[논문리뷰] Rethinking RAG in Long Videos: What to Retrieve and How to Use It?
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yuho Lee, Jisu Shin, Nicole Hee-Yeon Kim, Jihwan Bang, Juntae Lee, Kyuwoong Hwang, Fatih Porikli, Hwanjun Song
1. Key Terms & Definitions (핵심 용어 및 정의)
- VideoRAG: Long-form egocentric video를 대상으로 하는 Retrieval-Augmented Generation으로, 비디오 내 query-relevant evidence chunk를 검색하여 생성 과정의 근거로 활용하는 프레임워크입니다.
- V-RAGBench: Retrieval과 generation 단계를 분리하여 평가할 수 있도록 설계된 벤치마크로, non-recurring evidence, visual grounding, evidence localization 세 가지 속성을 보장하는 2,100개의 triplet 데이터셋입니다.
- CARVE (Chunk-Aware Reranking for Video Evidence): 비디오 chunk의 modality(visual vs. text)와 granularity(frame vs. clip)를 고려하여 chunk 단위로 최적의 configuration을 결정하고 reranking을 수행하는 프레임워크입니다.
- Chunk-Adaptive Reranking: Parallel로 검색된 candidate pool 내의 각 chunk에 대해, 해당 chunk를 가장 잘 설명하는(high-scoring) modality-granularity 조합을 동적으로 선택하는 핵심 메커니즘입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 VideoRAG 시스템이 직면한 평가의 불투명성과 최적의 검색 전략 부재 문제를 해결하고자 합니다. 기존 VideoRAG 연구들은 고정된 modality나 granularity 설정을 사용하며, 전체적인 QA accuracy에만 의존하여 개별 retrieval 성능을 직접적으로 측정하지 못한다는 한계가 있습니다. 특히, 기존 비디오 QA 벤치마크는 비디오 내용 없이도 답변이 가능한 경우가 많아, retrieval의 실패가 생성 결과에 미치는 영향을 파악하기 어렵습니다 [Figure 1]. 이러한 문제를 극복하기 위해 본 연구는 retrieval과 generation 단계의 독립적인 측정이 가능한 전용 벤치마크와 chunk 단위의 유연한 검색 전략이 필요함을 제기합니다.
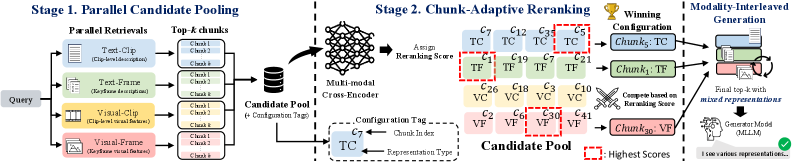
Figure 1 — CARVE 전체 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 CARVE라는 프레임워크를 제안하여, chunk별 content 특성에 맞춰 최적의 representation configuration을 동적으로 할당하고 이를 생성 단계까지 일관되게 전파합니다 [Figure 1]. CARVE는 먼저 4가지 configuration(modality: visual/textual, granularity: frame/clip)을 통해 parallel retrieval을 수행하여 candidate pool을 구축한 뒤, 다중 모달 cross-encoder를 사용하여 각 chunk의 query relevance가 가장 높은 configuration을 결정합니다 [Figure 2]. 주요 실험 결과, CARVE는 V-RAGBench에서 8개의 최신 baseline 대비 Recall@5에서 0.603, nDCG@5에서 0.433을 기록하며 압도적인 성능을 보였습니다. 또한, 생성 단계에서도 Qwen3-VL-8B, Qwen3-VL-32B, Gemma-4-26B 등 다양한 backbone 모델에서 일관되게 가장 높은 pass rate를 달성하며, 별도의 추가 학습 없이도 trained query-level router 모델을 상회하는 범용성을 입증했습니다 [Table 1].
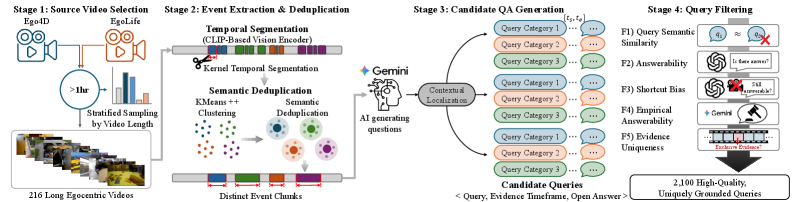
Figure 2 — V-RAGBench 구축 단계
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Long-form egocentric video 환경에서 retrieval과 generation을 정교하게 평가할 수 있는 V-RAGBench를 구축하고, 효율적인 검색 및 생성 통합 프레임워크인 CARVE를 제안했습니다. CARVE가 선보인 chunk-adaptive 방식은 기존의 query-level 결정 방식이 가진 한계를 극복하고, 비디오 데이터가 가진 복합적인 modality 특성을 효과적으로 활용할 수 있음을 보여줍니다. 이 연구는 향후 wearable 디바이스나 agentic system이 방대한 개인 비디오 기록을 이해하고 활용하는 기술 발전에 중요한 토대를 마련할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] HumanScale: Egocentric Human Video Can Outperform Real-Robot Data for Embodied Pretraining
- [논문리뷰] EgoCS-400K: An Egocentric Gameplay Dataset for World Models
- [논문리뷰] EgoPhys: Learning Generalizable Physics Models of Deformable Objects from Egocentric Video
- [논문리뷰] OVO-S-Bench: A Hierarchical Benchmark for Streaming Spatial Intelligence in Multimodal LLMs
- [논문리뷰] Benchmarking Composed Image Retrieval for Applied Earth Observation
Review 의 다른글
- 이전글 [논문리뷰] RepFusion: Leveraging Multimodal Priors for Denoising in Representation Space
- 현재글 : [논문리뷰] Rethinking RAG in Long Videos: What to Retrieve and How to Use It?
- 다음글 [논문리뷰] RhymeFlow: Training-Free Acceleration for Video Generation with Asynchronous Denoising Flow Scheduling
댓글