[논문리뷰] The Surprising Effectiveness of Video Diffusion Models for Hand Motion Reconstruction
링크: 논문 PDF로 바로 열기
저자: Yuxi Wang, Chengkai Jin, Yufei Liu, Wenqi Ouyang, Tianyi Wei, Zhiwei Zeng, Siyuan Huang, Zhiqi Shen, Xingang Pan
1. Key Terms & Definitions (핵심 용어 및 정의)
- ViDiHand: 본 논문에서 제안하는, Pretrained Video Diffusion Model을 활용하여 4D 양손(two-hand) 모션을 재구성하는 프레임워크입니다.
- Hand-overlay Rendering: 비디오 모델의 World Prior를 보존하면서 손(Hand) 영역에 특화된 피처를 학습시키기 위해, 반투명한 손 메쉬를 영상 프레임에 합성하여 재구성하는 적응형 학습 목표(Adaptation target)입니다.
- Dual-Branch Hand Decoder: Articulated MANO 포즈를 위한 Hand-token Branch와 이미지 평면 좌표를 위한 Joint-heatmap Branch로 구성된 디코더 구조입니다.
- MANO: 손의 3D 포즈와 형상을 파라미터화하는 표준 모델입니다.
- Penalty Protocol: 은닉(Occlusion)된 손까지 고려하여 모델의 재구성 성능을 엄격하게 평가하는 프로토콜입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 egocentric 4D 손 모션 재구성 방법론이 직면한 심각한 병목 현상을 해결하고자 합니다. 기존 방식들은 이미지 기반 탐지기(Detector)에 의존하거나, 제한된 데이터로 학습된 시간적 모듈을 사용하여 심한 은닉 상황에서 성능이 저하되는 한계가 있습니다 [Figure 1]. 저자들은 이러한 4D 재구성이 요구하는 시간적 일관성, 기하학적 이해, 은닉 상황에서의 추론 능력이 대규모로 학습된 Video Diffusion Model 내부에 이미 존재한다는 점에 주목합니다. 따라서 외부 탐지기나 별도의 모션 채워넣기(Infiller) 과정 없이, 생성 모델의 표현력을 직접 활용하여 더욱 견고한 재구성을 달성하고자 합니다.
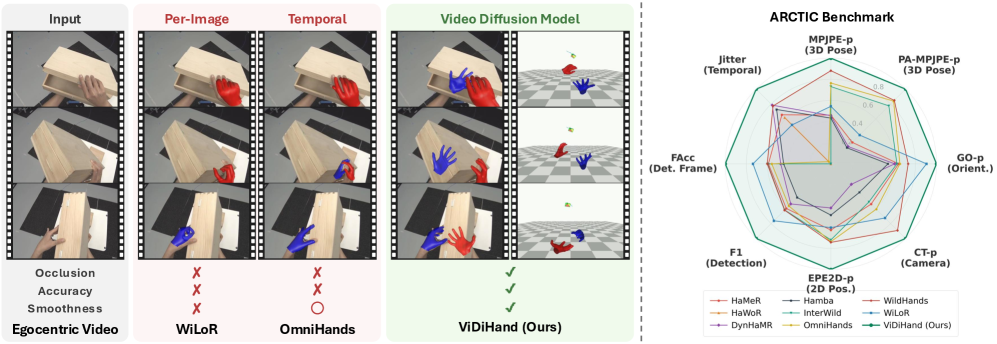
Figure 1 — 4D 손 복원 성능 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Wan2.1-VACE 백본을 기반으로 하는 ViDiHand 파이프라인을 제안하며, 이는 Hand-overlay Rendering을 통해 적응(Finetuning)됩니다 [Figure 2]. Dual-Branch Hand Decoder는 손의 포즈와 2D 위치 정보를 구조적으로 분리하여 처리하고, 상호 교차 주의(Mutual Cross-Attention) 레이어를 통해 이를 결합합니다. 카메라 변환(Camera Translation)은 깊이(Depth)를 직접 추론하고, 나머지 평면 이동은 닫힌 형식(Closed-form)의 최소 자승법으로 해결하여 기하학적 일관성을 확보합니다. ARCTIC 데이터셋에서 실험한 결과, ViDiHand는 기존 최신(SOTA) 방법론 대비 프레임 정확도(FAcc)를 0.997까지 끌어올렸으며, 이는 기존 최고 성능 모델인 WiLoR 대비 오류율을 약 27배 감소시킨 수치입니다. 또한 예측 지터(Jitter) 수치에서도 3.18 mm/frame²를 기록하며, 복잡한 인필러나 테스트 타임 최적화 없이도 기존 대비 약 4배 이상의 시간적 매끄러움을 달성했습니다 [Table 1].
