[논문리뷰] Prompt-Free Universal Region Proposal Network
링크: 논문 PDF로 바로 열기
The content has been browsed. Now I need to process it according to the prompt's requirements.
Part 1: Summary (Markdown)
- Metadata :
- Authors: Qihong Tang, Changhan Liu, Shaofeng Zhang, Wenbin Li, Qi Fan, Yang Gao.
- Keywords: Need to extract 5-8 from the abstract/introduction.
Prompt-Free,Region Proposal Network,Universal Object Detection,Cross-Domain Generalization,Learnable Embedding,Self-Prompting,Centerness-Guided.
- 1. Key Terms & Definitions :
- PF-RPN : Prompt-Free Universal Region Proposal Network.
- SIA : Sparse Image-Aware Adapter.
- CSP : Cascade Self-Prompt module.
- CG-QS : Centerness-Guided Query Selection module.
- OVD : Open-Vocabulary Object Detection.
- 2. Motivation & Problem Statement :
- Existing methods (RPN, OVD) rely on external prompts (exemplar images, predefined categories, textual descriptions), limiting flexibility and adaptability in real-world, open-world scenarios (e.g., industrial defect, underwater detection where prompts are unavailable).
- Prompt-free OVDs often use VLM-based captioners, leading to high latency and memory costs.
- The core problem is to propose potential objects efficiently and universally across diverse unseen domains without external prompts or fine-tuning.
- 3. Method & Key Results :
- Methodology : PF-RPN uses a learnable query embedding.
- SIA module : Dynamically updates the embedding by adaptively integrating
kmost informative multi-level visual features via a Mixture-of-Experts (MoE) router and cross-attention. This captures salient visual details across scales. - CSP module : Iteratively refines the embedding in a deep-to-shallow cascade, using a self-prompting mechanism (masked average pooling with a similarity mask) to identify challenging objects (small, occluded) and suppress background noise.
- CG-QS module : Selects high-quality query embeddings based on a predicted centerness score, prioritizing queries near object centers to reduce false positives and improve proposal quality.
- SIA module : Dynamically updates the embedding by adaptively integrating
- Key Results :
- CD-FSOD benchmark : PF-RPN achieves 60.7 AR@100 , 65.3 AR@300 , 68.2 AR@900 , outperforming Grounding DINO (54.7 AR@100, 57.8 AR@300, 61.6 AR@900) in a prompt-free setting.
- ODinW13 benchmark : PF-RPN achieves 76.5 AR@100 , 78.6 AR@300 , 79.8 AR@900 , surpassing Grounding DINO (69.1 AR@100, 70.9 AR@300, 72.4 AR@900) under the same prompt-free conditions.
- Significantly outperforms MLLMs like Qwen2.5-VL-7B by up to 48.1 AR on CD-FSOD.
- Achieves comparable inference speed to conventional RPNs while outperforming them.
- Methodology : PF-RPN uses a learnable query embedding.
- 4. Conclusion & Impact :
- PF-RPN effectively addresses the limitation of external prompts in universal object proposal by using a learnable embedding and novel modules (SIA, CSP, CG-QS).
- It demonstrates strong zero-shot cross-domain generalization and localization with limited training data (5% COCO, 5% ImageNet).
- The research provides valuable insights for future work in prompt-free, generalized object detection, offering a more flexible and efficient solution for real-world applications where prompts are unavailable.
Part 2: Important Figure Information (JSON)
I need to find up to 3 figures.
- Figure 2 : Overall architecture of PF-RPN. (Looks like a good candidate for the main architecture)
2603.17554v1/x2.png - Figure 1 : Comparison with existing OVD methods. (Conceptual diagram, good for motivation)
2603.17554v1/x1.png - Table 1 : Quantitative results comparing PF-RPN with other models. (Key quantitative results) - The prompt specifically says "Figure/Table" but then "Figure image's
<img>tagsrcattribute". Tables are often HTML, not images. Let's look for another image that shows results or methodology clearly.- Figure 3: Effect of CSP iterations (qualitative result).
