[논문리뷰] RhymeFlow: Training-Free Acceleration for Video Generation with Asynchronous Denoising Flow Scheduling
링크: 논문 PDF로 바로 열기
메타데이터
저자: Chensheng Dai, Shengjun Zhang, Yifan Li, Zhang Zhang, Zheng Zhu, Yueqi Duan
1. Key Terms & Definitions (핵심 용어 및 정의)
- DiTs (Diffusion Transformers): 3D spatiotemporal attention을 활용하여 고품질 비디오를 생성하는 현재 비디오 생성 모델의 지배적인 아키텍처.
- Asynchronous Denoising Flow Scheduling: 모든 프레임을 매 단계마다 동기적으로 업데이트하는 대신, 프레임별 중요도에 따라 비동기적으로 스케줄링하여 연산 효율을 극대화하는 방법론.
- Latent Trajectory Projection: 스킵된 중간 프레임의 잠재 상태를 선형 보간을 통해 추정하여, 키프레임 업데이트 시 전체적인 시간적 일관성을 유지하도록 돕는 모듈.
- Rhythmic Points: 키프레임과 비키프레임의 업데이트가 일치하는 지점으로, 모델이 글로벌 동기화를 수행하여 오류 누적을 방지하는 계산 체크포인트.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 비디오 생성 모델에서 관찰되는 3D spatiotemporal attention의 이차 복잡도로 인한 과도한 Inference Latency 및 계산 비용 문제를 해결하는 것을 목적으로 한다. 기존의 Training-Free 가속 기법들은 대부분 개별 denoising step 내의 연산량을 줄이는 데 집중하고 있으나, 모든 프레임이 모든 Diffusion Timesteps 동안 밀도 높은(dense) denoising 과정을 거쳐야 한다는 구조적 경직성에 갇혀 있다 [Figure 1]. 저자들은 인접 프레임 간의 높은 시공간적 일관성으로 인해 모든 프레임을 동일하게 처리하는 것은 비효율적임을 발견하였으며, 중요도가 높은 Keyframes과 예측 가능한 Non-keyframes을 분리하는 새로운 접근 방식이 필요함을 제기한다.
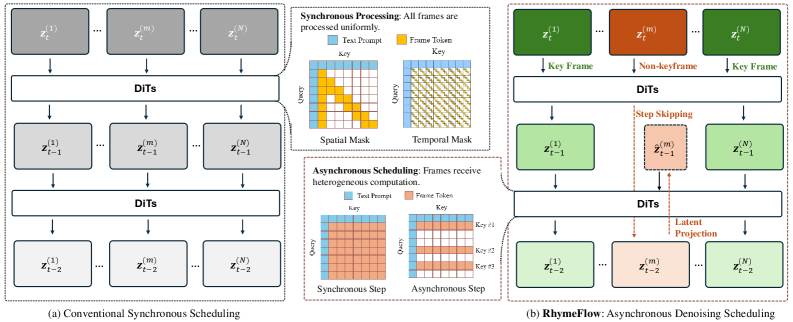
Figure 1 — 기존 동기식 vs 제안 비동기식 스케줄링
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 비디오 생성의 효율성을 극대화하기 위해 프레임의 denoising 경로를 분리하고 각기 다른 스케줄을 적용하는 RhymeFlow 프레임워크를 제안한다. 첫째, Sequential Keyframe Selection을 통해 시각적/의미적 전환점이 되는 핵심 프레임을 식별한다 [Figure 2]. 둘째, Progressive Asynchronous Scheduling을 적용하여, 초기에는 모든 프레임을 동기적으로 처리하여 구조를 확립하고, 이후 단계에서는 Non-keyframes가 denoising step을 건너뛰게 하여 연산 비용을 최소화한다. 셋째, 건너뛴 중간 상태로 인한 시간적 불일치를 방지하기 위해 Latent Trajectory Projection을 수행하여 키프레임이 일관된 시퀀스 정보를 참조할 수 있도록 설계하였다. 실험 결과, RhymeFlow는 Wan 2.1 모델에서 기존 대비 1.53x의 속도 향상을 달성하면서도 PSNR과 SSIM 등에서 높은 생성 품질을 유지하였다 [Table 2]. 특히 CogVideoX-v1.5 환경에서는 최대 1.78x의 가속 성능을 보였으며, 정성적 비교에서도 시각적 결함 없이 복잡한 모션 역학을 성공적으로 보존함을 확인하였다 [Figure 3].
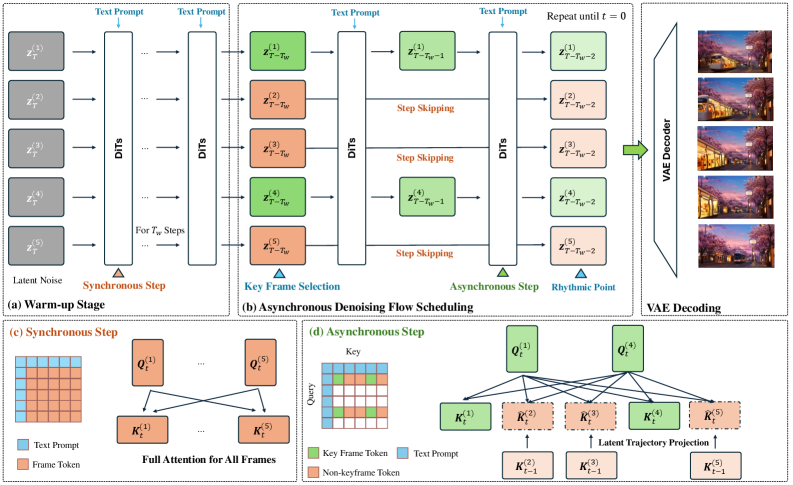
Figure 2 — RhymeFlow 파이프라인 개요

Figure 3 — 정성적 시각 비교 결과
4. Conclusion & Impact (결론 및 시사점)
본 연구는 고정된 밀도 기반의 denoising 패러다임을 탈피하여 콘텐츠 인식 기반의 비동기적 스케줄링을 도입함으로써 비디오 생성 가속화의 새로운 경로를 제시하였다. RhymeFlow는 추가적인 학습이 불필요한 Training-Free 방식으로서 기존의 sparse attention이나 모델 압축 기법과도 상호보완적으로 결합 가능하다는 점에서 학계 및 산업계에 큰 확장성을 제공한다. 향후 연구를 통해 학습 가능한 연속적 스케줄링 함수가 도입된다면 더욱 정교한 효율성 최적화가 가능할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] OmniDirector: General Multi-Shot Camera Cloning without Cross-Paired Data
- [논문리뷰] FadeMem: Distance-Aware Memory Consolidation for Autoregressive Video Diffusion
- [논문리뷰] OSP-Next: Efficient High-Quality Video Generation with Sparse Sequence Parallelism, HiF8 Quantization, and Reinforcement Learning
- [논문리뷰] Flash-GRPO: Efficient Alignment for Video Diffusion via One-Step Policy Optimization
- [논문리뷰] AnyFlow: Any-Step Video Diffusion Model with On-Policy Flow Map Distillation
Review 의 다른글
- 이전글 [논문리뷰] Rethinking RAG in Long Videos: What to Retrieve and How to Use It?
- 현재글 : [논문리뷰] RhymeFlow: Training-Free Acceleration for Video Generation with Asynchronous Denoising Flow Scheduling
- 다음글 [논문리뷰] Skip a Layer or Loop It? Learning Program-of-Layers in LLMs
댓글