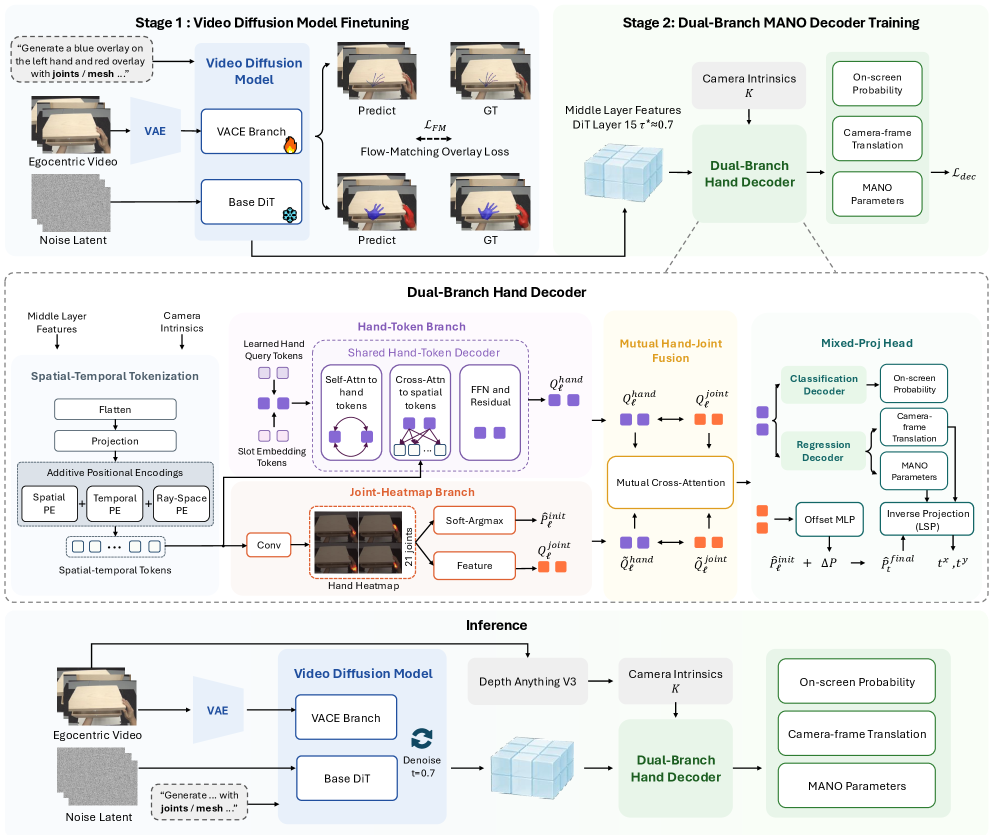
Figure 2 — ViDiHand 전체 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 논문은 대규모 Video Diffusion Model이 4D 손 모션 재구성을 위한 강력한 기초 모델이 될 수 있음을 입증하며 새로운 패러다임을 제시했습니다. 연구 결과는 생성 모델의 풍부한 시각적 우선순위가 특정 작업에 국한되지 않고 하위 지각 과제(Perception Task)로 성공적으로 전이될 수 있음을 시사합니다. 이러한 접근은 향후 Embodied AI를 위한 대규모 데이터 수집과 로봇 학습 환경에서 손 모션 추적의 정확도와 신뢰성을 크게 향상시킬 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] HumanScale: Egocentric Human Video Can Outperform Real-Robot Data for Embodied Pretraining
- [논문리뷰] EgoCS-400K: An Egocentric Gameplay Dataset for World Models
- [논문리뷰] VGGRPO: Towards World-Consistent Video Generation with 4D Latent Reward
- [논문리뷰] ArtHOI: Articulated Human-Object Interaction Synthesis by 4D Reconstruction from Video Priors
- [논문리뷰] EmbodMocap: In-the-Wild 4D Human-Scene Reconstruction for Embodied Agents
Review 의 다른글
- 이전글 [논문리뷰] TUA-Bench: A Benchmark for General-Purpose Terminal-Use Agents
- 현재글 : [논문리뷰] The Surprising Effectiveness of Video Diffusion Models for Hand Motion Reconstruction
- 다음글 [논문리뷰] TheoremGraph: Bridging Formal and Informal Mathematics
댓글