[논문리뷰] N-GRPO: Embedding-Level Neighbor Mixing for Enhanced Policy Optimization
링크: 논문 PDF로 바로 열기
저자: Xukun Zhu, Hang Yu, Peng Di, Linchao Zhu
1. Key Terms & Definitions (핵심 용어 및 정의)
- GRPO (Group Relative Policy Optimization): 대규모 언어 모델의 추론 성능을 향상하기 위해 샘플링된 그룹의 상대적 보상을 활용하는 강화학습 프레임워크입니다.
- Semantic Neighbor Mixing: 모델이 선택한 앵커 토큰의 임베딩과 해당 토큰과 의미적으로 유사한 인근 토큰들의 임베딩을 가중치 합하여 새로운 연속적 표현을 생성하는 기법입니다.
- Semantic Drift: 무분별한 노이즈 삽입 등으로 인해 모델의 표현이 의미적 매니폴드(semantic manifold)에서 벗어나 토큰의 의미가 왜곡되는 현상을 지칭합니다.
- Rollout Phase: 강화학습 과정 중 정책 모델이 환경(혹은 문제)과 상호작용하며 다양한 추론 경로(trajectories)를 생성하는 단계입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 LLM의 강화학습 과정 중 Rollout 단계에서 발생하는 효과적인 탐색(Exploration)의 부족과 기존 방법론의 한계점을 해결하고자 합니다. 기존의 토큰 단위 샘플링은 단순히 문장을 재구성하는 수준의 중복된 경로만 생성하며, 임베딩 공간에 직접 Gaussian 노이즈를 주입하는 방식은 Semantic Drift를 유발하여 의미적 일관성을 해칩니다 [Figure 1]. 이러한 문제로 인해 모델은 의미적으로 다양하면서도 논리적으로 타당한 추론 경로를 탐색하는 데 제약을 겪고 있습니다. 따라서 저자들은 임베딩 공간 내에서 의미적 매니폴드를 유지하면서도 충분한 다양성을 제공하는 새로운 탐색 전략이 필요하다고 판단하였습니다.
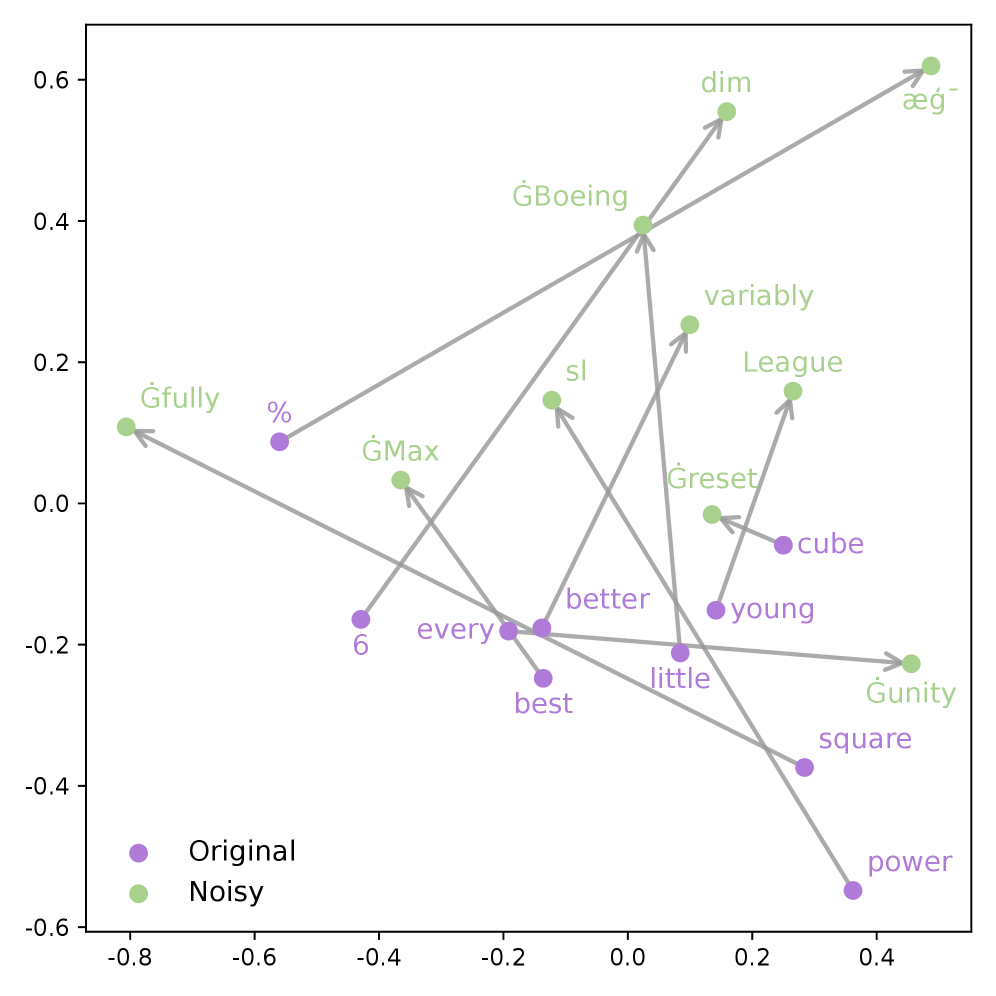
Figure 1 — 무분별한 노이즈에 의한 의미론적 드리프트 시각화
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 N-GRPO를 제안하며, 이는 Semantic Neighbor Mixing을 GRPO 프레임워크의 Rollout 단계에 통합한 새로운 정책 최적화 기법입니다 [Figure 2]. 제안 기법은 먼저 모델이 가장 선호하는 앵커 토큰을 결정한 후, 임베딩 공간에서 코사인 유사도를 기준으로 가장 가까운 이웃 토큰들을 식별합니다. 그 후, 현재 단계의 로짓값을 기반으로 계산된 가중치를 사용하여 이웃 토큰들의 임베딩을 혼합함으로써 의미론적으로 안정적인 연속적 표현을 생성합니다. 또한, 혼합률($\rho$)을 활용한 게이팅 메커니즘을 통해 탐색 과정에서의 안정성을 확보하였습니다. 