[논문리뷰] Squeeze-Release: Iterative Pruning with Exact Structural Minimization
링크: 논문 PDF로 바로 열기
메타데이터
저자: Roman Denkin, Ida Akerholm, Prashant Singh, Ida-Maria Sintorn
1. Key Terms & Definitions (핵심 용어 및 정의)
- Minimization: 마스킹된 네트워크를 동일한 입출력 함수(Forward function)를 유지하면서도 더 작은 밀집(Dense) 네트워크로 변환하는 정밀한 구조적 재작성 기법.
- Squeeze-Release Cycle: Pruning 후 Minimization을 수행하는 'Squeeze' 단계와, 압축 과정에서 제거된 위치를 학습 가능한 파라미터로 복원하는 'Release' 단계를 반복하는 순환 프레임워크.
- CompensatedLayerNorm: LayerNorm의 채널 축소 시 발생하는 통계적 변화를 제거된 채널의 요약 통계량(count, sum, sum-of-squares)을 통해 보정하여 기능을 완벽히 유지하는 모듈.
- Deployable Size: 실제 하드웨어에서 추론(Inference) 시 메모리 점유 및 연산량에 직접적인 영향을 미치는, 구조적으로 축소 가능한 최소 밀집 네트워크의 파라미터 수.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 일반적인 비구조적(Unstructured) Pruning이 파라미터의 중요도에 따라 0으로 만들더라도, 실제 tensor의 물리적 크기를 줄이지 못해 모델 압축 효과가 미비한 문제를 해결하고자 한다. [Figure 1].
기존의 torch.nn.utils.prune과 같은 표준 기법들은 0으로 채워진 마스크를 유지한 채 연산을 수행하므로, 하드웨어 레벨에서의 실질적인 Latency 감소나 메모리 절감을 달성하지 못하는 구조적 한계를 가진다.
따라서, 단순히 파라미터를 제로화하는 것을 넘어, 이를 구조적으로 완전히 제거하고 최적의 Dense 네트워크로 재설계(Structural rewrite)하는 효율적인 압축 프레임워크가 필요하다.
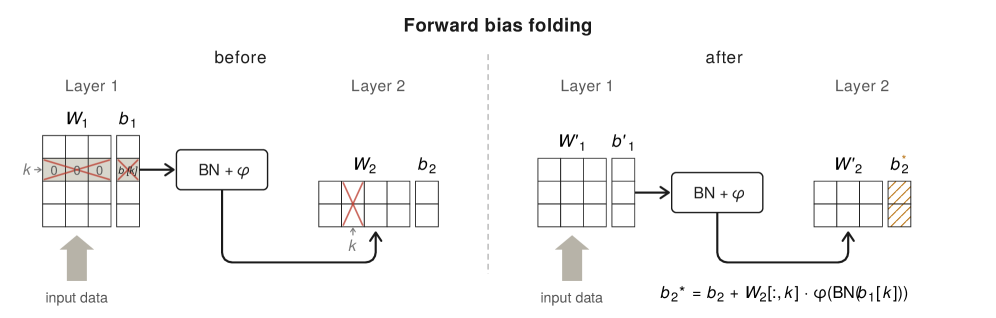
Figure 1 — Dead-incoming 뉴런의 바이어스 폴딩
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 구조적 잉여성을 제거하기 위해 입출력 함수를 보존하는 Minimization 기법을 제안하고, 이를 Squeeze-Release라는 반복적인 순환 프로세스에 적용한다. [Figure 3]. Squeeze 단계에서는 Dead-incoming 및 Dead-outgoing 유닛을 식별하여 구조적으로 제거하며, Release 단계에서는 제거된 위치에 보정된 노이즈를 주입하여 네트워크의 가용 capacity를 재활성화한다. 특히, 현대적 아키텍처인 ConvNeXt의 LayerNorm 계층을 처리하기 위해 CompensatedLayerNorm을 도입하여 채널 제거 후에도 통계적 일관성을 보장한다. [Figure 2]. 실험 결과, Squeeze-Release 기법은 FC 모델에서 unpruned 모델 대비 39배, ConvNeXt-Tiny 모델에서 14.8배 더 작은 Deployable 크기를 달성하며 기존 방식 대비 우수한 압축 성능을 입증하였다. 또한, ViT-Small 아키텍처로의 확장 가능성을 확인하여 광범위한 범용성을 확보하였다.
