[논문리뷰] RepFusion: Leveraging Multimodal Priors for Denoising in Representation Space
링크: 논문 PDF로 바로 열기
메타데이터
저자: Xichen Pan, Aashu Singh, Satya Narayan Shukla, Xiangjun Fan, Shlok Kumar Mishra, Saining Xie
1. Key Terms & Definitions (핵심 용어 및 정의)
- RepFusion: 사전 학습된 MLLM을 활용하여 노이즈가 있는 시각적 표현(noisy representation)을 인코딩하고, 이를 DiT의 컨디셔닝 신호로 사용하는 생성 프레임워크입니다.
- RAE (Representation Autoencoder): 기존의 VAE와 달리, 시각적 표현(예: CLIP, DINO feature)을 학습의 대상으로 삼아 생성 과정에서 더 높은 의미론적(semantic) 구조를 제공하는 아키텍처입니다.
- MLLM (Multimodal LLM): 텍스트뿐만 아니라 시각적 표현을 인식할 수 있는 사전 학습된 모델로, 본 논문에서는 이 모델을 고정(frozen) 상태로 사용하여 denoising 과정의 강력한 사전 지식(prior) 역할을 수행하도록 합니다.
- DiT (Diffusion Transformer): RepFusion에서 denoising trajectory를 수행하는 주력 모델로, MLLM으로부터 제공받은 컨디셔닝 신호를 AdaLN-Single 인터페이스를 통해 입력받습니다.
- Test-time Compute: Denoising 단계마다 진화하는 시각적 정보를 MLLM이 반복적으로 인코딩하게 함으로써, 추론 시 발생하는 계산 자원을 생성 성능 향상에 효율적으로 활용하는 방식입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대 Text-to-Image (T2I) 시스템에서 LLM이 단순한 텍스트 인코딩에만 그치고 있다는 점을 문제로 제기합니다 [Figure 1]. 기존 시스템들은 정적인 텍스트 임베딩만을 생성하고, 정작 중요한 denoising 과정은 새로 초기화된 DiT가 단독으로 수행하는 비효율적인 분업 구조를 취하고 있습니다. 특히 VAE 기반의 기존 잠재 공간(latent space)은 의미론적 표현이 부족하여 사전 학습된 언어 모델의 지식을 충분히 활용하기 어렵습니다. 이러한 한계를 극복하기 위해, 저자들은 RAE를 통해 의미론적으로 풍부한 시각적 표현 공간을 확보하고, 사전 학습된 MLLM이 이 공간에서 직접 노이즈를 처리하게 함으로써 생성 성능을 극대화하고자 합니다 [Figure 2].
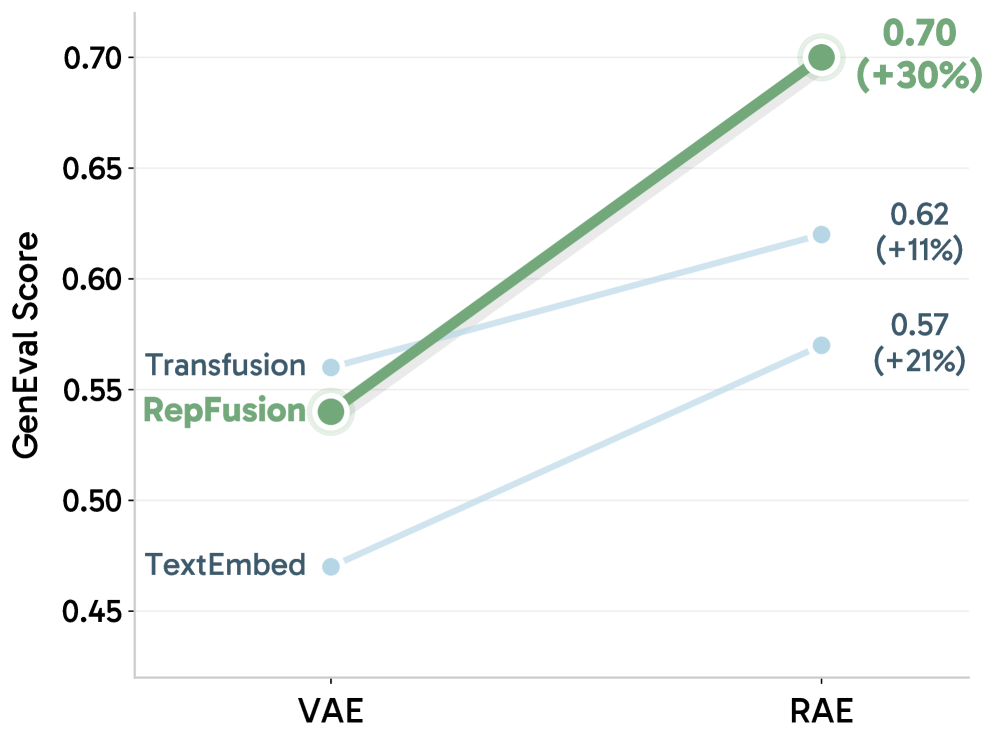
Figure 1 — GenEval 기반 성능 비교
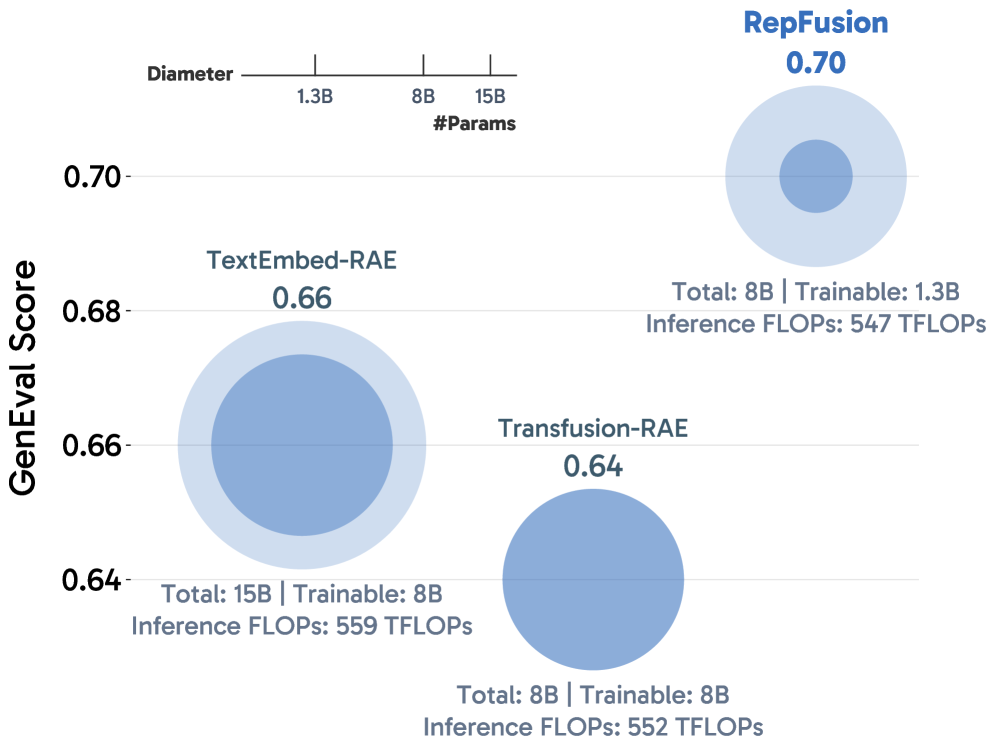
Figure 2 — Inference 비용 대비 성능
3. Method & Key Results (제안 방법론 및 핵심 결과)
