[논문리뷰] Training Large Language Models to Predict Clinical Events
링크: 논문 PDF로 바로 열기
메타데이터
저자: Benjamin Turtel, Paul Wilczewski, Kris Skotheim
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Foresight Learning: 과거의 시점까지의 데이터(Context)를 기반으로 미래의 결과(Label)를 예측하도록 모델을 학습시키는 프레임워크로, 미래의 결과가 데이터 레이블 역할을 수행함.
- EHR (Electronic Health Records): 환자의 진단, 처방, 검사 결과, 의사의 임상 기록 등을 포함하는 전자 의료 기록으로, 본 논문에서는 비정형 임상 노트를 주로 활용함.
- LoRA (Low-Rank Adaptation): 대규모 언어 모델의 전체 파라미터를 파인튜닝하지 않고, 일부 작은 행렬(Rank-decomposition matrices)만을 학습시켜 효율적으로 모델을 도메인 특화시키는 기법.
- Clinical Event Prediction: 환자의 입원 기간 동안 발생할 수 있는 특정 임상 사건(예: 투약, 시술, 사망 등)의 발생 가능성을 확률적으로 예측하는 과제.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 임상 데이터 내의 풍부한 시계열적 신호를 활용하여 미래의 환자 상태를 효과적으로 예측하는 데 초점을 맞춘다. 기존의 임상 예측 모델들은 주로 구조화된 데이터나 정형화된 코드에 의존하며, 풍부한 임상적 통찰이 담긴 비정형 임상 노트(free-text notes)를 효과적으로 활용하지 못하는 한계가 있다 [Figure 1]. 또한, 단순히 다음 사건을 예측하는 수준을 넘어, 임상 현장에서 요구되는 복잡하고 다양한 미래 사건들을 하나의 통합된 모델로 예측할 수 있는 범용적인 프레임워크가 부족하다. 따라서 저자들은 임상 기록을 시계열적 관점에서 해석하고, 미래의 사건을 레이블로 전환하여 학습하는 End-to-End 예측 프레임워크를 제안한다.
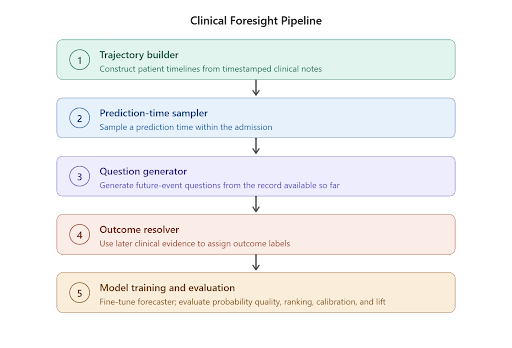
Figure 1 — 임상 예측 파이프라인
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 논문은 MIMIC-III 데이터를 활용하여 임상 노트를 시간 순서대로 재구성하고, 특정 시점의 임상 정보를 입력으로 하여 미래의 임상 사건을 예측하는 Foresight Learning 기반의 학습 방식을 제안한다 [Figure 1]. 저자들은 120B 파라미터의 base 모델인 gpt-oss-120b를 기반으로 LoRA 어댑터를 사용하여 임상 예측 과제에 최적화하였다. 학습 과정에서는 미래의 실제 발생 여부를 이진 레이블로 사용하여 모델의 확률적 예측 성능을 극대화하였으며, 샘플링된 4개의 추론 결과를 바탕으로 log-score를 최적화하였다. 실험 결과, 제안된 모델은 prompted base 모델 대비 ECE를 0.1269에서 0.0398로, Brier score를 0.199에서 0.145로 크게 개선하는 성과를 거두었다 [Table 3]. 또한 AUROC는 0.7993으로 향상되었으며, GPT-5와 비교했을 때도 대등하거나 우수한 성능을 보였다 [Table 3]. 정성적 평가에서도 fine-tuned 모델이 더 정확한 임상적 근거를 바탕으로 높은 성능을 보임을 확인하였다 [Table 4].
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 비정형 임상 기록을 미래 사건 예측을 위한 학습 데이터로 성공적으로 전환함으로써, 별도의 endpoint-specific classifier 없이도 고성능의 임상 예측 모델을 구축할 수 있음을 입증하였다. 이 연구는 대규모 언어 모델이 임상 현장에서 환자의 상태 변화를 실시간으로 추론하고 지원하는 도구로 활용될 수 있는 실질적인 토대를 마련한다. 나아가, 병원 내 축적된 방대한 EHR 데이터를 AI 학습 자산으로 활용하는 경제적이고 확장 가능한 모델링 패러다임을 제시하였다는 점에서 큰 학계 및 산업적 의의를 갖는다.
