[논문리뷰] PianoKontext: Expressive Performance Rendering from Deadpan Context
링크: 논문 PDF로 바로 열기
메타데이터
저자: Dmitrii Gavrilev
1. Key Terms & Definitions (핵심 용어 및 정의)
- Expressive Performance Rendering (EPR): 기계적인 Deadpan 음악 입력을 받아 연주자의 감정과 해석이 담긴 자연스러운 연주 오디오로 변환하는 기술입니다.
- Flow Matching: 노이즈 분포와 데이터 분포 사이를 연속적으로 보간(Interpolation)하는 벡터 필드를 학습하여 데이터를 생성하는 최신 생성 모델링 패러다임입니다.
- Dynamic Time Warping (DTW): 서로 다른 길이와 속도를 가진 두 시계열 데이터(여기서는 score와 performance) 간의 최적의 정렬(alignment)을 찾아내어 쌍을 이루는 데이터를 구축하는 알고리즘입니다.
- Music2Latent: 오디오 신호를 낮은 샘플링 레이트의 압축된 잠재 공간(Latent space) 표현으로 변환하여, 연산 효율성을 극대화하는 사전 학습된 모델입니다.
- DiT (Diffusion Transformer): 트랜스포머 아키텍처를 Diffusion/Flow Matching 모델에 적용하여, 잠재 변수 간의 복잡한 의존성을 효과적으로 모델링하는 구조입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 음악 생성 모델이 표현적 타이밍(Expressive timing)과 다성 음악(Polyphonic music)의 복잡성을 제대로 모델링하지 못하는 문제를 해결하기 위해 PianoKontext를 제안한다. 기존의 오디오 편집 모델들은 동일한 길이를 가진 데이터 간의 변환에 집중하거나, 기호적 도메인(Symbolic domain) 모델링 시 악기 고유의 음향적 특성을 반영하지 못하는 한계가 있다. 또한, 단순히 Deadpan 오디오를 생성하는 모델은 연주자의 미묘한 예술적 해석(예: Grace notes, Trills 등)을 반영하지 못하고 노트를 누락하거나 환각(Hallucination)을 일으키는 문제가 발생한다. 따라서 저자들은 사전 학습된 Music2Latent 공간 내에서 가변 길이의 표현적 연주를 생성할 수 있는 새로운 접근 방식을 제시한다 [Figure 1].
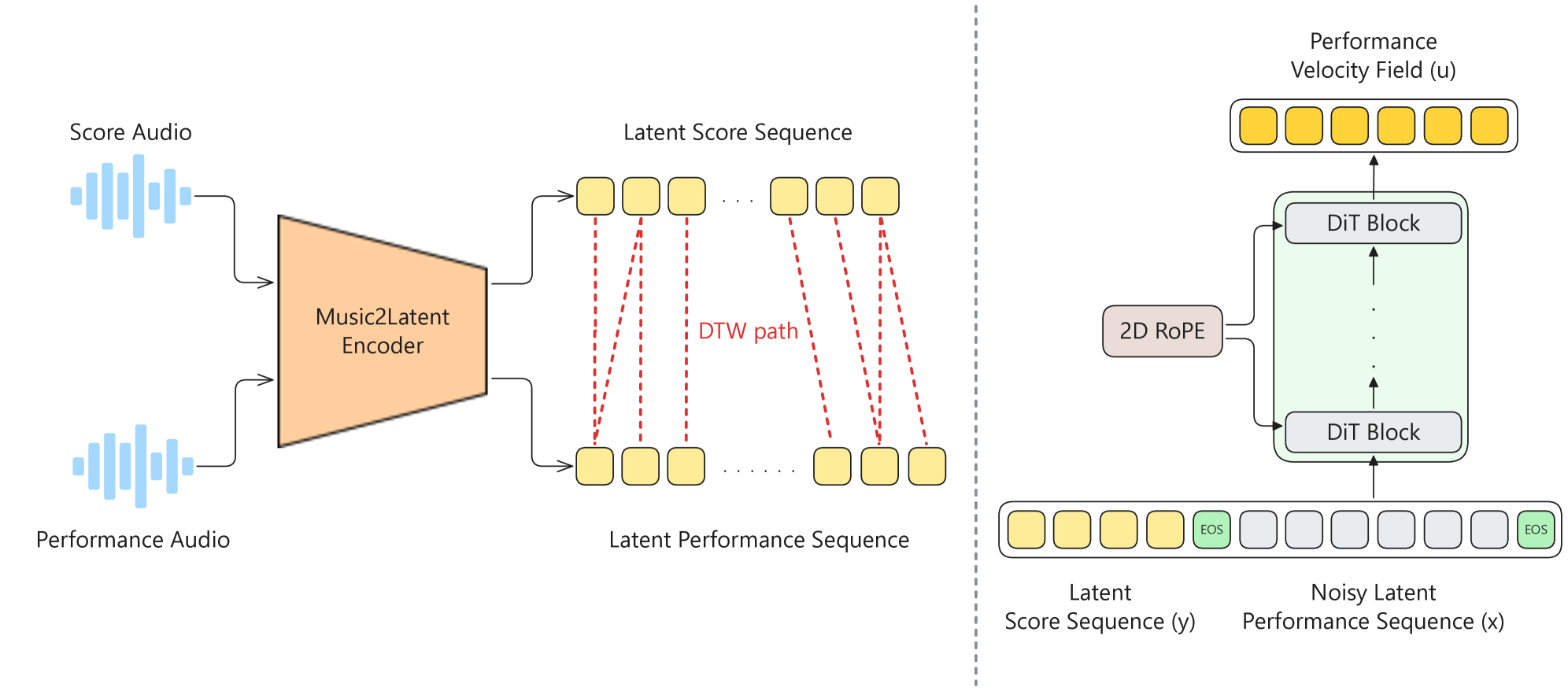
Figure 1 — PianoKontext 전체 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
PianoKontext는 Music2Latent 모델의 잠재 공간 내에서 deadpan context와 타겟 연주 간의 의존성을 학습하는 Flow Matching 기반 프레임워크이다 [Figure 1]. 저자들은 DTW를 활용하여 스코어와 연주 데이터 간의 정렬을 수행하고, 이를 통해 모델이 템포 변화와 관계없이 음악적 내용을 유지하며 가변적인 길이의 연주를 생성하도록 학습시킨다. 