[논문리뷰] Skip a Layer or Loop It? Learning Program-of-Layers in LLMs
링크: 논문 PDF로 바로 열기
메타데이터
저자: Ziyue Li, Yang Li, Tianyi Zhou
1. Key Terms & Definitions (핵심 용어 및 정의)
- PoLar (Program-of-Layers): 고정된 순서의 Forward pass 대신, 입력 데이터의 난이도에 따라 pretrained layer를 선택적으로 skip하거나 반복(loop)하여 실행하는 동적 추론 프레임워크입니다.
- MCTS (Monte Carlo Tree Search): 본 논문에서 valid execution program을 탐색하고, 학습 데이터를 수집하기 위해 사용한 탐색 알고리즘입니다. 실시간 추론이 아닌 오프라인 진단 도구로 활용됩니다.
- Segment-based Execution: pretrained 모델의 레이어들을 contiguous한 모듈(세그먼트) 단위로 그룹화하여 skip, keep, 또는 repeat 연산을 적용하는 기법입니다.
- Test-time Scaling: 고정된 모델 파라미터 내에서 더 많은 계산 자원(즉, 더 긴 실행 프로그램)을 투입함으로써 추론 성능을 확장하는 방법론입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 모든 입력에 대해 고정된 depth와 순서로 수행되는 기존 LLM의 정적 추론 방식이 비효율적이며, 모델의 잠재적 추론 능력을 충분히 활용하지 못한다는 점을 지적합니다 [Figure 1]. 저자들은 동일한 입력에 대해 훨씬 짧은 실행으로도 정답을 도출할 수 있거나, 반대로 복잡한 문제에는 추가적인 계산 단계가 필요함을 관찰했습니다. 기존의 Layer Pruning, Early-Exit, 또는 단순 Looped Transformer 방식은 skipping이나 recurrence 중 하나에만 국한되거나, 레이어별로 파편화된 결정을 내려 전체적인 프로그램 구조를 최적화하는 데 한계가 있습니다. 이를 해결하기 위해 저자들은 레이어 실행 구조를 검색하는 대신, 실시간으로 입력에 적합한 실행 프로그램을 예측하는 새로운 프레임워크를 제안합니다 [Figure 2].
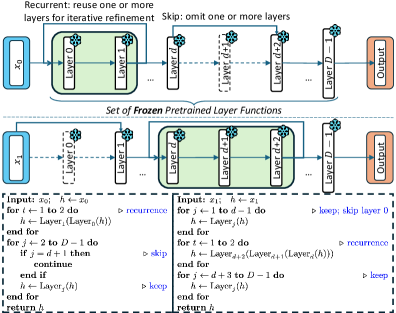
Figure 1 — PoLar 개념도
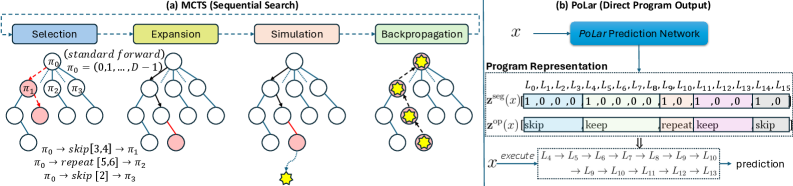
Figure 2 — MCTS 탐색 vs PoLar 네트워크
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 frozen 상태의 모델 레이어를 재사용 가능한 함수 라이브러리로 정의하고, 경량화된 PoLar 예측 네트워크를 통해 입력 맞춤형 실행 프로그램을 생성합니다 [Figure 2]. 제안된 PoLar 네트워크는 입력 데이터를 처리하여 레이어 세그먼트 경계(boundary)와 각 세그먼트에 대한 연산(skip/keep/repeat)을 예측합니다. 실험 결과, PoLar는 DART-Math 벤치마크에서 기존 Base 추론 및 DR.LLM, FlexiDepth 등 기존 dynamic-depth 기법들을 큰 폭으로 능가했습니다 [Table 1]. 특히, Qwen1.5-MoE-A2.7B-Chat 모델을 사용한 OOD(Out-of-Distribution) 평가에서도 MMLU-Pro와 같은 다양한 도메인에서 일관된 성능 향상을 보였습니다 [Table 3]. 정량적으로, PoLar는 표준 추론 대비 연산 효율성을 높이면서도, 더 많은 실행 단계(depth budget)를 할당할 경우 정확도가 단조 증가하는 강력한 Test-time Scaling을 보여줍니다 [Figure 5, Figure 6]. 또한, 제안된 시스템의 추가 오버헤드는 전체 추론 시간의 약 0.8% 수준으로 매우 낮아 실용성이 높음을 입증했습니다 [Table 4].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 고정된 depth를 탈피한 Program-of-Layers가 LLM의 잠재적인 추론 능력을 극대화할 수 있음을 입증했습니다. 제안된 PoLar 프레임워크는 파라미터 수정 없이 추론 시간에 동적으로 레이어 실행 경로를 최적화함으로써 성능과 효율성을 동시에 달성했습니다. 이 연구는 모델의 크기를 키우지 않고도 추론 자원을 유연하게 관리할 수 있는 새로운 이정표를 제시하며, 향후 자원 제약이 있는 환경에서의 Foundation Model 배포 및 운영에 중요한 시사점을 제공합니다.
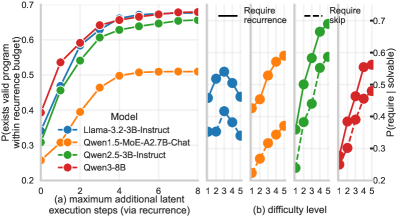
Figure 5 — Test-time scaling과 난이도
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Post-Trained MoE Can Skip Half Experts via Self-Distillation
- [논문리뷰] Reasoning Shift: How Context Silently Shortens LLM Reasoning
- [논문리뷰] Recovered in Translation: Efficient Pipeline for Automated Translation of Benchmarks and Datasets
- [논문리뷰] Latent Collaboration in Multi-Agent Systems
- [논문리뷰] LLM-guided Hierarchical Retrieval
Review 의 다른글
- 이전글 [논문리뷰] RhymeFlow: Training-Free Acceleration for Video Generation with Asynchronous Denoising Flow Scheduling
- 현재글 : [논문리뷰] Skip a Layer or Loop It? Learning Program-of-Layers in LLMs
- 다음글 [논문리뷰] Smaller Models are Natural Explorers for Policy-Level Diversity in GRPO
댓글