실험 결과, DeepSeek-R1-Distill-Qwen 모델을 기반으로 평가했을 때, N-GRPO는 수학적 추론 벤치마크(AMC23, AIME25 등)에서 기존 GRPO 및 STHT (Soft Tokens, Hard Truths) 대비 우수한 성능을 입증하였습니다. 특히, 1.5B 규모 모델에서 Pass@32 지표가 79.17%를 기록하며 베이스라인을 크게 상회하였습니다 [Table 1]. 또한, OOD(Out-of-Distribution) 데이터셋인 GPQA-Diamond에서도 안정적인 성능 개선을 보이며 일반화 능력을 입증하였습니다 [Table 2].
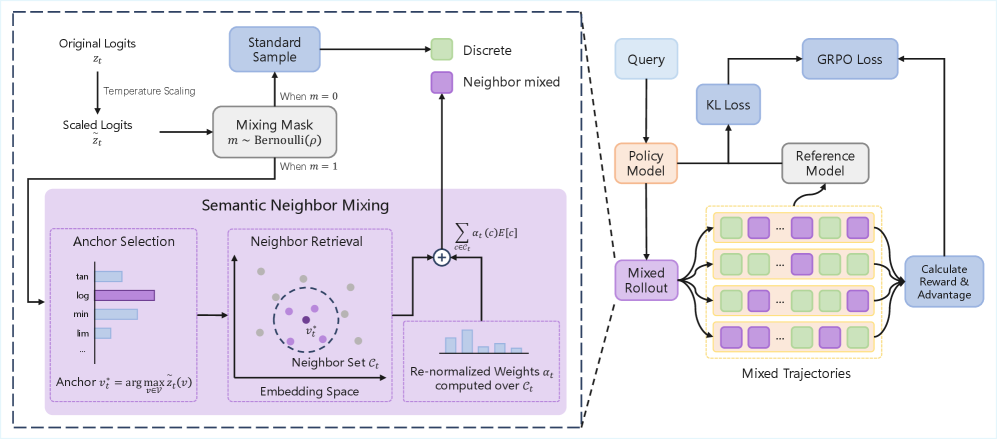
Figure 2 — N-GRPO 프레임워크의 아키텍처 및 믹싱 과정
4. Conclusion & Impact (결론 및 시사점)
본 논문은 연속적인 임베딩 공간에서의 의미적 이웃 혼합을 통해 기존의 불투명하고 비효율적인 탐색 문제를 해결함으로써, LLM의 강화학습 성능을 극대화하는 새로운 이정표를 제시합니다. 제안된 N-GRPO는 토큰 단위의 이산적 탐색을 연속적 임베딩 탐색으로 성공적으로 확장하며, 논리적 추론 경로를 다양화하면서도 의미적 일관성을 유지하는 전략적 우위를 보여줍니다. 향후 본 연구는 복잡한 추론 작업이 요구되는 다양한 도메인으로의 확장 가능성을 시사하며, 특히 모델의 크기와 관계없이 일관된 성능 향상을 보였다는 점에서 학계와 산업계 모두에 중요한 기여를 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] FIPO: Eliciting Deep Reasoning with Future-KL Influenced Policy Optimization
- [논문리뷰] Self-Hinting Language Models Enhance Reinforcement Learning
- [논문리뷰] Reasoning-Aware GRPO using Process Mining
- [논문리뷰] ASPO: Asymmetric Importance Sampling Policy Optimization
- [논문리뷰] Verifiable Rewards Beyond Math and Code: Lightweight Corpus-Grounded Process Supervision for Factual Question Answering
Review 의 다른글
- 이전글 [논문리뷰] MuJoCo-Drones-Gym: A GPU-Accelerated Multi-Drone Simulator for Control and Reinforcement Learning
- 현재글 : [논문리뷰] N-GRPO: Embedding-Level Neighbor Mixing for Enhanced Policy Optimization
- 다음글 [논문리뷰] PianoKontext: Expressive Performance Rendering from Deadpan Context
댓글