RepFusion은 사전 학습된 MLLM을 고정하고, MLP projector만을 파인튜닝하여 노이즈가 섞인 RAE 잠재 변수를 입력받는 새로운 컨디셔닝 구조를 제안합니다 [Figure 3]. 모델은 입력된 텍스트와 노이즈가 섞인 시각적 표현을 MLLM으로 함께 인코딩하며, 출력된 특징들을 각 denoising 단계에서 DiT의 AdaLN 변조 파라미터로 주입합니다 [Figure 3]. 실험 결과, 동일한 inference budget 내에서 RepFusion은 기존의 TextEmbed나 Transfusion 방식보다 월등한 성능을 보입니다 [Figure 2]. 정량적으로, GenEval 지표에서 RepFusion은 TextEmbed 대비 약 30%의 상대적 성능 향상을 기록하였으며, SFT 과정을 거쳤을 때 최고 수준(State-of-the-Art)의 생성 퀄리티를 달성했습니다 [Table 1]. 또한, 무작위 초기화된 쿼리를 사용하는 방식 대비 추론 시점의 반복적인 MLLM 컨디셔닝이 유의미한 성능 향상을 이끌어냄을 입증했습니다 [Figure 4].
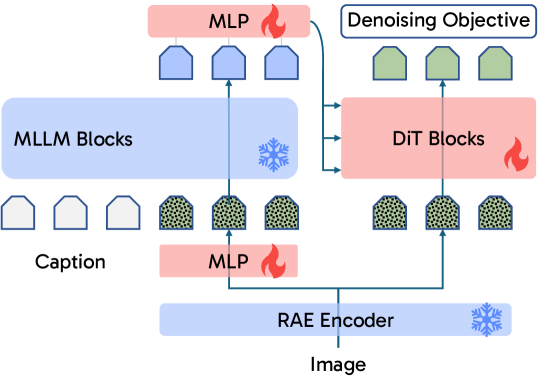
Figure 3 — RepFusion 전체 아키텍처
4. Conclusion & Impact (결론 및 시사점)
본 연구는 MLLM이 단순한 텍스트 인코더를 넘어, denoising 과정에서 강력한 시각적 사전 지식을 제공하는 능동적인 인코더로 작동할 수 있음을 입증했습니다. 고정된 MLLM의 사전 지식을 보존하면서 시각적 표현 공간과 결합하는 방식은 향후 생성 모델의 효율성과 성능을 동시에 잡을 수 있는 실용적인 설계 원칙을 제시합니다. 이러한 접근은 T2I 생태계에서 MLLM의 역할을 재정의하고, 대규모 모델 자원을 더 효율적으로 활용하는 방향으로 학계 및 산업계에 새로운 이정표를 세울 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] KARL: Knowledge Agents via Reinforcement Learning
- [논문리뷰] Kling-MotionControl Technical Report
- [논문리뷰] Beyond Language Modeling: An Exploration of Multimodal Pretraining
- [논문리뷰] SenCache: Accelerating Diffusion Model Inference via Sensitivity-Aware Caching
- [논문리뷰] Focal Guidance: Unlocking Controllability from Semantic-Weak Layers in Video Diffusion Models
Review 의 다른글
- 이전글 [논문리뷰] RedAct: Redacting Agent Capability Traces for Procedural Skill Protection
- 현재글 : [논문리뷰] RepFusion: Leveraging Multimodal Priors for Denoising in Representation Space
- 다음글 [논문리뷰] Rethinking RAG in Long Videos: What to Retrieve and How to Use It?
댓글