입력 데이터는 deadpan 잠재 표현과 노이즈가 섞인 타겟 연주 잠재 표현으로 구성되며, 이를 DiT 블록 내에서 2D RoPE 임베딩을 사용하여 모델링한다 [Figure 1]. 실험 결과, 제안 모델은 기존의 unsupervised baseline인 CFG Bridge 방식 대비 우수한 성능을 보였다. 구체적으로 FAD(2.96 vs 4.69) 및 KAD(0.91 vs 1.68) 지표에서 현저히 낮은 수치를 기록하여 더 높은 오디오 충실도를 입증하였다 [Table 2]. 또한 Pitch DTW(0.888), Alignment Precision(0.630), Alignment Recall(0.666) 등 모든 정량적 지표에서 베이스라인을 압도하며 악보에 대한 충실도가 비약적으로 개선되었음을 증명하였다 [Table 2]. 특히, [Figure 2]와 같이 서로 다른 duration factor를 적용했을 때 의도한 템포에 맞춰 성공적으로 성능이 렌더링됨을 정성적으로 확인하였다.
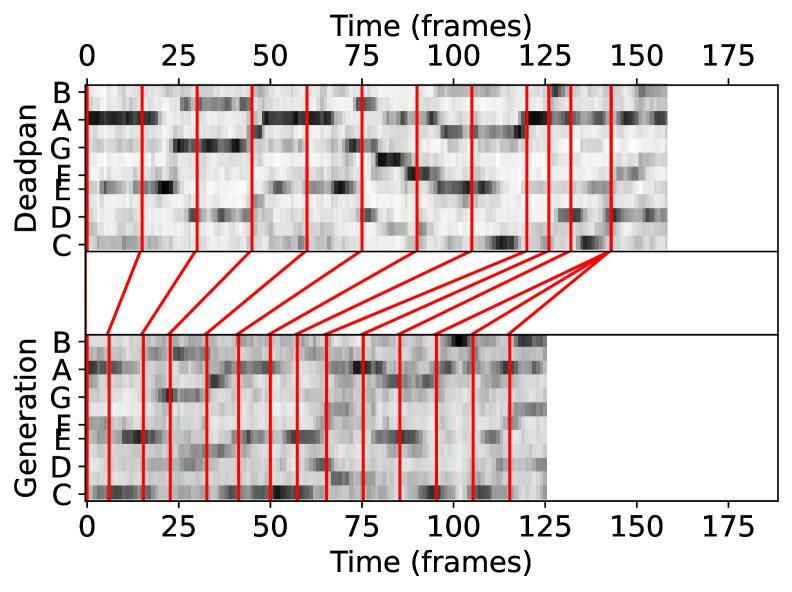
Figure 2 — 다양한 길이의 연주 생성 결과

Table 2 — 평가 지표 비교 결과
4. Conclusion & Impact (결론 및 시사점)
본 논문은 deadpan context로부터 다성 음악의 표현적 연주를 렌더링하는 효과적인 Flow Matching 프레임워크를 성공적으로 구축하였다. 이 연구는 사전 학습된 잠재 공간과 DTW 기반의 정렬 방식을 결합하여, 음악의 구조적 무결성을 유지하면서도 예술적 다양성을 생성할 수 있음을 입증하였다. 향후 연구에서는 타 악기에 대한 확장성과 음악적 표현의 미세한 articulation까지 정교하게 제어하는 기술이 추가적으로 발전할 것으로 기대된다. 이 프레임워크는 고품질 음악 생성 및 자동 반주 시스템 개발 등 음악 AI 산업 분야에 중요한 기술적 이정표가 될 것이다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] High-Fidelity Two-Step Image Generation via Teacher-Aligned End-to-End Distillation
- [논문리뷰] Flow-DPPO: Divergence Proximal Policy Optimization for Flow Matching Models
- [논문리뷰] OASIS: From Simulation Data Collection to Real-World Humanoid Loco-Manipulation
- [논문리뷰] Flash-WAM: Modality-Aware Distillation for World Action Models
- [논문리뷰] Qwen-Image-Flash: Beyond Objective Design
Review 의 다른글
- 이전글 [논문리뷰] N-GRPO: Embedding-Level Neighbor Mixing for Enhanced Policy Optimization
- 현재글 : [논문리뷰] PianoKontext: Expressive Performance Rendering from Deadpan Context
- 다음글 [논문리뷰] Revisiting Articulated Parts Perception in Robot Manipulation
댓글