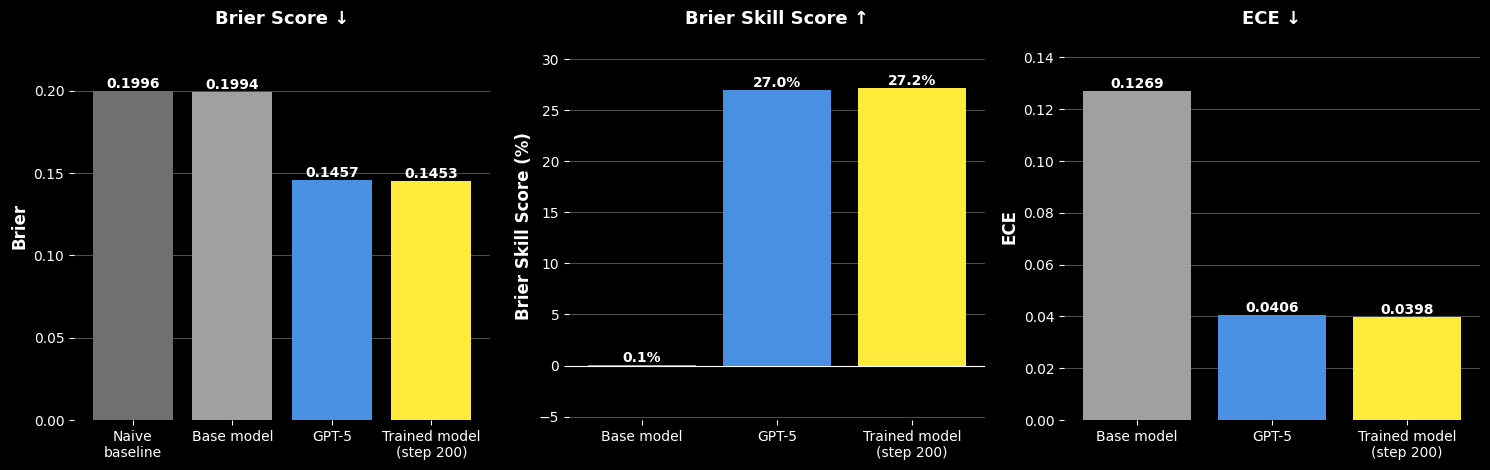
Figure 2 — 모델별 성능 비교
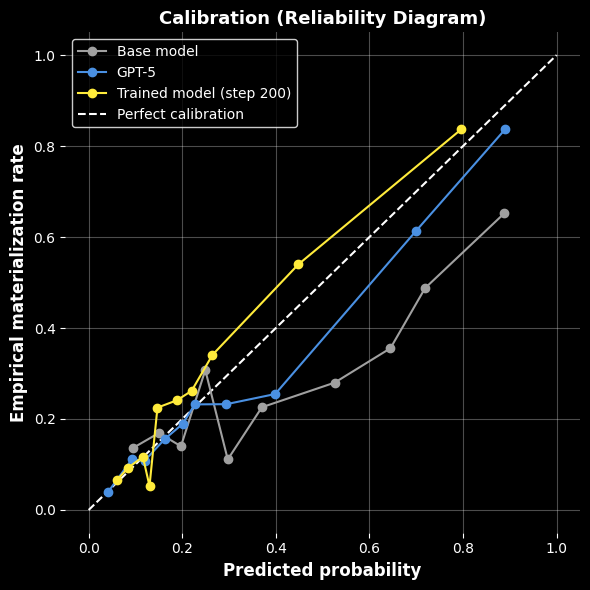
Figure 3 — 신뢰성 도표
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Encoder-Free Human Motion Understanding via Structured Motion Descriptions
- [논문리뷰] The Path Not Taken: RLVR Provably Learns Off the Principals
- [논문리뷰] Omni-AVSR: Towards Unified Multimodal Speech Recognition with Large Language Models
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] RecGPT-V3 Technical Report
Review 의 다른글
- 이전글 [논문리뷰] TerminalWorld: Benchmarking Agents on Real-World Terminal Tasks
- 현재글 : [논문리뷰] Training Large Language Models to Predict Clinical Events
- 다음글 [논문리뷰] TransitLM: A Large-Scale Dataset and Benchmark for Map-Free Transit Route Generation
댓글