[논문리뷰] Smaller Models are Natural Explorers for Policy-Level Diversity in GRPO
링크: 논문 PDF로 바로 열기
저자: Yiming Ren, Yiran Xu, Zicheng Lin, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- GRPO (Group Relative Policy Optimization): 대규모 언어 모델(LLMs)의 추론 능력 향상을 위해 고안된 On-policy 정책-기울기 방법론으로, 명시적인 Critic Network 없이 그룹 내 샘플들의 상대적 비교를 통해 Advantage를 추정한다.
- Token-Level Perturbations: GRPO에서 rollout 다양성을 높이기 위해 개별 토큰 선택에 단계별(step-wise) 무작위성(randomness)을 주입하는 방식으로, 일반적으로 높은 샘플링 Temperature를 사용한다.
- Policy-Level Perturbations: Parameter-level Compression(예: distillation)을 통해 모델의 유도 편향(inductive bias)에 구조적인 변화를 주어 정책 자체를 시간 불변적으로(time-invariant) 변경하는 방식이며, 이를 통해 시공간적으로 일관된 궤적(trajectory) 편차를 유도한다.
- S2L-PO (Small-to-Large Policy Optimization): 작은 모델을 Explorer로 활용하여 큰 모델을 학습시키는 프레임워크로, 작은 모델의 본질적인 Policy-Level Diversity를 활용하여 GRPO 학습의 rollout 다양성과 효율성을 높인다.
- Progressive Annealing Strategy: S2L-PO에서 Exploration과 Exploitation의 균형을 맞추기 위해, 학습 초기에는 작은 모델의 rollouts 비중을 높게 가져가고, 점진적으로 학습이 진행됨에 따라 큰 학습 모델(Learner) 자체의 sampling 비중으로 전환하는 전략이다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 GRPO (Group Relative Policy Optimization) 기반 LLM 학습에서 rollout diversity를 향상시키기 위한 새로운 차원을 식별한다. GRPO는 Diverse한 rollouts에 의존하지만, 기존의 주된 전략들은 주로 token-level randomness를 주입하여 다양성을 증가시켰다. 이러한 token-level perturbation은 단계별 노이즈를 유발하여 불일치한 궤적(incoherent trajectories)을 생성하고, 이는 학습 불안정성과 추론 성능 저하로 이어질 수 있었다. 특히, 장기 추론(long-horizon reasoning) 체인에서는 작은 편차가 누적되어 일관된 논리 흐름을 유지하기 어렵게 만든다. 저자들은 이러한 기존 접근 방식의 한계를 극복하고, 구조화된 탐색 신호(structured exploration signals)를 제공할 수 있는 대안적인 다양성 증진 방법을 모색하고자 한다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 LLM 모델 군(model family) 내에서 작은 모델이 본질적으로 더 높은 Policy-Level Diversity를 보여준다는 점에 주목하며, 이를 GRPO의 rollout 생성 과정에 활용하는 S2L-PO (Small-to-Large Policy Optimization) 프레임워크를 제안한다 [cite: 1, Figure 1]. Policy-Level Perturbations는 Token-Level Perturbations와 달리 시간적으로 일관된(temporally consistent) 궤적 편차를 유도하여, 구조화된 탐색 신호를 제공하고 Gradient Interference를 완화한다 [cite: 1, Figure 3]. S2L-PO는 학습 가능한 큰 모델을 훈련하기 위해 고정된 작은 모델을 Explorer로 활용하여 diverse rollouts를 생성한다 [cite: 1, Figure 1]. Exploration과 Exploitation의 균형을 맞추기 위해, 학습 초기에 작은 모델의 rollouts 비중을 높게 가져가고, 점진적으로 큰 학습 모델의 sampling 비중으로 전환하는 Progressive Annealing Strategy를 사용한다 [cite: 1, Figure 1]. 이 전략은 작은 모델의 능력 한계로 인한 학습 중반의 성능 저하를 방지하며, 더 빠른 수렴과 높은 성능 상한선(performance ceiling)을 달성한다 [cite: 1, Figure 4].
