[논문리뷰] Swift Sampling: Selecting Temporal Surprises via Taylor Series
링크: 논문 PDF로 바로 열기
저자: Dahye Kim, Bhuvan Sachdeva, Karan Uppal, Naman Gupta, Vineeth N. Balasubramanian, Deepti Ghadiyaram
1. Key Terms & Definitions (핵심 용어 및 정의)
- Swift Sampling: 비디오의 latent feature trajectory 상에서 Taylor series를 이용하여 정보 밀도가 높은 지점인 'Temporal Surprise'를 식별하고 샘플링하는 training-free 프레임 선택 알고리즘.
- Taylor Residual: 관측된 비디오 프레임의 feature와 이전 프레임들에 기반한 Taylor predictor의 예측값 사이의 $l_2$ 거리를 나타내며, 해당 프레임의 정보 가치(Informativeness)를 측정하는 척도.
- Temporal Surprise: 비디오 내에서 예측 가능한 흐름에서 급격히 벗어나는 순간으로, 시각적 정보가 풍부하고 하위 작업의 성능에 결정적인 영향을 미치는 지점.
- Query-agnostic: 사용자의 질문(Query)을 참조하지 않고 오직 비디오 콘텐츠의 시각적 feature 분석만으로 프레임을 선택하는 방식.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 대부분의 비디오 데이터가 시간적으로 높은 중복성(Temporal Redundancy)을 가진다는 점에 착안하여, 제한된 frame budget 내에서 모델의 성능을 극대화할 수 있는 효율적인 프레임 선택 방식을 제안한다. 기존의 많은 Video Large Language Models(VLMs)은 단순히 일정한 간격으로 프레임을 추출하는 Uniform sampling을 사용하여, 정적인 배경과 핵심적인 사건을 동일하게 처리하는 비효율성을 범하고 있다. 반면, 기존의 고급 샘플링 기법들은 외부 Vision Encoder를 별도로 구동하여 높은 계산 비용(Inference cost)을 초래하거나, 비디오별로 복잡한 Hyperparameter 튜닝이 필요하다는 한계가 있다. 저자들은 인간 뇌의 'Predictive Coding' 원리를 활용하여, 별도의 학습 없이 VLM 내부의 vision encoder만을 활용해 정보 가치가 높은 프레임을 식별하는 Swift Sampling을 도입하였다 [Figure 1].
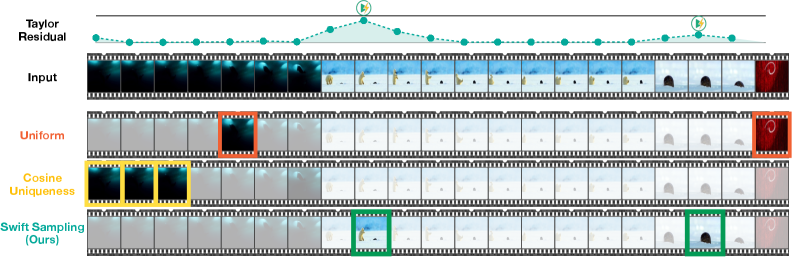
Figure 1 — Swift Sampling의 핵심 개념도
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 비디오의 시각적 latent feature가 locally smooth한 trajectory를 그린다는 가정하에, Taylor series 확장을 통해 미래 프레임을 예측하고 그 잔차(Residual)를 정보의 지표로 사용한다. 구체적으로, 이전 $N$개의 프레임으로부터 속도, 가속도, jerk 등을 파악하여 현재 프레임을 예측하고, 실제 feature와 예측값 사이의 Taylor residual이 큰 지점을 'Temporal Surprise'로 간주하여 Keyframe으로 선정한다 [Figure 2]. 해당 기법은 VLM의 첫 번째 레이어 feature만을 재활용하여 기존 uniform sampling 대비 연산 비용을 0.02x 추가 수준으로 최소화하였다. 실험 결과, Video-MME, LongVideoBench(LVB), MLVU 벤치마크에서 기존의 query-agnostic 및 query-aware 베이스라인을 모두 능가하는 성능을 보였다. 특히, 긴 영상(30분 이상)에 대해 제한된 frame budget(K=4) 상황에서 Uniform sampling 대비 +12.5 포인트의 정확도 향상을 달성하며 매우 강력한 성능 개선을 입증하였다 [Table 1, Table 8(b)]. 또한, UniComp와 같은 토큰 압축 파이프라인에 결합했을 때에도 일관된 정확도 향상을 보이며 그 범용성을 증명하였다 [Table 3].
