단순한 인덕티브 바이어스(Inductive bias)만으로도 이러한 식별력을 얻을 수 있음을 보입니다.
- Quantitative Results: 합성 데이터셋 실험에서 제안된 방식은 이론적으로 도출된 집합론적 disentanglement 조건을 효과적으로 만족시켰으며, 이를 통해 잠재 변수들 간의 결합을 방지함을 확인했습니다 [Figure 4].
- 또한, 다중 변수 쌍 비교를 통해 Sufficient Diversity 가정이 충족될 경우 잠재 변수의 요소 단위(Element-wise) 식별이 가능함을 입증하였으며, MCC (Mean Correlation Coefficient) 지표에서 이를 확인했습니다 [Figure 5].
- 실제 이미지 데이터셋(Cars3D, MPI3D) 기반 실험에서 제안된 Dependency Sparsity는 기존의 잠재 변수 희소성(Latent Sparsity) 정규화보다 FactorVAE score 및 DCI score 지표에서 일관되게 우수한 성능 향상을 보였습니다 [Table 1].
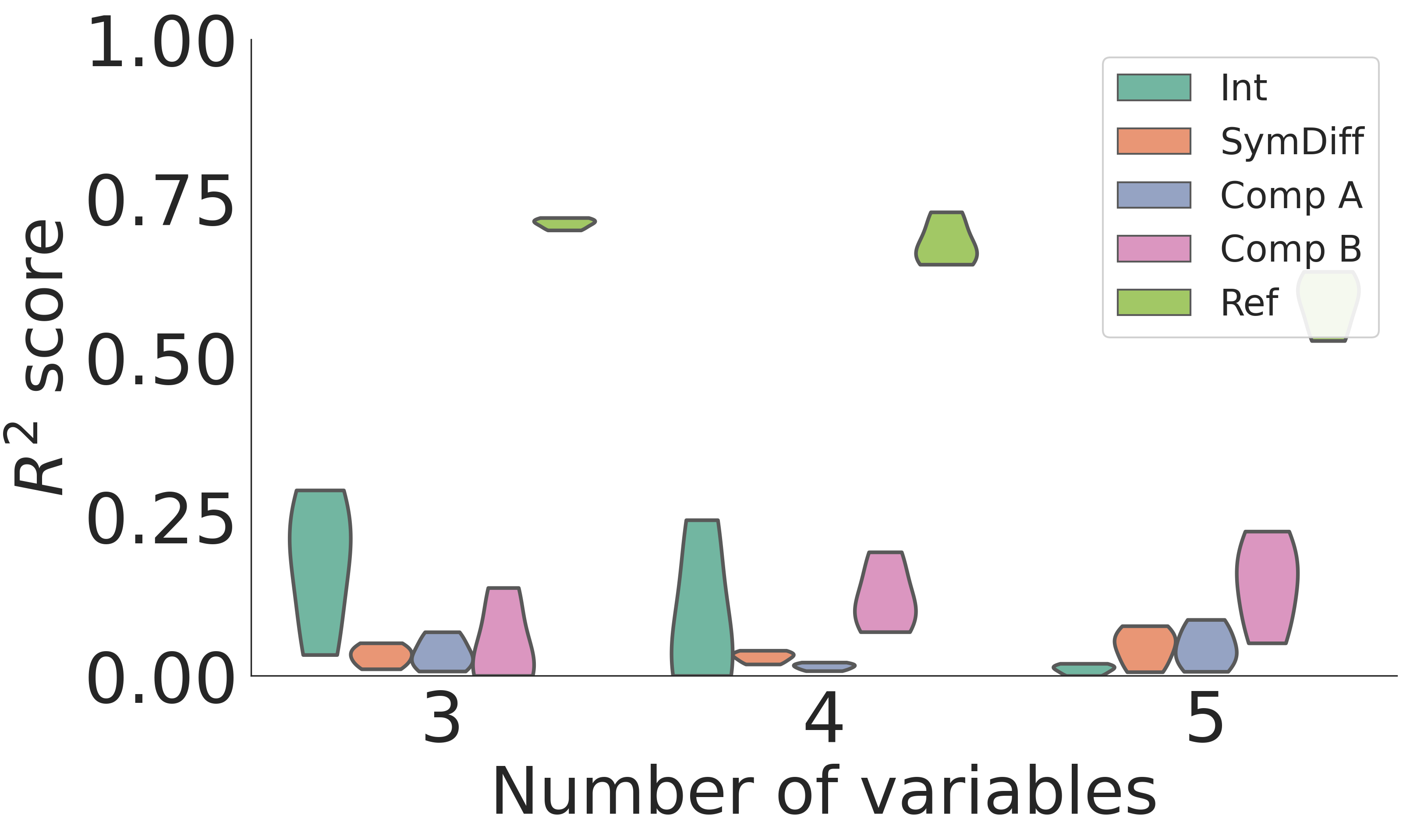
Figure 4 — 합성 데이터의 R^2 점수 분포
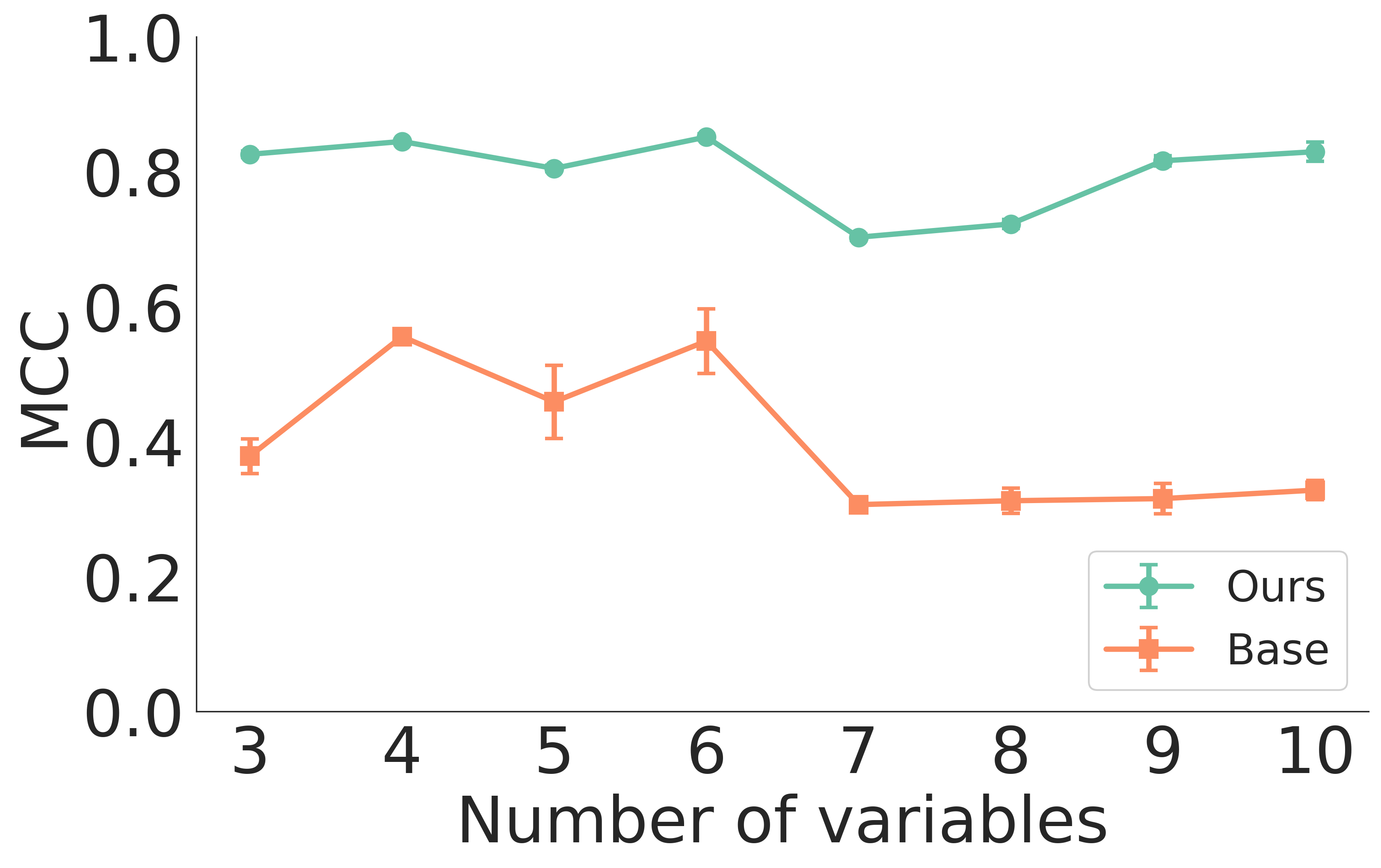
Figure 5 — 합성 데이터의 MCC 성능 비교
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 잠재 변수 식별 문제를 집합론적 연산의 관점으로 재해석하여, 완전한 복구가 불가능한 일반적인 환경에서도 유효한 보장(Guarantee)을 제공하는 이론적 토대를 마련했습니다. 제안된 Dependency Sparsity 정규화는 해석 가능성 도구와 일반 생성 모델에 범용적으로 적용 가능하며, 잠재 변수 수준의 희소성 강제가 갖는 feature absorption 등의 한계를 극복하는 실질적인 대안을 제시합니다. 본 연구는 학계의 식별 가능성 이론과 산업계의 기계적 해석 가능성 연구 사이의 간극을 잇는 중요한 시사점을 제공하며, 향후 거대 모델의 내부 개념 추출을 위한 principled한 접근 방식으로 발전할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Chain of World: World Model Thinking in Latent Motion
- [논문리뷰] Reasoning Palette: Modulating Reasoning via Latent Contextualization for Controllable Exploration for (V)LMs
- [논문리뷰] Thought Communication in Multiagent Collaboration
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] USO: Unified Style and Subject-Driven Generation via Disentangled and Reward Learning
Review 의 다른글
- 이전글 [논문리뷰] DeVI: Physics-based Dexterous Human-Object Interaction via Synthetic Video Imitation
- 현재글 : [논문리뷰] Diverse Dictionary Learning
- 다음글 [논문리뷰] Exploring Spatial Intelligence from a Generative Perspective
댓글