실험 결과, S2L-PO는 Qwen3 및 InternLM2.5 모델 군에 걸쳐 AIME24, AIME25, MATH-500, OlympiadBench 등 4가지 수학적 추론 벤치마크에서 표준 GRPO 대비 일관된 성능 향상을 보였다 [cite: 1, Table 1]. 예를 들어, Qwen3-8B-Base 모델 설정에서 1.7B explorer를 사용한 S2L-PO는 AIME24에서 GRPO baseline 대비 +8.8%의 Pass@1 성능 향상을 달성했으며, AIME25에서는 +10.4% 향상을 보였다 [cite: 1, Table 1]. 또한, S2L-PO는 rollout compute를 줄이면서도 수렴 속도를 향상시켰다 [cite: 1, Figure 4]. Diversity Analysis 결과, 작은 모델은 큰 모델보다 Self-BLEU가 낮고 Edit Diversity 및 Unique Answer Ratio가 높아 Genuine Strategy-Level Diversity를 가짐이 확인되었다 [cite: 1, Table 3]. Off-policy rollouts의 순수 작은 모델 사용은 초기에는 성능 향상을 보이나, Distribution Shift가 커짐에 따라 성능이 정체되거나 감소하는 반면, Progressive Annealing은 안정적이고 지속적인 성능 향상을 유도했다 [cite: 1, Figure 5, Figure 6, Figure 7].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 GRPO 프레임워크에서 작은 모델의 Policy-Level Diversity를 활용하는 S2L-PO를 제안한다. Parameter-Level Compression을 통해 얻은 작은 모델들이 Token-Level Randomness보다 더 일관되고 구조화된 탐색 신호를 제공하며, 이는 GRPO 학습 신호의 질을 향상시킨다는 경험적 및 이론적 증거를 제시한다 [cite: 1, Figure 3]. S2L-PO는 Progressive Annealing Strategy를 통해 Exploration과 Exploitation의 균형을 성공적으로 달성하여, 수학적 추론 작업에서 상당한 성능 향상과 함께 Rollout Compute 감소 및 수렴 가속화를 이끌어냈다 [cite: 1, Table 1, Figure 4]. 이 연구는 Parameter-Level Perturbation에서 비롯된 본질적인 다양성을 활용하는 것이 RL 학습을 위한 강력하고 효율적인 전략임을 시사하며, LLM의 추론 능력을 향상시키는 데 있어 새로운 방향을 제시한다.