2603.17554v1/x3.png - Figure 4: Effect of SIA module (qualitative result).
2603.17554v1/x4.png - Figure 5: Effect of CG-QS module (qualitative result).
2603.17554v1/x5.png - Figure 6: Qualitative results of PF-RPN on various benchmarks (examples of detection).
2603.17554v1/figure/demo.jpg - Figure 7: Prediction box comparison (motivation for CG-QS).
2603.17554v1/x6.png
- Figure 3: Effect of CSP iterations (qualitative result).
Figure 2 is definitely the overall architecture. For the other two, Figure 1 is a good high-level conceptual comparison. Figure 6 shows qualitative results, which is often important. Or Figure 3/4/5 show module effectiveness. Let's choose Figure 2 (architecture), Figure 1 (conceptual overview/motivation), and Figure 6 (qualitative results). I need to get the full URLs for the images.
- Figure 1:
https://arxiv.org/html/2603.17554v1/x1.png - Figure 2:
https://arxiv.org/html/2603.17554v1/x2.png - Figure 6:
https://arxiv.org/html/2603.17554v1/figure/demo.jpg
Now, construct the output. 저자: Qihong Tang, Changhan Liu, Shaofeng Zhang, Wenbin Li, Qi Fan, Yang Gao, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- PF-RPN (Prompt-Free Universal Region Proposal Network) : 외부 프롬프트(exemplar images, textual descriptions) 없이 다양한 도메인에서 잠재적 객체를 식별할 수 있도록 제안된 Region Proposal Network.
- SIA (Sparse Image-Aware Adapter) : Learnable query embedding을 multi-level visual features에 적응적으로 통합하여 초기 객체 localization을 수행하는 모듈.
- CSP (Cascade Self-Prompt) : Learnable embedding을 반복적으로 정제하여 잔여 잠재적 객체를 식별하고, 특히 작거나 가려진 객체에 대한 localization을 개선하는 모듈.
- CG-QS (Centerness-Guided Query Selection) : 객체 중심 근처의 query embedding을 선별하여 high-quality proposal 생성을 유도하는 모듈.