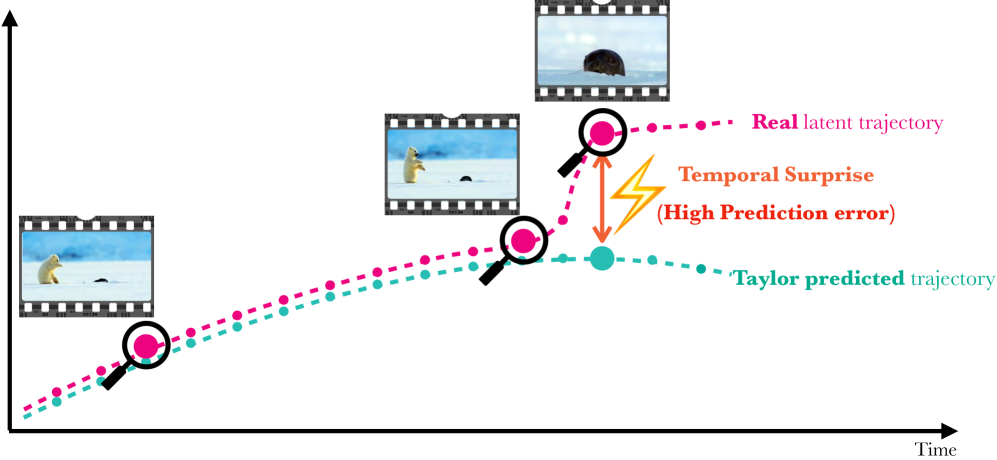
Figure 2 — Taylor 예측 및 잔차 계산 방식
4. Conclusion & Impact (결론 및 시사점)
본 논문은 인간의 인지 원리를 모방한 Taylor residual 기반의 프레임 선택 프레임워크인 Swift Sampling을 통해, 긴 비디오 이해의 효율성과 정확도를 동시에 달성하였다. 별도의 외부 학습이나 복잡한 튜닝이 필요 없는 Training-free 특성과 극도로 낮은 연산 오버헤드는 이 기법이 실제 상용 VLM 시스템에 즉각적으로 도입될 수 있는 뛰어난 실용성을 갖추었음을 시사한다. 이 연구는 비디오 모델의 효율적인 컨텍스트 활용을 위한 새로운 방향성을 제시하며, 향후 토큰화 기술 및 다중 모달리티 결합 연구의 핵심적인 전처리 기술로 활용될 것으로 기대된다.

Figure 3 — 샘플링 기법별 정성적 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] AsySplat: Efficient Asymmetric 3D Gaussian Splatting for Long-Sequence Scene Modeling
- [논문리뷰] Variable-Width Transformers
- [논문리뷰] Skip a Layer or Loop It? Learning Program-of-Layers in LLMs
- [논문리뷰] AdaCodec: A Predictive Visual Code for Video MLLMs
- [논문리뷰] HISA: Efficient Hierarchical Indexing for Fine-Grained Sparse Attention
Review 의 다른글
- 이전글 [논문리뷰] Spreadsheet-RL: Advancing Large Language Model Agents on Realistic Spreadsheet Tasks via Reinforcement Learning
- 현재글 : [논문리뷰] Swift Sampling: Selecting Temporal Surprises via Taylor Series
- 다음글 [논문리뷰] TerminalWorld: Benchmarking Agents on Real-World Terminal Tasks
댓글