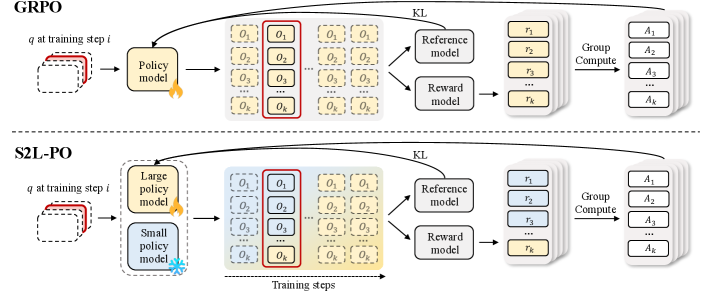
Figure 1 — S2L-PO 프레임워크 개요
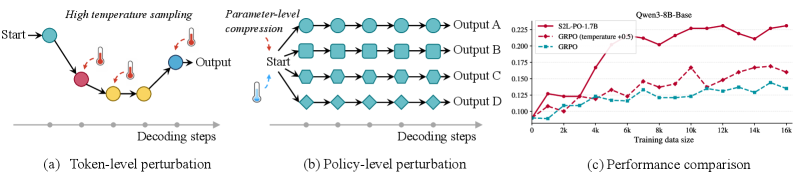
Figure 3 — 다양성 증가 방식 비교
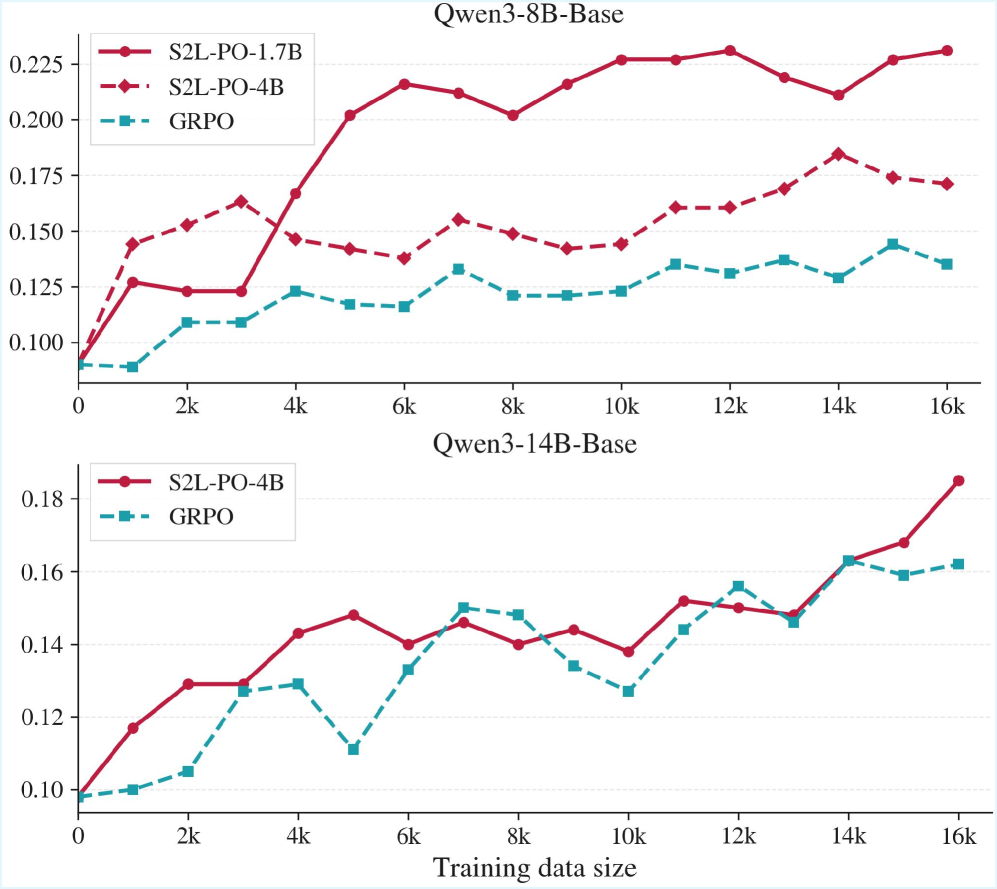
Figure 4 — 성능 및 수렴 속도 개선
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Harder Is Better: Boosting Mathematical Reasoning via Difficulty-Aware GRPO and Multi-Aspect Question Reformulation
- [논문리뷰] TTCS: Test-Time Curriculum Synthesis for Self-Evolving
- [논문리뷰] Robust Tool Use via Fission-GRPO: Learning to Recover from Execution Errors
- [논문리뷰] Aligning Text, Code, and Vision: A Multi-Objective Reinforcement Learning Framework for Text-to-Visualization
- [논문리뷰] PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning
Review 의 다른글
- 이전글 [논문리뷰] Skip a Layer or Loop It? Learning Program-of-Layers in LLMs
- 현재글 : [논문리뷰] Smaller Models are Natural Explorers for Policy-Level Diversity in GRPO
- 다음글 [논문리뷰] Squeeze-Release: Iterative Pruning with Exact Structural Minimization
댓글