- OVD (Open-Vocabulary Object Detection) : 미리 정의되지 않은 카테고리의 객체도 감지할 수 있는 객체 감지 방법론.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존의 Region Proposal Network (RPN) 및 Open-Vocabulary Object Detection (OVD) 방법들은 잠재적 객체를 식별하기 위해 exemplar images, predefined categories, 또는 textual descriptions과 같은 외부 프롬프트에 의존하는 경향이 있습니다.
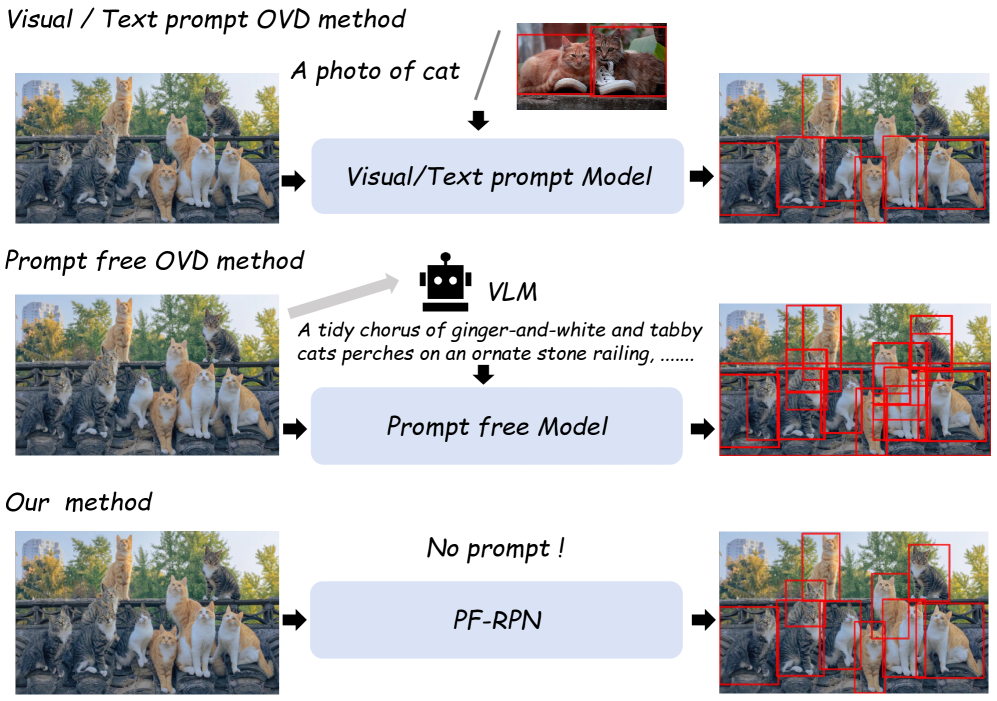
이러한 의존성은 실제 세계의 다양한 시나리오, 예를 들어 산업용 결함 감지나 수중 객체 감지와 같이 프롬프트를 얻기 어려운 환경에서 모델의 유연성과 적응성을 크게 제한합니다. 또한, 일부 prompt-free OVD 모델들은 Generative Vision-Language Models (VLMs)을 활용하여 프롬프트 의존성을 제거하지만, 이 과정에서 상당한 메모리 및 Latency 비용을 발생시키는 한계가 있습니다. 따라서 본 연구의 핵심 문제는 외부 프롬프트나 추가적인 fine-tuning 없이 다양한 unseen domains에서 효율적이고 보편적으로 잠재적 객체를 제안할 수 있는 Region Proposal Network를 개발하는 것입니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 외부 프롬프트 없이 잠재적 객체를 localize하는 novel Prompt-Free Universal Region Proposal Network (PF-RPN) 를 제안합니다. PF-RPN은 learnable embedding을 텍스트 프롬프트의 proxy로 사용하여 작동하며, 세 가지 핵심 모듈로 구성됩니다
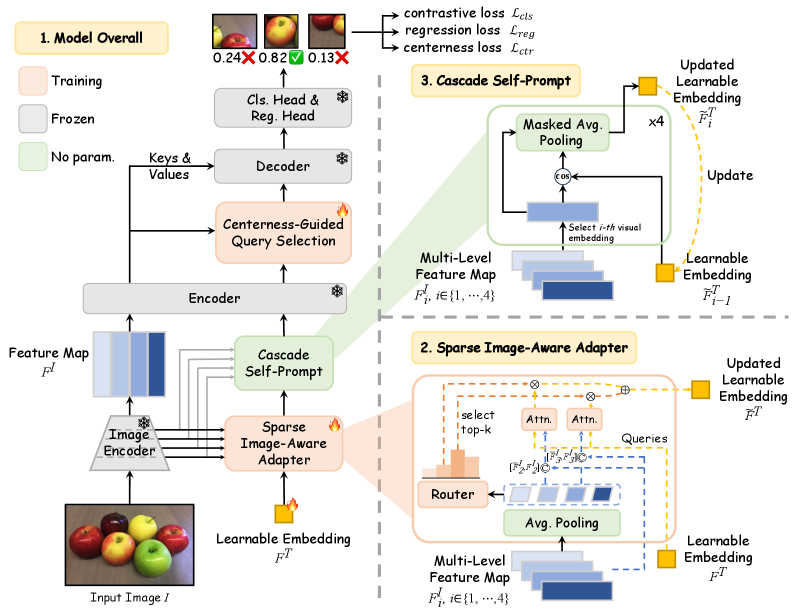
첫째, Sparse Image-Aware Adapter (SIA) 모듈은 Mixture-of-Experts (MoE) 라우팅 메커니즘과 cross-attention을 통해 learnable query embedding을 multi-level visual features에 동적으로 통합하여 초기 객체 localization을 수행합니다. 이는 다양한 공간 해상도에서 중요한 시각적 세부 정보를 포착하여 잠재적 객체 localization을 향상시킵니다 [Figure 4]. 둘째, Cascade Self-Prompt (CSP) 모듈은 SIA가 포착하기 어려운 작거나 가려진 객체를 식별하기 위해 learnable embedding을 iteratively refine합니다. 이는 deep layer에서 shallow layer로 cascading 방식으로 multi-scale visual context를 self-prompting하여, 객체 일관성을 점진적으로 확장하고 배경 노이즈를 억제합니다 [Figure 3]. 셋째, Centerness-Guided Query Selection (CG-QS) 모듈은 객체 중심에 가까운 query embedding이 더 정확한 proposal을 생성한다는 관찰을 바탕으로, centerness scoring network를 사용하여 high-quality query embedding을 선택합니다 [Figure 5, Figure 7]. 이 모듈은 false positives를 줄이고 proposal 품질을 향상시킵니다.
