[논문리뷰] Explainable Disentangled Representation Learning for Generalizable Authorship Attribution in the Era of Generative AI
링크: 논문 PDF로 바로 열기
메타데이터
저자: Hieu Man, Van-Cuong Pham, Nghia Trung Ngo, Franck Dernoncourt, Thien Huu Nguyen
1. Key Terms & Definitions (핵심 용어 및 정의)
- Content-Style Entanglement: 저자의 고유한 문체(Style)와 텍스트의 주제(Content)가 혼재되어 모델이 주제를 저자의 스타일로 오인하는 문제.
- EAVAE (Explainable Authorship Variational Autoencoder): 본 논문에서 제안하는, VAE 기반의 구조적 분리를 통해 스타일과 콘텐츠를 명시적으로 분리하고 설명 가능한 판별기를 결합한 프레임워크.
- Explainable Discriminator: 스타일 및 콘텐츠 표현 쌍의 동일성 여부를 판별함과 동시에, 왜 그러한 판별을 내렸는지에 대한 자연어 설명을 생성하는 구성 요소.
- Hybrid Prompting: 고정된 템플릿과 학습 가능한 소프트 프롬프트를 결합하여, 하나의 제너레이터가 재구성(Reconstruction)과 판별(Discrimination)이라는 두 가지 작업을 효율적으로 수행하게 하는 기법.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 Authorship Attribution(AA)과 AI-generated text detection에서 발생하는 콘텐츠와 스타일의 혼재(Content-Style Entanglement) 문제를 해결하고자 한다. 기존의 많은 모델은 단일 인코더 기반의 contrastive learning을 사용하여 스타일과 주제를 불명확하게 결합함으로써, 서로 다른 주제의 동일 저자 텍스트를 인식하거나 다른 저자의 유사 주제 텍스트를 구분하는 데 한계를 보인다. 이러한 주제 혼동(topic confusion)은 모델의 도메인 간 일반화 성능을 저해하고, 결과에 대한 해석 가능성(interpretability)을 제공하지 못한다는 단점이 있다 [Figure 1]. 따라서 저자들은 스타일과 콘텐츠를 구조적으로 분리하여 더 견고하고 해석 가능한 표현을 학습할 필요성을 제기한다.
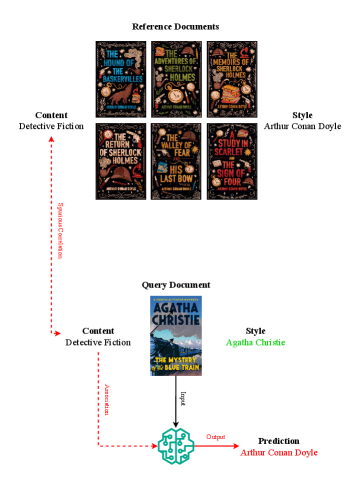
Figure 1 — 콘텐츠-스타일 혼재 예시
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 EAVAE라는 2단계 학습 프레임워크를 제안한다. 첫 번째 단계에서는 대규모 authorship 데이터에 대해 supervised contrastive learning을 수행하여 기초적인 저자 스타일 표현을 사전 학습한다. 두 번째 단계에서는 VAE 구조를 적용하여 스타일과 콘텐츠를 각각 분리된 인코더($E_s, E_c$)를 통해 표현하도록 설계하였다 [Figure 2]. 또한, Hybrid Prompting 메커니즘을 적용한 단일 제너레이터를 도입하여, 재구성 손실뿐만 아니라 스타일 및 콘텐츠 일관성을 판별하고 자연어 설명을 생성하는 Explainable Discriminator를 통해 disentanglement를 강제한다 [Figure 3].
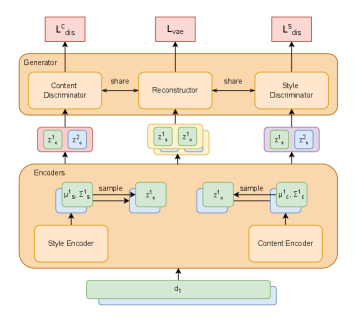
Figure 2 — EAVAE 전체 아키텍처
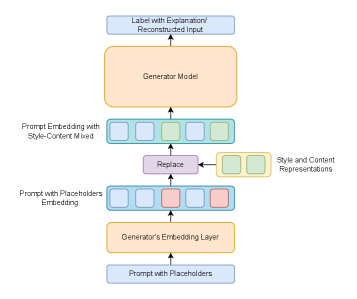
Figure 3 — 하이브리드 프롬프트 제너레이터
실험 결과, EAVAE는 Amazon Reviews 데이터셋에서 97.0% MRR을 기록하며 기존 최고 성능 모델 대비 우수한 결과를 보였다. 특히 HRS 데이터셋(도메인 간 주제 다양성이 높은 벤치마크)에서는 기존 방식 대비 MRR이 약 10.7%포인트 향상되는 등, 고도로 견고한 일반화 성능을 입증하였다. 추가로 AI-generated text detection(M4 벤치마크)에서도 단일 및 다중 타겟 탐지 시나리오에서 일관되게 높은 pAUC 성능을 기록하며, 태스크 특화 학습 없이도 뛰어난 범용성을 보였다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 구조적 disentanglement와 설명 가능한 판별기 결합을 통해 authorship attribution의 근본적인 한계인 콘텐츠 혼동 문제를 성공적으로 해결하였다. EAVAE는 높은 정량적 성능뿐만 아니라 해석 가능한 근거를 제공함으로써 해당 분야의 신뢰성을 크게 향상시켰다. 이 연구는 AI 기반의 텍스트 분석 및 위변조 탐지 영역에서 스타일 모델링의 새로운 표준을 제시하며, 향후 다국어 설정이나 복합적인 스타일 차원 분석 등 범용적 언어 이해 모델로 확장될 수 있는 중요한 시사점을 제공한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] The Principles of Diffusion Models
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] From Black Box to Transparency: Enhancing Automated Interpreting Assessment with Explainable AI in College Classrooms
- [논문리뷰] Score-Control for Hallucination Reduction in Diffusion Models
- [논문리뷰] Seedance 2.0: Advancing Video Generation for World Complexity
Review 의 다른글
- 이전글 [논문리뷰] Encoder-Free Human Motion Understanding via Structured Motion Descriptions
- 현재글 : [논문리뷰] Explainable Disentangled Representation Learning for Generalizable Authorship Attribution in the Era of Generative AI
- 다음글 [논문리뷰] Hybrid Policy Distillation for LLMs
댓글