[논문리뷰] TerminalWorld: Benchmarking Agents on Real-World Terminal Tasks
링크: 논문 PDF로 바로 열기
메타데이터
저자: Zhaoyang Chu, Jiarui Hu, Xingyu Jiang, Pengyu Zou, Han Li, Chao Peng, Peter O'Hearn, Earl T. Barr, Mark Harman, Federica Sarro, He Ye
1. Key Terms & Definitions (핵심 용어 및 정의)
- TerminalWorld:
asciinema에서 수집한 실세계 터미널 녹화 데이터를 활용하여, 실행 가능한 태스크로 자동 변환하는 확장 가능한 데이터 엔진이자 벤치마크 시스템입니다. - TerminalWorld-Verified:
TerminalWorld의 전체 데이터셋 중 저자들이 수동으로 검토하고 실행을 확인하여 생성한 200개의 엄선된 고품질 태스크 서브셋입니다. - Harbor Harness: 에이전트를 독립적인
Docker환경에 배치하고, 실행 추적을 수집하여 태스크 성공 여부를 검증하는 표준화된 평가 프레임워크입니다. - Efficiency Paradox: 터미널 에이전트가 실제 환경에서 더 많은
tokens와turns를 소모하며 탐색하지만, 성능 향상으로 이어지지 않는 비효율적인 현상을 의미합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 수동으로 큐레이션된 터미널 벤치마크가 실세계의 복잡성과 변화를 충분히 반영하지 못하는 한계를 극복하기 위해 제안되었습니다. 기존 연구들은 도메인 전문가들이 제작한 인위적인 퍼즐 위주로 구성되어 있어, 실제 개발 환경에서 발생하는 워크플로우와 괴리가 있다는 문제가 있습니다. 또한, 이러한 방식은 변화하는 터미널 도구와 실무 관행을 따라가기 위한 확장성이 부족합니다. 이에 저자들은 실제 개발자들이 공유한 터미널 기록을 reverse-engineering하여, '구축에 의한 정당성(Authentic by construction)'을 갖춘 확장 가능한 평가 시스템이 필요하다고 주장합니다 [Figure 1].
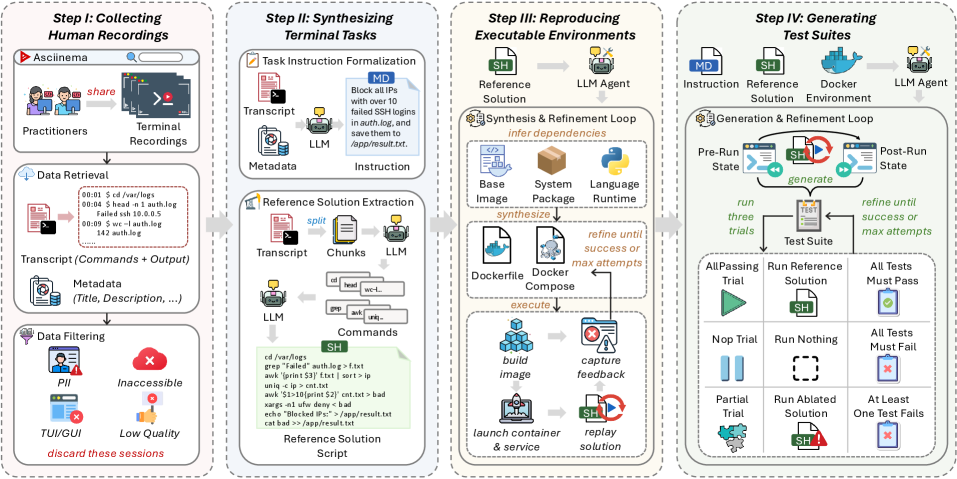
Figure 1 — TerminalWorld 파이프라인 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 asciinema의 80,870개 실세계 터미널 녹화 데이터를 처리하여 1,530개의 검증된 태스크를 생성하는 데이터 엔진을 개발하였습니다. 방법론은 4단계로 구성됩니다: (1) 공개된 녹화 데이터 수집 및 필터링, (2) LLM을 활용하여 의도를 파악하고 참조 솔루션을 추출하는 태스크 합성, (3) Docker 컨테이너를 생성하여 환경을 복제하고 실행 성공을 보장하는 재현 단계, (4) 시도 기반 정제 루프를 통해 Test Suite를 자동 생성하는 단계입니다 [Figure 1]. 실험 결과, 8개 frontier 모델과 6개 에이전트 모두 TerminalWorld-Verified에서 최고 62.5%의 Pass Rate를 기록하는 데 그쳐, 실세계 터미널 작업이 여전히 큰 도전 과제임을 증명했습니다 [Table 1]. 또한, 기존 Terminal-Bench와 TerminalWorld-Verified 점수 간의 상관관계는 Pearson r=0.20에 불과하여, 기존 벤치마크가 실세계 성능을 충분히 예측하지 못함을 입증했습니다 [Figure 4].
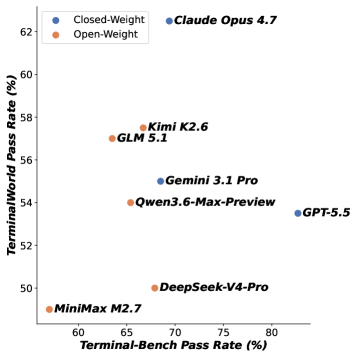
Figure 4 — Terminal-Bench와의 점수 상관관계
4. Conclusion & Impact (결론 및 시사점)
본 연구는 터미널 에이전트 평가의 새로운 패러다임으로, 실제 인간의 터미널 사용 데이터를 기반으로 하는 확장 가능한 자동화 벤치마크 시스템을 제시합니다. TerminalWorld는 정적인 벤치마크에서 벗어나 실제 개발 환경의 변화를 능동적으로 반영할 수 있는 구조를 갖추고 있습니다. 이 연구는 에이전트 개발자들이 단순한 오케스트레이션 복잡성 증대보다는 탐색 효율성 제고와 실세계 워크플로우 적응에 집중해야 함을 시사하며, 학계와 산업계가 보다 신뢰할 수 있는 터미널 에이전트를 구축하는 데 기여할 것으로 기대됩니다.
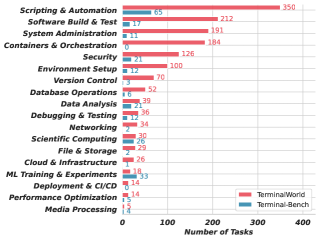
Figure 2 — 태스크 통계 비교 분석
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] OSWorld2.0: Benchmarking Computer Use Agents on Long-Horizon Real-World Tasks
- [논문리뷰] AutoMedBench: Towards Medical AutoResearch with Agentic AI Models
- [논문리뷰] Agent-ValueBench: A Comprehensive Benchmark for Evaluating Agent Values
- [논문리뷰] Claw-Eval: Toward Trustworthy Evaluation of Autonomous Agents
- [논문리뷰] LongCLI-Bench: A Preliminary Benchmark and Study for Long-horizon Agentic Programming in Command-Line Interfaces
Review 의 다른글
- 이전글 [논문리뷰] Swift Sampling: Selecting Temporal Surprises via Taylor Series
- 현재글 : [논문리뷰] TerminalWorld: Benchmarking Agents on Real-World Terminal Tasks
- 다음글 [논문리뷰] Training Large Language Models to Predict Clinical Events
댓글