실험 결과, PF-RPN은 다양한 cross-domain 데이터셋에서 강력한 성능을 보여주었습니다. 특히, CD-FSOD 벤치마크에서 Grounding DINO 대비 100/300/900 후보 박스 에서 각각 60.7 AR@100 , 65.3 AR@300 , 68.2 AR@900 의 AR(Average Recall) 향상을 달성했습니다. ODinW13 벤치마크에서는 Grounding DINO 대비 각각 76.5 AR@100 , 78.6 AR@300 , 79.8 AR@900 의 AR 개선을 이루었습니다. 이는 기존 SOTA(State-Of-The-Art) 모델들을 크게 능가하는 수치입니다. 또한, 제한된 데이터(예: MS COCO 데이터의 5% )로 학습되었음에도 불구하고, PF-RPN은 강력한 zero-shot generalization 능력을 입증했습니다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 외부 프롬프트에 의존하지 않고 임의의 잠재적 객체를 제안하는 Prompt-Free Universal Region Proposal Network (PF-RPN) 를 성공적으로 제안했습니다. PF-RPN은 learnable embedding을 텍스트 프롬프트의 대리자로 활용하며, Sparse Image-Aware Adapter (SIA) , Cascade Self-Prompt (CSP) , 그리고 Centerness-Guided Query Selection (CG-QS) 모듈을 통해 모델의 localization 능력과 proposal 품질을 크게 향상시켰습니다. 광범위한 실험 결과는 PF-RPN의 zero-shot cross-domain 객체 제안에서의 우수성을 입증하며,

해당 분야의 미래 연구에 귀중한 통찰을 제공합니다. 이 연구는 실제 환경에서 프롬프트가 제한되거나 불가능한 시나리오에 대한 더욱 유연하고 효율적인 객체 감지 솔루션의 가능성을 열어줍니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Cross-Domain Generalization Failure in Lightweight Intrusion Detection Models for IIoT Networks
- [논문리뷰] Q-Zoom: Query-Aware Adaptive Perception for Efficient Multimodal Large Language Models
- [논문리뷰] Specificity-aware reinforcement learning for fine-grained open-world classification
- [논문리뷰] Paying Less Generalization Tax: A Cross-Domain Generalization Study of RL Training for LLM Agents
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
Review 의 다른글
- 이전글 [논문리뷰] ProRL Agent: Rollout-as-a-Service for RL Training of Multi-Turn LLM Agents
- 현재글 : [논문리뷰] Prompt-Free Universal Region Proposal Network
- 다음글 [논문리뷰] Reasoning over mathematical objects: on-policy reward modeling and test time aggregation
댓글