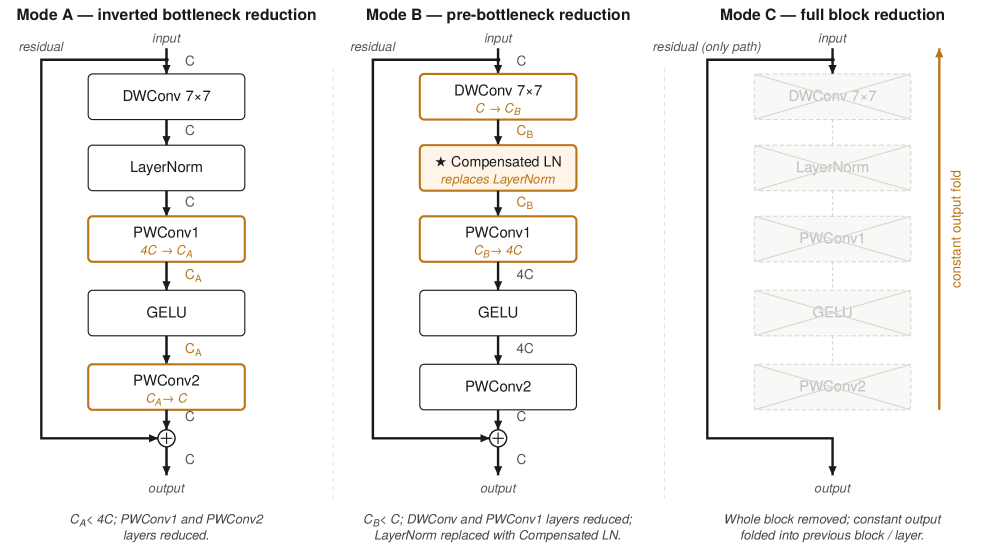
Figure 2 — ConvNeXt 블록의 3단계 Minimization 모드
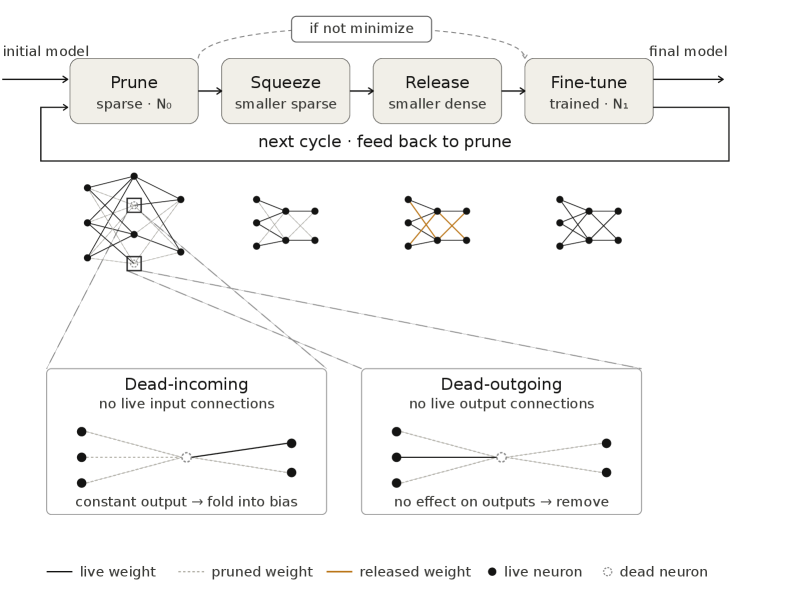
Figure 3 — Squeeze-Release 순환 프로세스
4. Conclusion & Impact (결론 및 시사점)
본 논문은 비구조적 Pruning과 구조적 재작성을 결합한 Squeeze-Release 프레임워크가 실제 추론 환경에서 최적의 성능을 발휘하는 컴팩트한 모델을 생성함을 성공적으로 증명하였다. CompensatedLayerNorm을 통한 Function-preserving 채널 축소는 그동안 구조적 Pruning에서 난제로 여겨졌던 정밀한 아키텍처 재구성을 실현했다는 점에서 학술적 의미가 크다. 이러한 연구 결과는 리소스가 제한된 엣지 디바이스나 실시간 추론이 요구되는 산업 분야에서 LLM 및 Vision Transformer 모델의 실질적인 배포 효율을 극대화하는 데 기여할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] OBS-Diff: Accurate Pruning For Diffusion Models in One-Shot
- [논문리뷰] Moebius: 0.2B Lightweight Image Inpainting Framework with 10B-Level Performance
- [논문리뷰] High-Fidelity Two-Step Image Generation via Teacher-Aligned End-to-End Distillation
- [논문리뷰] Compress-Distill: Reasoning Trace Compression for Efficient Knowledge Distillation
- [논문리뷰] HodgeCover: Higher-Order Topological Coverage Drives Compression of Sparse Mixture-of-Experts
Review 의 다른글
- 이전글 [논문리뷰] Smaller Models are Natural Explorers for Policy-Level Diversity in GRPO
- 현재글 : [논문리뷰] Squeeze-Release: Iterative Pruning with Exact Structural Minimization
- 다음글 [논문리뷰] The Arbiter Agent: Continually Monitoring Multi-Agent Conversations to Detect Emergent Misalignment
댓글